The local LLM ecosystem has operated under a fragile truce. On one side, you have the command-line purists chaining llama.cpp with arcane flags, smug in their VRAM optimization knowledge. On the other, LMStudio provided a glossy GUI for the “rest of us”, abstracting away the complexity while keeping the code firmly under lock and key. That truce just shattered. Unsloth Studio’s beta release doesn’t merely offer another pretty interface for running GGUF files, it unifies training and inference in a single Apache-licensed application, and that distinction changes everything about who owns the local AI workflow.
The “Advanced User” Debate Is a Distraction
The announcement of Unsloth Studio immediately triggered the predictable turf wars. Some developers argued that LMStudio was never the tool for “advanced” users anyway, that title belongs to vLLM deployments or raw llama.cpp orchestration.
Others defended LMStudio’s utility for rapid model evaluation, pointing to features like RAM usage estimation and the convenience of remote model loading without wrestling with reverse proxies.
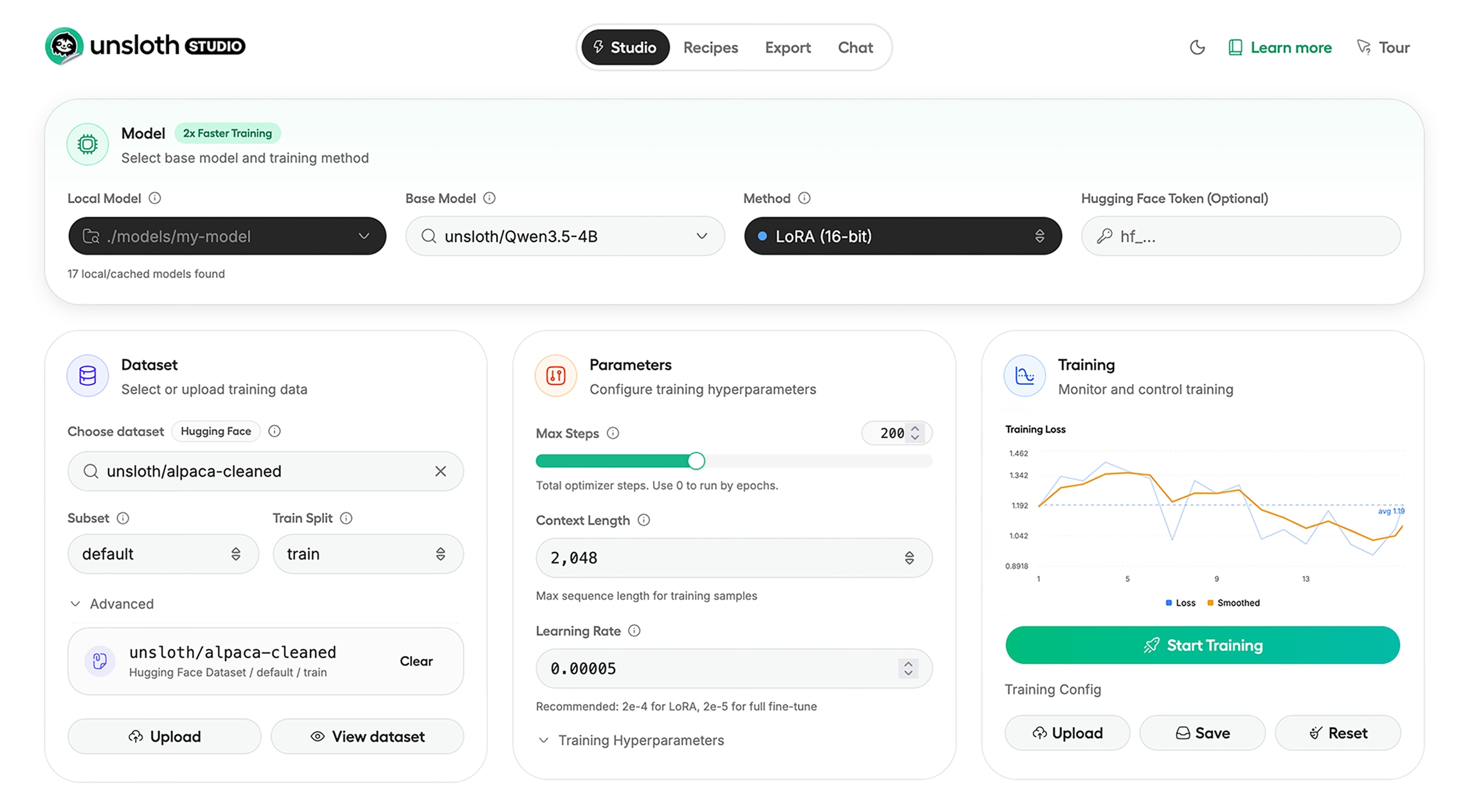
This semantic squabble misses the point. Unsloth Studio isn’t trying to be just another inference wrapper. By integrating Unsloth’s optimized training kernels, the same ones that deliver 2x faster training with 70% less VRAM usage, into a local web UI, it collapses the traditional pipeline. Previously, fine-tuning a model required juggling three separate projects: one for data preparation, one for training, and one for inference. Now you can upload a PDF, generate synthetic training data via the visual Data Recipes workflow, fine-tune Qwen3.5 or Nemotron 3, and export directly to GGUF for local inference without leaving the browser.
What “Unified” Actually Means Technically
The Convergence Layer
The Studio supports 500+ models with LoRA, FP8, FFT, and PT optimizations across text, vision, TTS/audio, and embedding models. Unlike LMStudio, which focuses exclusively on inference, Studio handles the full lifecycle. The Data Recipes feature, powered by NVIDIA’s DataDesigner, transforms unstructured PDFs, CSVs, and DOCX files into structured instruction-following datasets through a node-based visual interface. This isn’t just convenience, it eliminates the boilerplate Python scripts that previously separated “I have data” from “I have a trained model.”.
Self-Healing Tool Calling
The chat interface includes auto-healing tool calling and web search capabilities, but more importantly, it features sandboxed code execution. The LLM can generate Python or bash scripts, execute them in an isolated environment, and use the results to verify or refine its answers. This moves beyond simple text generation into agentic workflows that can calculate, analyze data, and generate files, functionality that typically requires separate orchestration layers like LangChain or OpenClaw.
The Model Arena
Side-by-side model comparison isn’t novel, but Studio’s implementation allows you to load a base model and your fine-tuned variant simultaneously, watching how your custom training affects outputs in real-time. For practitioners iterating on domain-specific datasets, this eliminates the cognitive overhead of context-switching between separate inference instances.
The Technical Moat: Triton Kernels and Memory Arbitrage
This isn’t marketing fluff, it’s the difference between being able to fine-tune Llama 3.3 on an RTX 4090 versus renting an A100 cluster.
The Studio also integrates GRPO (Group Relative Policy Optimization), the reinforcement learning technique that powered DeepSeek-R1’s reasoning capabilities. Unlike traditional PPO, which requires a separate critic model consuming significant VRAM, GRPO calculates rewards relative to output groups, making reasoning model training feasible on local hardware.
If you’re curious about how aggressive quantization affects model fidelity when compressing these models for consumer GPUs, check out our analysis of quantization fidelity and GGUF benchmarking metrics, the metrics matter more than ever when you’re training models locally before deployment.
For those wondering about the viability of extreme compression, Unsloth’s previous work on 2-bit quantization for VRAM reduction demonstrates how far the ecosystem has pushed memory efficiency. Studio inherits these optimizations, allowing you to export trained models not just to standard 16-bit safetensors, but to GGUF formats compatible with llama.cpp, vLLM, and yes, ironically, LMStudio itself.
License as Strategy: Why Apache 2.0 Matters
Unsloth Studio runs 100% offline with token-based JWT authentication and no telemetry collection. For enterprises and privacy-conscious developers, the ability to audit exactly how their model weights are being handled isn’t philosophical, it’s compliance-critical. The open-source nature also means the community can extend the tool beyond the original scope, something impossible with LMStudio’s black-box binaries.
The platform cross-compatibility is telling: Mac (inference only for now, with MLX training coming), Windows, Linux, and WSL support out of the box. This stands in contrast to the fragmented experience of running optimized local models on Apple Silicon, though if you’re committed to the Mac ecosystem, our guide on running production AI inference on consumer hardware remains relevant for understanding the memory constraints Studio will face once MLX training arrives.
The Beta Reality Check: Installation and Limitations
The installation itself is straightforward for those familiar with Python environments:
pip install unsloth
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
But that simplicity belies the computational requirements. Training 8B parameter models requires substantial VRAM even with Unsloth’s optimizations, though the 70% reduction makes it feasible on 24GB consumer cards where it previously required 40GB+.
Where This Fits in the Local LLM Stack
However, for the developer who wants to move beyond prompting into actual model ownership, fine-tuning on proprietary data, exporting to deploying massive 230B models on local hardware (if you’re brave), or simply fine-tuning small models to beat frontier AI, Studio removes the toolchain fragmentation that previously gated these workflows.
The comparison to Llama-Factory is inevitable, both offer training UIs, but Studio’s integration of synthetic data generation, code execution, and the Model Arena creates a more cohesive experimental environment. When you can generate a dataset from a PDF, train with GRPO, and immediately battle-test against the base model without context-switching, the iteration cycle compresses from days to hours.
The Implications for Model Ownership
For LMStudio, the threat isn’t just that Unsloth is open-source, it’s that Unsloth makes the training-inference loop accessible to the same audience LMStudio targets. When users realize they can not only run models but also specialize them for their specific use cases, achieving local LLM efficiency and architecture breakdowns that rival cloud APIs, the value proposition of a closed-source inference-only tool becomes harder to justify.
The beta is rough around the edges. The compilation times are real, the hardware limitations are restrictive, and the AGPL licensing of the UI components requires careful consideration for commercial redistribution. But the direction is clear: the future of local AI belongs to tools that let you own the entire stack, from data preparation through deployment, not just the inference endpoint.



