
The open-weight vs. closed-API cold war just escalated to a hot one. DeepSeek just pushed the “V4-Pro” and “V4-Flash” models to Hugging Face, and the specs read like a direct provocation: a 1.6 trillion parameter Mixture-of-Experts (MoE) model with 49 billion active, a leaner 284B/13B Flash variant, and a 1 million token context window for both. Crucially, they require only 27% of the single-token inference FLOPs and 10% of the KV cache compared to their predecessor, V3.2. This isn’t just another model drop. It’s an open-weights declaration that the era of paying for API compute overhead, and accepting vendor-controlled black boxes, is optional.
The real story isn’t the raw parameter count. It’s the efficiency. For agentic workflows, code generation, multi-step reasoning, long document analysis, context is everything, and the cost of using that context has been prohibitive. With V4-Pro’s hybrid attention architecture combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), running a 1M token context on comparable hardware no longer requires a venture capital-level budget.
This release underscores a strategic shift in the AI landscape, mirroring moves by other labs also challenging API lock-in scenarios. But DeepSeek’s open-weights gambit, backed by a massive 32T token pre-training corpus, raises the stakes for what “competitive” looks like.
The Specs That Actually Matter: Beyond the Trillion-Parameter Headline
Let’s cut past the hype. The release includes two core models, available now from DeepSeek’s official HuggingFace page:
- DeepSeek-V4-Pro: 1.6T total parameters, 49B activated per token, 1M context.
- DeepSeek-V4-Flash: 284B total parameters, 13B activated per token, 1M context.
Both models are Mixture-of-Experts. This MoE architecture is the key to their utility. The ~1.6 trillion parameters in the Pro model aren’t all used at once, only a routed subset (49B) are activated for any given token. This makes them far more practical to run than a dense model of similar total size. The models are released under an MIT license, and the instruct versions use a mixed FP4 (for MoE experts) and FP8 (for most other parameters) precision scheme.
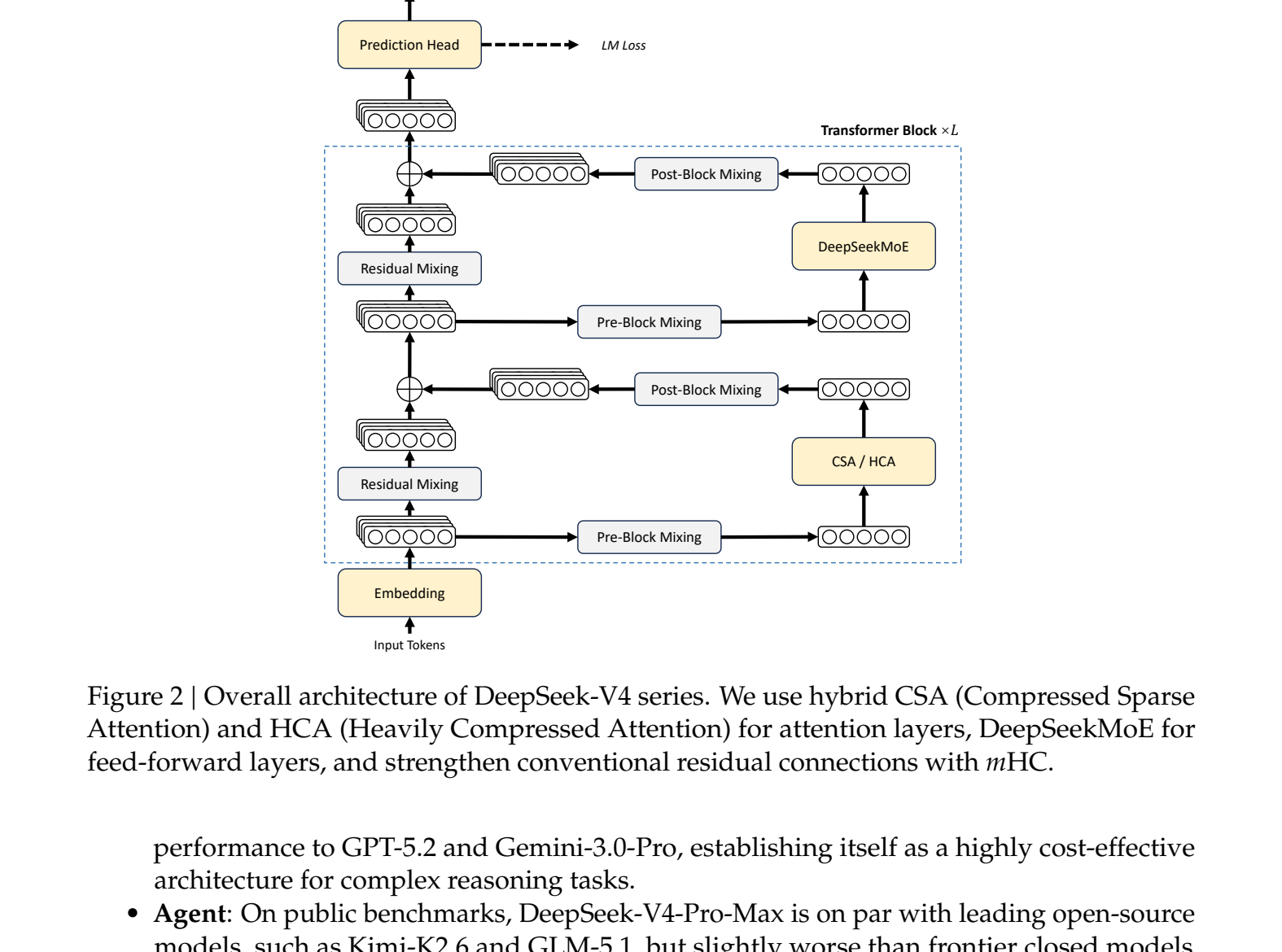
The breakthrough isn’t just having a long context window, it’s making it usable. For a 1M-token sequence, DeepSeek-V4-Pro uses only 10% of the KV cache memory of its predecessor. Compared to a standard architecture like grouped query attention with 8 heads (stored in bfloat16), V4 reportedly requires roughly 2% of the cache size. This isn’t an incremental improvement, it’s a fundamental re-engineering of the cost curve for long-context reasoning.
The official HuggingFace blog post details the architecture, and the technical report dives into the novel components.
How Hybrid Attention Makes a Million-Token Context Practical
The magic is in the alternating layers of Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). This isn’t just academic. For agentic coding tasks, think SWE-Bench where an agent might execute hundreds of tool calls, every tool result gets appended to the context. In a traditional model, the compute cost for each subsequent token balloons as it pays attention to this ever-growing history.
CSA compresses KV entries 4x using a softmax-gated pooling mechanism, then a lightweight “lightning indexer” (running in FP4) selects the most relevant compressed blocks for each query. HCA goes further, applying a 128x compression and then performing cheaper, dense attention over this massively shortened sequence.
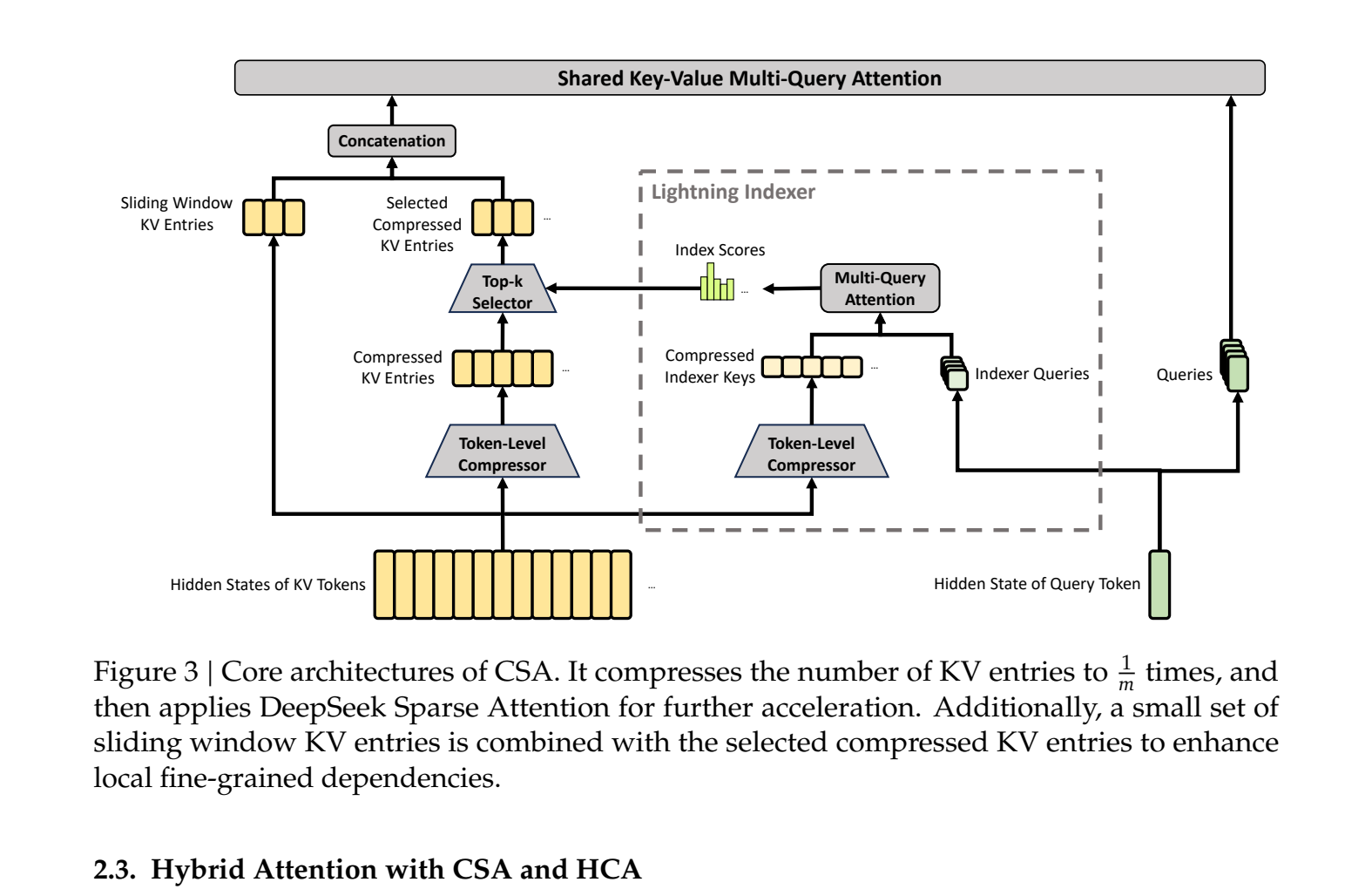
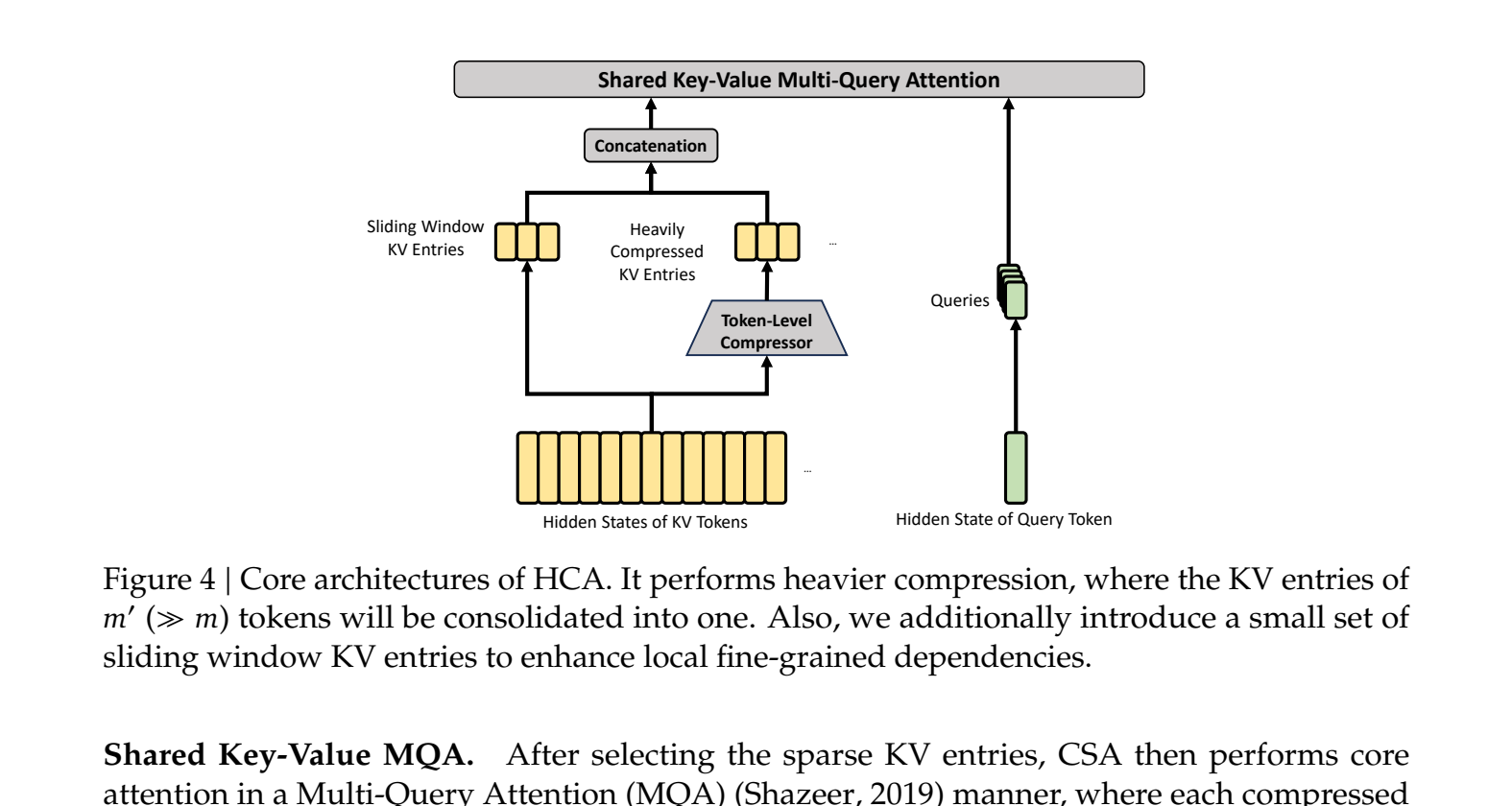
By alternating these layers, the model maintains both high-resolution, sparse access to recent tokens (via CSA) and a cheap, dense overview of the entire context (via HCA). This is the engineering that allows an agent to remember the plan it formulated 500,000 tokens ago without melting your GPU or your budget.
Benchmark Brawl: How Does V4 Actually Stack Up?
The marketing claims a model that “rivals the world’s top closed-source models.” The numbers provide a nuanced, but compelling, picture.
On standard knowledge and reasoning benchmarks like MMLU-Pro, V4-Pro-Max scores 87.5, trailing behind Gemini-3.1-Pro High (91.0) and GPT-5.4 xHigh (87.5 is a tie) but firmly ahead of other open-source contenders. Where it starts to pull away from the pack is in agentic and coding tasks.
In the official benchmark tables, V4-Pro-Max scores 80.6% on SWE Verified (tying Gemini-3.1-Pro and just a whisper behind Opus-4.6-Max’s 80.8%). It achieves a 93.5% pass rate on LiveCodeBench and a 3206 rating on Codeforces, both of which are top-tier results. It also posts a strong 67.9% on Terminal Bench 2.0, outperforming several frontier models.
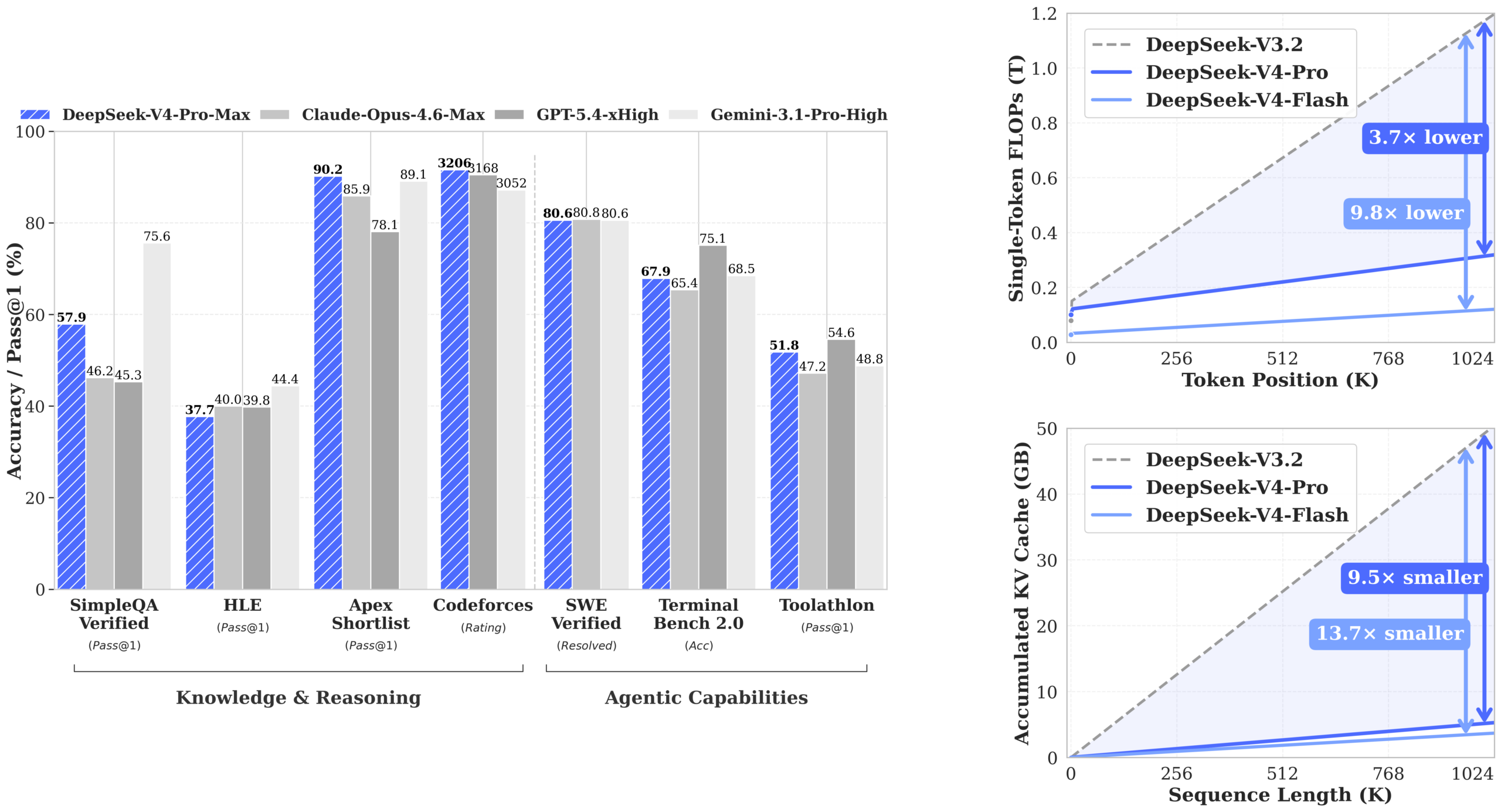
Perhaps more telling is the performance across its three reasoning modes: Non-think, Think High, and Think Max. The delta is stark. On the HLE (Human-Like Ethics) benchmark, V4-Pro jumps from a 7.7% pass rate in Non-think mode to 34.5% in Think High and 37.7% in Think Max. This configurability lets you dial in the cost/performance trade-off dynamically, a feature closed APIs rarely offer.
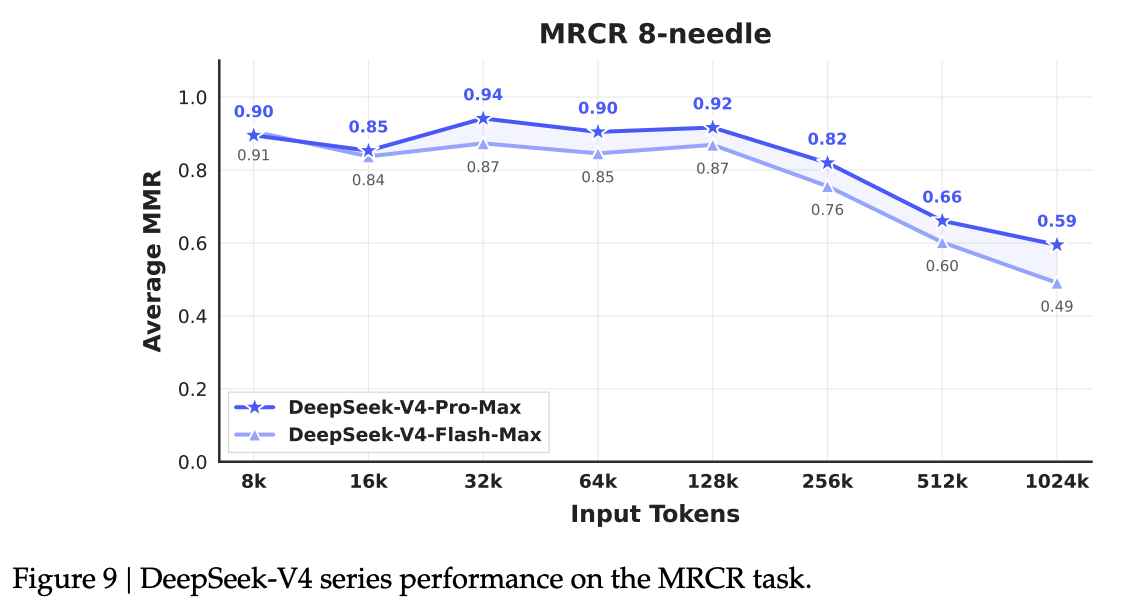
Long-context retrieval, the raison d’être for this architecture, is validated by the MRCR 8-needle test. V4-Pro-Max maintains an accuracy above 0.82 through 256K tokens and still holds at 0.59 at the full 1M token mark.
The Hardware Reality: Can You Actually Run This?
This is where the community’s excitement meets the cold reality of RAM prices. The Pro model’s weights are ~900GB. The Flash model is a more approachable, but still hefty, ~160GB. As one developer lamented on Reddit, “I think this is the most annoyed I’ve ever been at myself for not going overboard with RAM when I was putting my machine together.”.
- V4-Flash (158GB): Might be squeezable onto a high-end consumer rig with 128GB RAM + GPU offloading, especially with aggressive quantization. Community discussions suggest IQ4XS or Q3KXL quants could make it usable.
- V4-Pro (862GB): This is datacenter territory. You’re looking at multi-GPU server setups or cloud instances with hundreds of GBs of VRAM.
For comparison, competitors like Qwen 3.6 have pushed the efficiency frontier with models that activate only 3B parameters per token. The hardware requirement for V4-Pro exposes the ongoing tension in “open-weight” AI: true democratization versus the hardware realities for massive open-parameter models. While Flash is more accessible, the Pro variant reinforces that the frontier of capability still sits behind a significant infrastructure moat.
A Built-for-Agents Philosophy
Beyond the raw efficiency numbers, DeepSeek V4 shows a clear design philosophy centered on practical agent use. Three post-training features stand out:
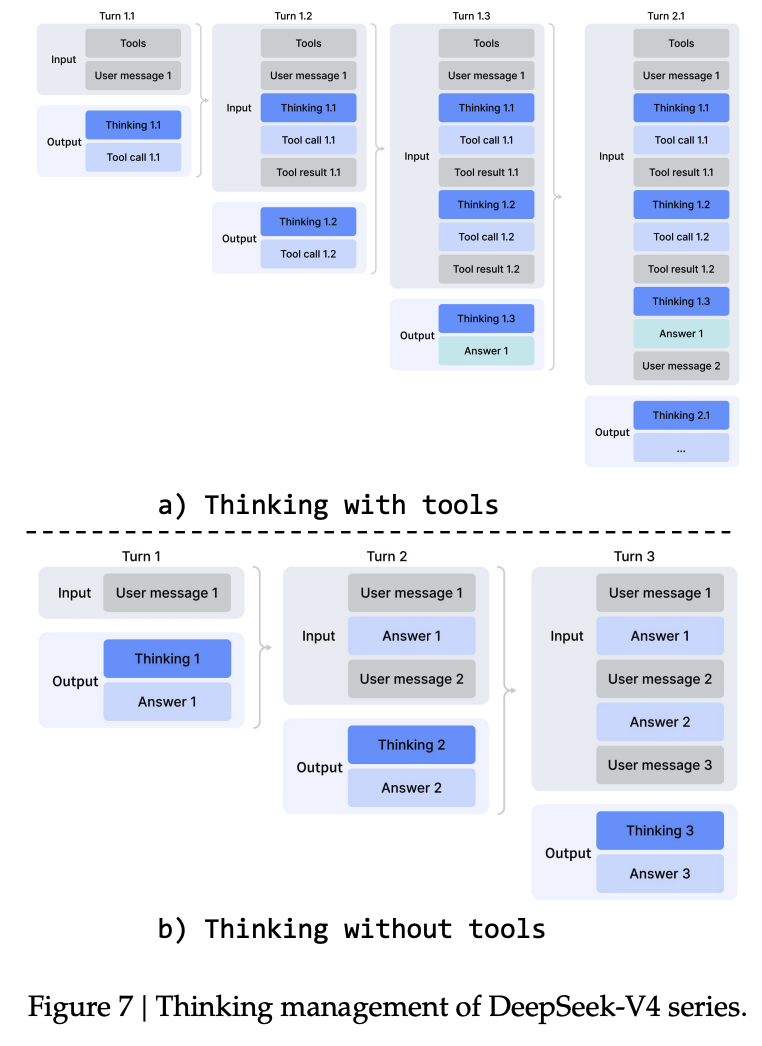
- Interleaved Thinking Across Tool Calls: Unlike V3.2, which discarded reasoning traces at each new user message, V4 preserves the full chain of thought across all turns when tools are involved. This is critical for long-horizon tasks where an agent must maintain state across a complex user dialogue.
- Dedicated Tool-Call Schema: V4 introduces a
|DSML|token and an XML-based format for tool calls, explicitly separating string and structured parameters to reduce JSON parsing failures, a common agent failure mode. - The DSec Sandbox: The paper describes “DeepSeek Elastic Compute”, a Rust-based platform for running hundreds of thousands of concurrent sandboxes (functions, containers, microVMs). This infrastructure allowed training via RL against real tool environments, which shows in the strong agent benchmark scores.
The Implication: A New Calculus for Closed vs. Open
The release of DeepSeek V4, alongside other powerful open-weights from Google (Gemma 4), Alibaba (Qwen), and Zhipu AI (GLM-5.1), changes the strategic landscape.
Closed API providers (OpenAI, Anthropic) have traditionally competed on three axes: performance, ease-of-use, and reliability. The performance gap, as demonstrated by V4’s agentic scores, is narrowing dramatically on specific, valuable tasks like coding. Ease-of-use is being rapidly tackled by projects like Ollama and vLLM for local inference.
This leaves reliability and the total cost of ownership as the main battlegrounds. Running your own 900GB model isn’t “easy.” But for organizations where data sovereignty is non-negotiable (healthcare, finance, defense), where API costs at scale are untenable, or where the economic sustainability of closed providers is in question, the calculus is shifting.
As noted in an external analysis, “API costs compound fast at scale. A team making 100K requests/day to Claude Opus 4.6 at $15/MTok input can spend $45K+/month. Self-hosting a comparable open model on 4x A100s costs roughly $8-12K/month on AWS, and the cost is fixed regardless of volume.”.
DeepSeek’s commitment to technical transparency, evidenced by the detailed technical report and immediate open-weight release, stands in stark contrast to the opaque, version-controlled APIs of the West. It’s a different go-to-market strategy: compete on absolute capability and openness, and let the ecosystem figure out the deployment.
The Bottom Line
DeepSeek V4 isn’t just a model, it’s a statement. It proves that frontier-level agentic performance, coupled with revolutionary context efficiency, can be packaged in an open-weight form. It won’t run on your laptop, but the Flash variant might run in your small cluster. It won’t depose GPT-5 tomorrow, but it provides a viable, sovereign, and potentially cheaper path for organizations needing state-of-the-art code generation and long-context reasoning.
The question is no longer if open-weight models can challenge closed APIs, but which organizations will be the first to build their competitive advantage on top of them, and what new tools will emerge to tame their hardware realities for massive open-parameter models. The cannon is loaded and sitting on HuggingFace. It’s up to the community to aim it.



