MiniMax M2.7: The Self-Evolving Coding Beast You Can’t Actually Use
MiniMax just dropped M2.7, a 229-billion-parameter coding agent that helped build itself through recursive self-improvement, achieving a 66.6% medal rate on MLE Bench Lite and matching GPT-5.3-Codex on SWE-Pro. The catch? Using it for anything other than hobbyist experimentation requires written permission from MiniMax, a display badge reading “Built with MiniMax M2.7”, and a legal review of whether your use case qualifies as “commercial advantage.”
The local LLM community is calling it the ultimate bait-and-switch: open weights with a closed license that treats commercial use as a derivative sin. After the trust erosion of previous MiniMax releases, M2.7 represents not a gift to the open-source ecosystem, but a carefully calculated product demo wrapped in legal ambiguity.

When “Open Weights” Means “Look But Don’t Touch”
MiniMax M2.7 arrives with impressive technical credentials. It is a sparse Mixture-of-Experts (MoE) model with 256 local experts (8 active per token), 204,800-token context window, and native support for Agent Teams that maintain stable role identity across multi-agent workflows. During training, an internal version of the model autonomously optimized its own programming scaffold over 100+ rounds, analyzing failure trajectories, modifying code, and deciding what to keep or revert, resulting in a 30% performance improvement with no human intervention.
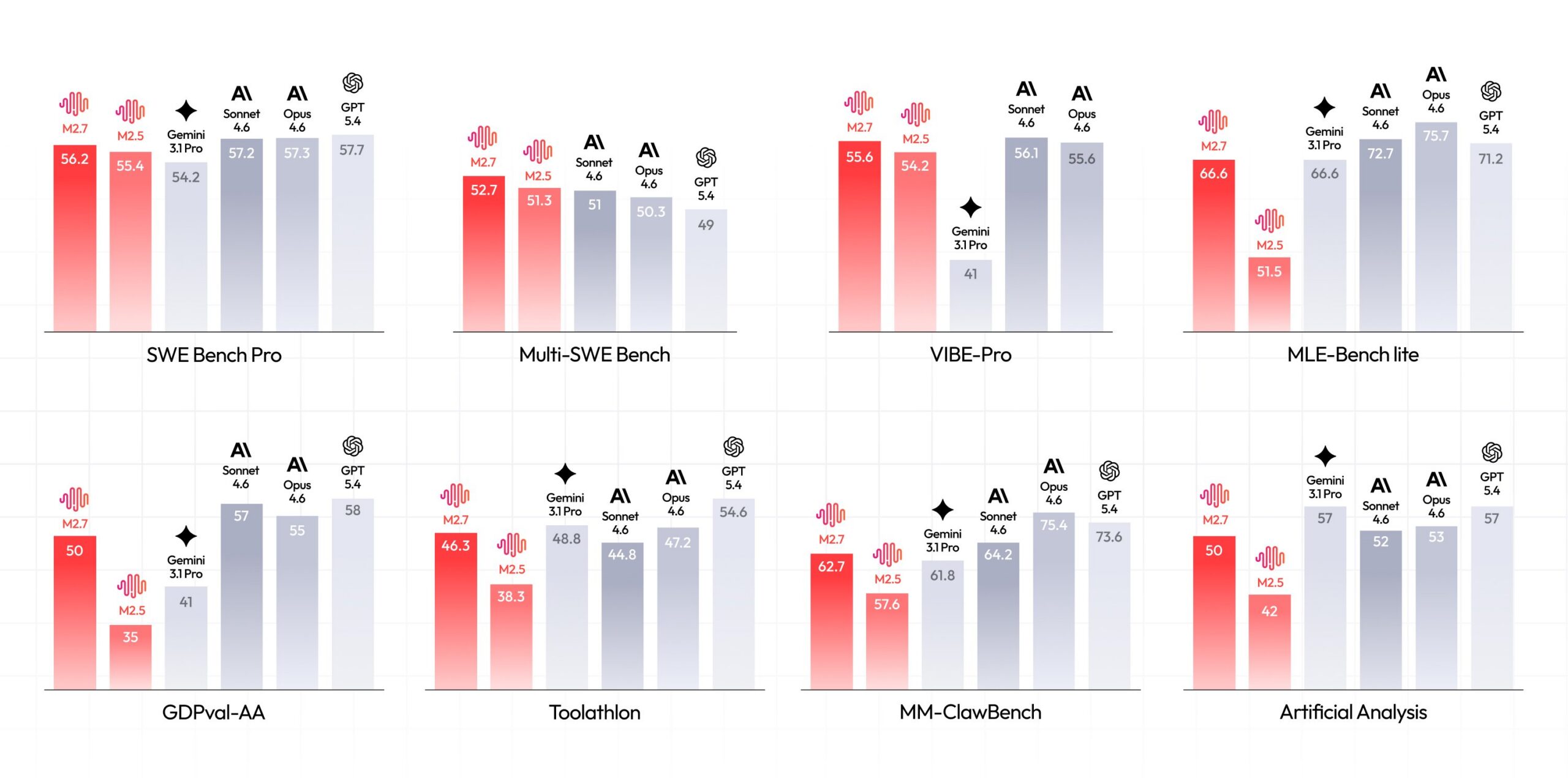
The benchmarks are genuinely competitive with frontier closed models:
| Benchmark | Score | Context |
|---|---|---|
| SWE-Pro | 56.22% | Matches GPT-5.3-Codex |
| VIBE-Pro | 55.6% | Near Opus 4.6 performance |
| GDPval-AA | 1495 ELO | Highest among open-source models |
| Terminal Bench 2 | 57.0% | Complex systems understanding |
| MLE Bench Lite | 66.6% medal rate | 2nd only to Opus-4.6 and GPT-5.4 |
But the license text tells a different story than the HuggingFace download button. Section 4 of the Modified MIT License defines “Commercial Use” so broadly it captures virtually any deployment that might generate value: “offering products or services to third parties for a fee”, “commercial use of APIs”, or deploying fine-tuned versions “for any commercial purpose.”
The requirements are explicit: commercial use requires “prior written authorization” via email to api@minimax.io, plus prominent display of the “Built with MiniMax M2.7” attribution. Military use is categorically prohibited. For developers building production systems, this isn’t open source, it’s a freemium trial with undefined pricing.
The Hardware Taxonomy of Disappointment
Even if you accept the legal constraints, running M2.7 locally requires hardware that would make a rendering farm blush. Unsloth has released GGUF quants ranging from 1-bit to BF16, revealing the brutal memory reality:
| Quantization | Size | Use Case |
|---|---|---|
| UD-IQ1_M | 60.7 GB | Minimum viable, quality loss |
| UD-Q4_K_M | 140 GB | Balanced quality |
| UD-Q6_K_XL | 207 GB | High fidelity |
| BF16 | 457 GB | Original quality |
The 1-bit quant alone exceeds the VRAM of most consumer GPUs, requiring users to follow the precedent set by MiniMax-2.5 and run aggressive quantization on massive RAM setups. Community reports indicate that even with 128GB unified memory, users struggle to max out the model’s context window. One developer noted that running the UD-Q6_K_XL quant with dual Strix Halo processors achieves approximately 15 tokens per second, usable for experimentation, but hardly production-ready for real-time applications.
There is also a specific technical landmine: CUDA 13.2 currently produces gibberish outputs with these quants due to compiler kernel bugs affecting IQ3/IQ4 and below. Users must stick to CUDA 12.x or specific patched builds to avoid corrupted generation.
The Community Verdict: DOA
Developer forums reacted to the license reveal with immediate hostility. Many declared the model “dead on arrival” for serious use, noting that the broad definition of “commercial advantage” effectively prohibits use within any business environment without legal clearance. The sentiment is that MiniMax has taken a page from the worst instincts of proprietary AI: release weights for marketing buzz and community testing, but retain absolute control over who can build a business with them.
Some defenders argue this is a necessary evolution. Cloud providers like Alibaba Cloud were reportedly offering MiniMax models (including previous versions like GLM-5 and MiniMax M2.7) as commercial APIs without authorization, eating into MiniMax’s revenue. The restrictive license appears designed to force commercial users into private licensing agreements rather than allowing third-party hosting.
However, the comparison to genuinely open alternatives stings. While Google’s Gemma 4 ships with clear, permissive terms and Meta continues (for now) to release Llama weights under acceptable use policies, MiniMax is carving out a middle ground that satisfies no one: too restricted for open-source purists, too uncontrolled for enterprise legal teams who need liability clarity.
The NVIDIA Escape Hatch
Interestingly, the licensing confusion multiplies depending on where you access the model. While the HuggingFace weights fall under MiniMax’s Modified MIT with commercial restrictions, NVIDIA’s NIM endpoint lists the model as governed by the NVIDIA Open Model License, which explicitly permits commercial use. This creates a bifurcated ecosystem where the same model architecture carries different legal obligations depending on whether you self-host or use NVIDIA’s API infrastructure.
For developers, this means the only safe path to commercial deployment may be through NVIDIA’s managed endpoints, exactly the kind of vendor lock-in that open weights were supposed to prevent.
What You’re Actually Allowed To Do
If you’re a researcher, student, or hobbyist experimenting with local LLM tools, M2.7 is genuinely accessible. The non-commercial clause permits modification, redistribution, and derivative works, as long as nobody pays for the result. You can fine-tune it, quantize it, and publish your findings.
But if you’re building a startup, integrating AI coding assistants into a SaaS product, or even using it to generate code for your company’s internal tools (which could be interpreted as “commercial advantage”), you are operating in a legal gray zone. The license text suggests that even evaluation within a business context requires authorization.
The practical implication is that M2.7 becomes a research curiosity rather than a foundation for innovation. In an era where distillation and open-weight transparency are driving the next wave of AI development, MiniMax has chosen to keep the crown jewels under glass, visible, impressive, and fundamentally untouchable.
MiniMax M2.7 represents a technical achievement that validates the self-evolution paradigm: models that improve themselves through iterative refinement are no longer theoretical. But it also represents a licensing regression that undermines the open-weight coup MiniMax helped start with earlier releases.
For the local LLM community, the message is clear: verify the license before you verify the benchmarks. A 229B-parameter model that codes at GPT-5.3 levels is worthless if using it exposes your company to IP litigation. Until MiniMax clarifies their commercial terms or adopts a standard open-source license like Apache 2.0, M2.7 remains a brilliant proof-of-concept that most developers should admire from a distance.
The weights are open. The license is closed. And the gap between them is where trust goes to die.