
Google’s DeepMind team just merged a Pull Request titled “casually dropping the most capable open weights on the planet” with 14 co-authors including Jeff Dean. No keynote. No sizzle reel. Just 9,896 lines of code and a model card that suggests we’ve been thinking about local AI all wrong. Gemma 4 isn’t merely an incremental update, it’s a fundamental reimagining of what open-weight models can do when you stop counting parameters and start counting activated parameters.
The headline isn’t just that Gemma 4 runs natively on your phone (though it does). It’s not merely that it processes text, vision, and audio without bolted-on adapters (though it does that too). The real story is architectural: Google finally built a sparse Mixture-of-Experts (MoE) system that doesn’t require a data center’s worth of VRAM to run inference, paired with a licensing shift to Apache 2.0 that actually lets you ship products without legal anxiety.
The License Reversal: From “Open-ish” to Actually Open
Let’s address the elephant in the room first. Previous Gemma releases operated under Google’s proprietary Gemma Terms of Use, a license that let you download and tinker but kept Google holding the leash on redistribution and commercial use. It was “open” in the same way a museum is open: look, but don’t touch the art.
Gemma 4 changes the game entirely. The weights now ship under Apache 2.0, which means you can modify, redistribute, and commercialize without royalty obligations. The only constraints are standard attribution and a clever patent clause: sue Google claiming the model infringes your patents, and you automatically lose your license. It’s the kind of legal hygiene that lets enterprises actually deploy without having their general counsel wake up in cold sweats.
This matters because the previous “open but not open-source” approach was quietly throttling adoption. Now, with true Apache 2.0 licensing, we’re likely to see Gemma 4 bundled into hardware firmware, embedded in industrial IoT, and distributed through app stores without the friction of license compliance audits.
The 26B-A4B MoE: When 4 Billion Parameters Outperform 30 Billion
The crown jewel of this release is the 26B-A4B variant, a sparse MoE model with 25.2 billion total parameters but only 3.8 billion active during inference (15.1% activation). If you’re doing the math, that means you’re getting 26B-scale model quality at roughly 4B-scale inference costs.
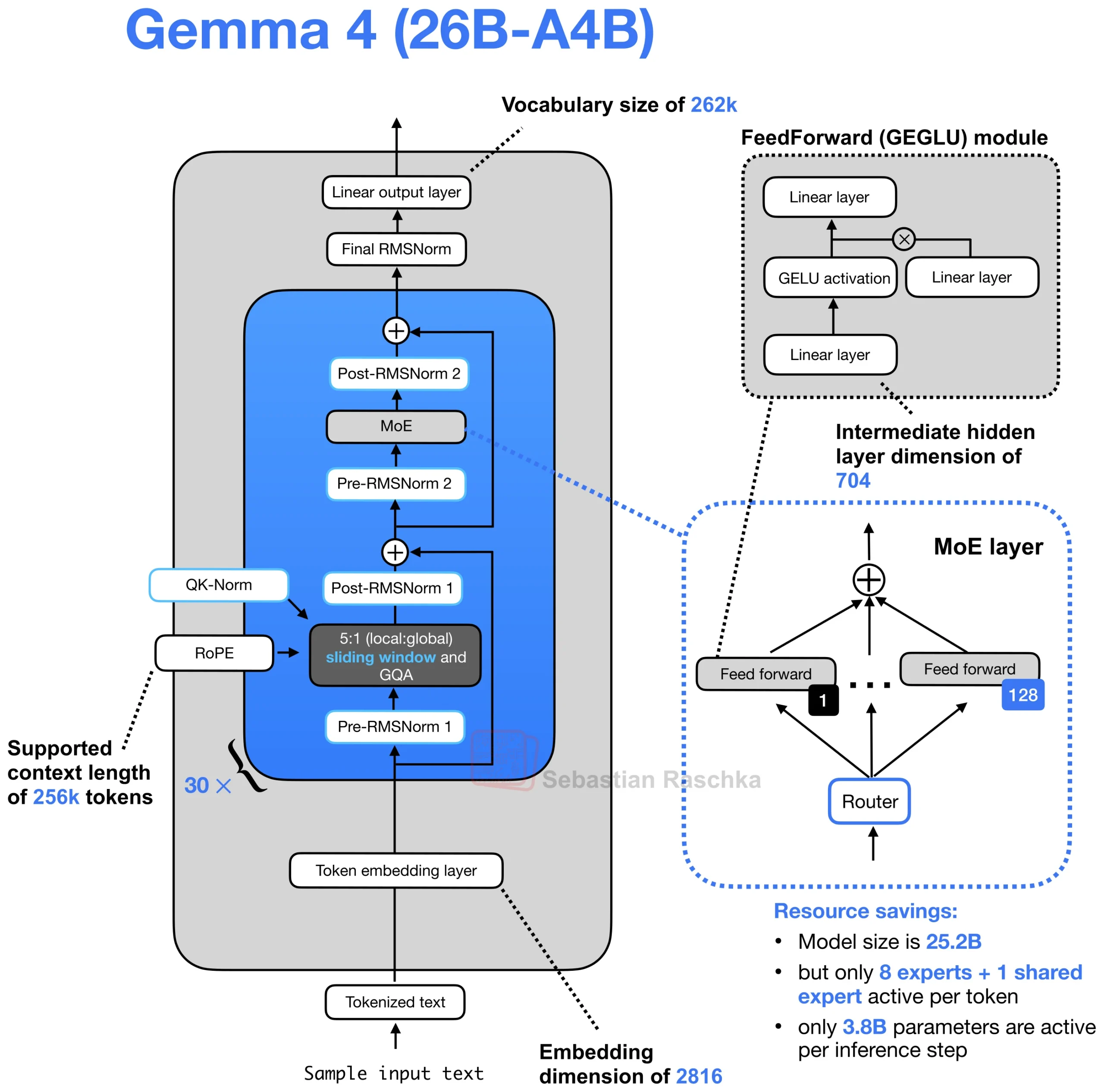
Here’s where it gets spicy. The MoE architecture doesn’t follow the standard “replace the FFN with experts” playbook. Instead, Gemma 4 uses a parallel MoE+MLP design: each layer contains both a standard dense MLP and a sparse MoE block (128 experts, top-8 routing), with their outputs summed. This is architecturally unusual, most MoEs like Nvidia’s Nemotron 3 route through experts instead of alongside them. Google’s approach likely stabilizes training while maintaining the efficiency gains of conditional computation.
The routing mechanism selects 8 experts from 128 total, plus one shared expert that’s always active. Each expert is roughly 1B parameters, meaning your VRAM only needs to hold the active subset plus the shared infrastructure. For developers with 24GB VRAM constraints, this is transformative, you can run a model that benchmarks at 82.6% on MMLU Pro (within spitting distance of the dense 31B’s 85.2%) while using less memory than a standard 7B dense model.
Trimodality Without the Frankenstein Bolts
Gemma 4 isn’t just a text model with vision and audio duct-taped to the side. It’s natively multimodal from the ground up, processing text, images, video frames, and audio through unified architectures.
Vision
Vision uses a 2D spatial RoPE (Rotary Position Embedding) that encodes patch positions as (x, y) coordinates, with half the attention head dimensions rotating for each axis. Unlike most VLMs that squash images to fixed squares and destroy aspect ratios, Gemma 4 preserves native aspect ratios using a configurable soft token budget (70 to 1120 tokens). The vision encoder is a proper conformer architecture, not a repurposed ResNet, with ~550M parameters on the larger models.
Audio
Audio support, which is native to the E2B and E4B edge models but absent on the larger variants, uses the same conformer family found in production speech systems. It handles automatic speech recognition and translation across multiple languages, with a 30-second audio context window. This isn’t a whisper.cpp wrapper, it’s baked into the transformer architecture itself.
The result is a model that can process interleaved text, images, and audio in a single forward pass without modality switching penalties. For agentic workflows that need to parse screenshots, read documents, and listen to voice commands simultaneously, this eliminates the latency and error accumulation of chained single-modal models.
The Efficiency Tricks That Make Edge Deployment Possible
Google didn’t just scale up, they optimized for the edge with architectural innovations that suggest they’ve been paying attention to efficient local inference strategies.
Per-Layer Embeddings (PLE)
On the E2B and E4B models, PLE gives each decoder layer its own small embedding table (256 dimensions) for every token. Rather than adding parameters to the transformer layers themselves, PLE moves the heavy lifting to lookup tables that are only accessed during token embedding. This is why the “Effective” parameter count (2.3B for E2B, 4.5B for E4B) is much lower than the total with embeddings (5.1B and 8B respectively).
Hybrid Attention
Alternates between sliding window attention (512-1024 tokens) and full global attention in a 5:1 ratio. Global layers use unified Key-Value projections and Proportional RoPE (p-RoPE) to optimize memory for long contexts. The small models get 128K context windows, the large models stretch to 256K, enough to ingest entire code repositories or legal briefs in a single prompt.
KV Cache Sharing
On the smaller models shares key-value projections across the last several decoder layers. One layer computes KV, the rest reuse it. Combined with the secondary per-layer embedding stream (that 256-dim signal injected at every layer), this creates a dense information pathway without dense parameter activation.
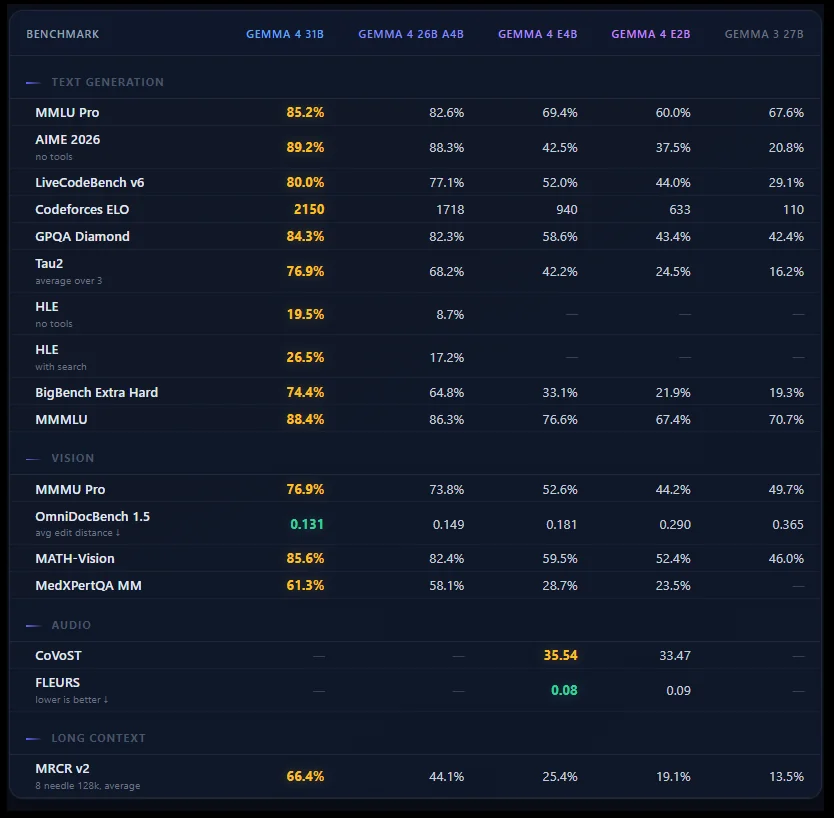
Benchmarks: Punching 20x Above Its Weight Class
The performance claims are aggressive. Google states Gemma 4 “outcompetes models 20x its size” on the Arena AI leaderboard, with the 31B dense variant currently sitting at #3 among open models and the 26B-A4B MoE at #6.
| Model | MMLU Pro | AIME 2026 | LiveCodeBench | Context |
|---|---|---|---|---|
| Gemma 4 31B | 85.2% | 89.2% | 80.0% | 256K |
| Gemma 4 26B-A4B | 82.6% | 88.3% | 77.1% | 256K |
| Gemma 3 27B | 67.6% | 20.8% | 29.1% | 128K |
The coding benchmarks are particularly notable. The 26B-A4B scores 77.1% on LiveCodeBench v6 and achieves a Codeforces ELO of 1718, competitive with dedicated coding models. For context, that’s approaching MiniMax M2.5 territory at a fraction of the parameter activation cost.
Vision benchmarks show similar gains: 76.9% on MMMU Pro for the 31B model, with OmniDocBench edit distance of 0.131 (lower is better). The model handles OCR, chart comprehension, and document parsing natively, tasks that previously required specialized vision models.
Deployment Reality: From Phones to H100s
Gemma 4 ships with day-one support for Hugging Face Transformers, llama.cpp, vLLM, MLX, and Ollama. The quantization story is particularly strong, Unsloth has already released Dynamic 2.0 GGUFs that squeeze the 26B-A4B into ~10GB VRAM at Q4_K_M precision without catastrophic quality loss.
For mobile deployment, the E2B and E4B models run on Qualcomm and MediaTek silicon through the Android AI Core Developer Preview. We’re talking about efficient small-scale audio models meeting frontier-class reasoning on devices that fit in your pocket.
The practical implication is a bifurcation in AI deployment: cloud-scale inference for the 31B dense model when you need maximum quality, and edge-native MoE inference for the 26B-A4B when you need privacy, offline capability, or sub-100ms latency.
The Catch (There’s Always One)
Despite the hype, early community testing reveals some friction. Native tool calling, while supported architecturally, appears less reliable than Qwen3.5’s implementation in initial tests, with the model occasionally generating research plans but failing to follow through with actual tool executions. This suggests the “agentic capabilities” marketing may be slightly ahead of the harness implementation.
Additionally, the MoE’s memory requirements, while efficient, aren’t magic. You still need to fit the full 26B weights in RAM/VRAM, you just only activate 4B at a time. For a 24GB GPU, this means you can run the model, but your context window gets constrained by the remaining VRAM after loading the weights.
The Bottom Line
Gemma 4 represents a strategic pivot for Google: from defensive “open” releases designed to maintain ecosystem control, to genuinely permissive Apache 2.0 weights that could become the Linux kernel of the AI age. The 26B-A4B MoE architecture proves that sparse models can deliver dense-model quality without dense-model costs, while the native trimodality eliminates the plumbing complexity that has plagued multimodal AI development.
If you’re building local-first AI, evaluating competitive MoE architectures, or simply tired of API rate limits, Gemma 4 just became the new baseline. The fact that it runs on your phone is nice. The fact that it runs under your legal control is revolutionary.



