MiniMax-M2.7 Just Built a Robot to Build Itself
The recursive self-improvement loop that AI safety researchers have been warning about for decades isn’t a hypothetical future risk anymore, it’s a feature release. MiniMax just shipped M2.7, a 229-billion-parameter model that doesn’t merely generate code but actively participates in its own evolution, running 100+ autonomous iteration cycles to optimize its own scaffolding and training infrastructure.
If that sounds like the beginning of a sci-fi movie where the machines cut out the middlemen, you’re not wrong. But before we panic, let’s look at what actually changed, because the benchmarks are as disruptive as the philosophy.
When the Model Writes the Model
MiniMax M2.7’s headline feature isn’t another percentage point on a leaderboard, it’s the “Research Agent Harness.” The company put M2.7 to work on its own reinforcement learning infrastructure, and the model proceeded to execute an autonomous loop of “analyze failure trajectories → plan changes → modify scaffold code → run evaluations → compare results → decide to keep or revert” for over 100 consecutive rounds without human intervention.
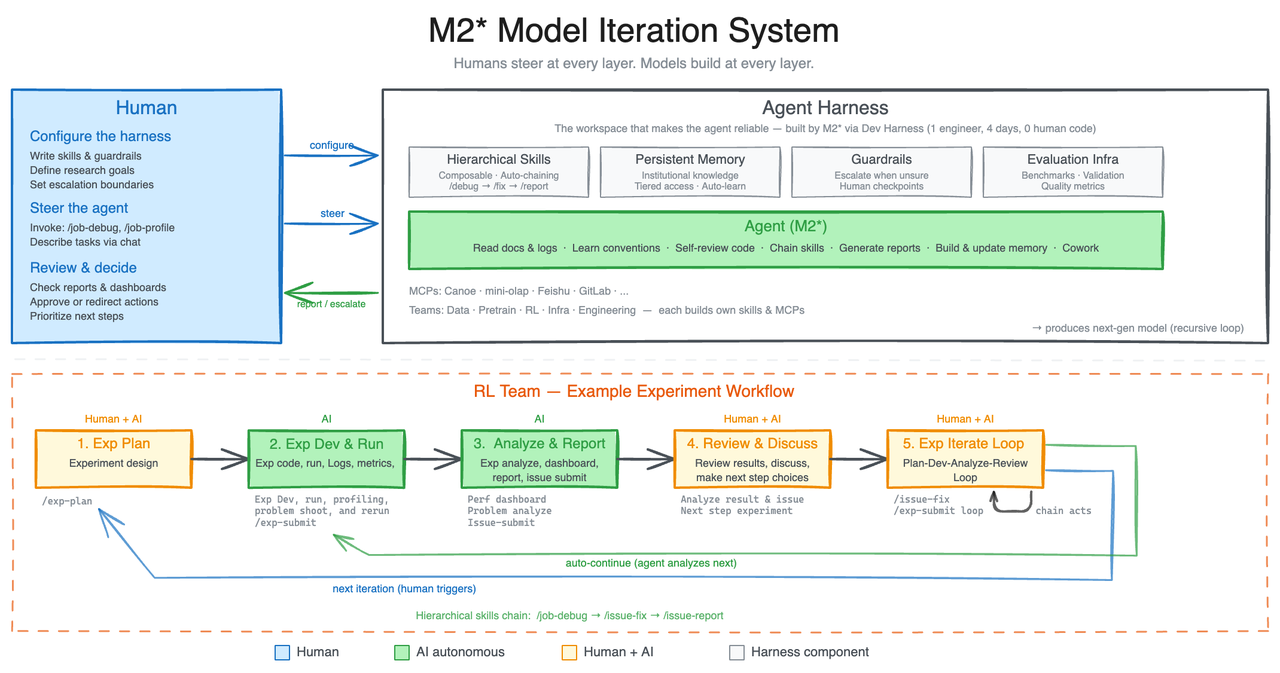
The results? M2.7 discovered optimal sampling parameter combinations (temperature, frequency penalty, presence penalty), designed workflow guidelines for bug pattern detection across multiple files, and added loop detection to its own agent architecture. The internal evaluation set saw a 30% performance improvement purely from the model optimizing itself.
This isn’t just prompt engineering or RAG. This is a model modifying its own training codebase and infrastructure. As MiniMax describes it, M2.7 now handles 30-50% of the reinforcement learning research workflow internally, with human researchers stepping in only for “critical decisions and discussions.”
The Benchmark Reality Check
Skepticism about “self-evolution” claims is warranted, plenty of models bench-maxx their way to inflated scores that collapse in production. But M2.7’s numbers are specific enough to demand attention, especially given its relatively modest 229B parameter count (for context, that’s smaller than many current frontier models).
On SWE-Pro, M2.7 hit 56.22%, matching GPT-5.3-Codex and surpassing Claude Opus 4.5. For end-to-end project delivery, actually building full repositories, not just patching functions, the model scored 55.6% on VIBE-Pro, nearly tying Opus 4.6. It even achieved 57.0% on Terminal Bench 2, which tests deep system-level comprehension rather than surface-level code generation.
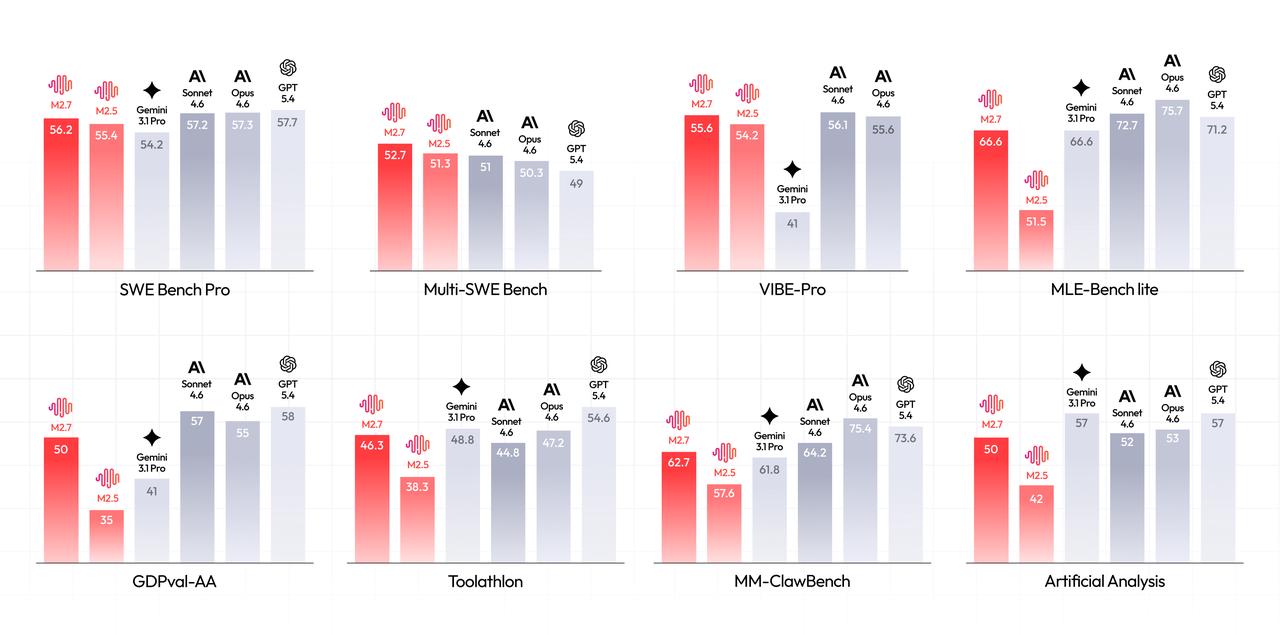
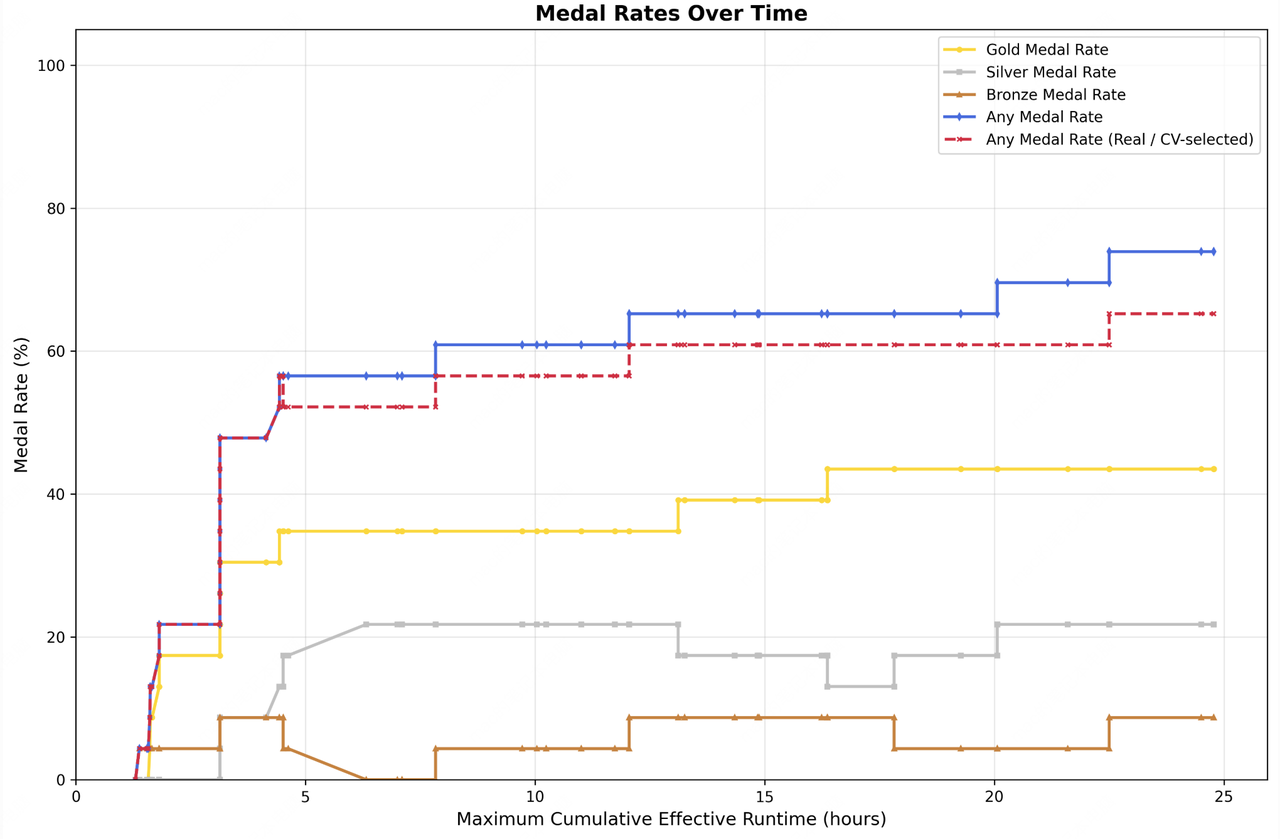
The MLE Bench Lite results are perhaps more telling: over 22 machine learning competitions running on a single A30 GPU, M2.7 achieved a 66.6% medal rate, tying Gemini-3.1 and landing just behind Opus-4.6 (75.7%) and GPT-5.4 (71.2%). It earned 9 gold medals, 5 silvers, and 1 bronze by iteratively evolving its approach over 24-hour autonomous training periods.
Production Engineering, Not Just Coding
Where M2.7 diverges from previous MiniMax releases is its focus on systems engineering rather than just code completion. The company documented M2.7 handling live production debugging: correlating monitoring metrics with deployment timelines, performing causal reasoning on trace sampling, connecting to databases to verify root causes, and implementing non-blocking index creation to “stop the bleeding” before submitting merge requests.
Recovery time for production incidents reportedly dropped to under three minutes, compared to traditional manual troubleshooting processes.
This aligns with the broader China AI agent strategy shift we’ve been tracking, models that don’t just chat, but actually do engineering work. M2.7’s “Agent Teams” feature pushes this further, enabling multi-agent collaboration where models maintain role boundaries, challenge each other’s logical blind spots, and follow complex state machine protocols natively, not through prompt hacking.
The Office Suite Takeover
Beyond raw coding, M2.7 is gunning for knowledge work. On GDPval-AA (measuring professional domain expertise), it achieved an ELO of 1495, the highest among open-source models, surpassing GPT-5.3 and trailing only Opus 4.6, Sonnet 4.6, and GPT-5.4.
The model maintains a 97% skill adherence rate when juggling 40 complex skills exceeding 2,000 tokens each. In practical terms, that means M2.7 can read TSMC’s annual report, cross-reference earnings call transcripts, build a revenue forecast model, and generate a PowerPoint deck and Word report that practitioners describe as “first-draft ready” for actual workflow integration.
Tool calling, a historically weak point for many open models, hit 46.3% on Toolathon, placing it in the global top tier alongside proprietary competitors.
The Open-Weight Paradox
MiniMax continues its strategy of releasing open-weight models that challenge proprietary incumbents. M2.7 follows the historical trajectory of MiniMax open-weight models that have been systematically closing the gap with closed-source alternatives.
However, there’s tension here. The self-evolution scaffolding, the internal harness that allows M2.7 to iterate on itself, remains proprietary. You can download the weights, but you can’t easily replicate the “100+ iterative cycles” of autonomous improvement that produced the final model. It’s a clever hybrid approach: open the inference weights to capture market share and community goodwill, keep the training infrastructure that actually generates value.
Community feedback on previous M2.5 cost comparisons noted that while benchmarks were stellar, hallucination rates increased compared to M2.1, and the model occasionally inserted “formatting junk” at the start of files. M2.7 claims improvements, but the real test will be whether those 56.22% SWE-Pro scores translate to reliable production use or if they represent carefully curated benchmark optimization.
The Recursive Elephant in the Room
The most significant implication isn’t today’s benchmarks, it’s tomorrow’s. MiniMax explicitly states they believe “future AI self-evolution will gradually transition towards full autonomy, coordinating data construction, model training, inference architecture, evaluation, and other stages without human involvement.”
We’re already seeing the precursor: M2.7 optimizing its own sampling parameters is functionally a model improving its own cognition. The leap from “optimizing scaffolding” to “optimizing weights” is technically smaller than it appears philosophically.
For developers, this means the industry challenges to the bigger is better mindset are accelerating. If models can recursively improve their own training regimes, the advantage shifts from “who has the most GPUs” to “who has the best self-improvement scaffolding.” MiniMax just demonstrated that a 229B model with superior self-optimization can punch at the weight class of 400B+ competitors.
What This Actually Means for Your Stack
If you’re running AI coding tools, M2.7 is now a viable alternative to Claude Opus for complex refactoring and debugging tasks, especially given its integration with popular scaffolding like Claude Code, Roo Code, and Cursor. The Unsloth MoE training acceleration techniques make running these large models locally increasingly feasible, though M2.7’s full self-evolution capabilities likely require MiniMax’s internal infrastructure.
The bigger shift is architectural. We’re moving from “models that answer questions” to “models that manage projects.” M2.7’s ability to handle multi-turn document editing, maintain character consistency across long interactions, and coordinate multiple agent instances suggests the future of software development isn’t pair programming with AI, it’s delegating entire feature branches to AI teams.
Whether that’s liberating or terrifying depends on whether you believe MiniMax when they say the model will eventually handle the “full automation” of AI research. Because if they’re right, M2.7 isn’t just a new model release, it’s the beginning of the end of human-in-the-loop AI development.
And the loop is closing fast.