
Mistral’s Voxtral TTS Promises Open Weights, But Hides the Good Stuff Behind an API
Mistral AI just dropped a text-to-speech model that fits on a smartwatch, runs at 90ms latency, and supposedly beats ElevenLabs Flash v2.5 in blind taste tests. The catch? The “open” weights come with a non-commercial license, and the killer feature, zero-shot voice cloning, is locked behind their API, leaving local deployments with a gimped experience.
Welcome to the new era of open-weight AI, where the weights are free but the utility is freemium.

The Technical Reality: A 4B Parameter Beast in a 3GB Package
Voxtral TTS isn’t your average lightweight TTS hack. Built on top of Ministral 3B, this is a transformer-based, autoregressive, flow-matching model with some serious architectural chops:
- 3.4B parameter transformer decoder backbone
- 390M flow-matching acoustic transformer
- 300M neural audio codec (symmetric encoder-decoder)
- 12.5Hz frame rate processing via an in-house semantic VQ (8192 vocabulary) and acoustic FSQ (36 dim, 21 levels)
The result? A model that generates 24kHz audio with a real-time factor (RTF) of approximately 0.103 on a single NVIDIA H200, meaning it renders 10 seconds of audio in roughly one second. For context, that’s competitive with ElevenLabs’ Flash tier while allegedly delivering quality on par with their v3 model.
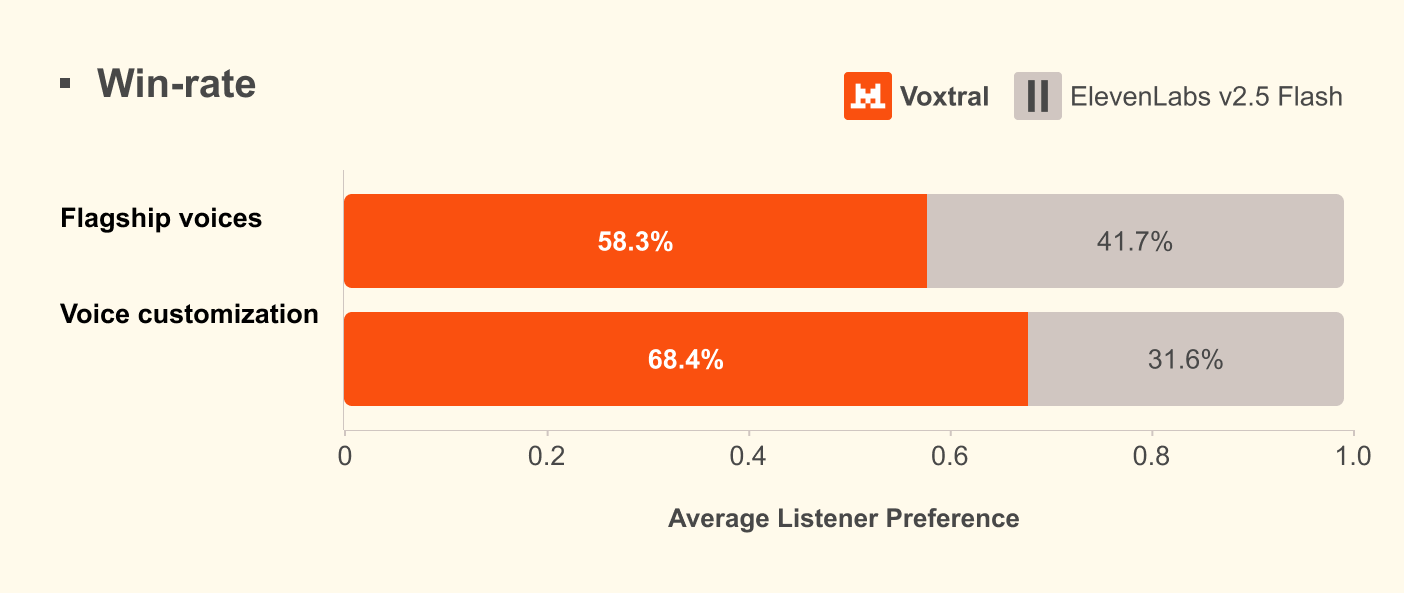
Mistral’s benchmarks claim superior naturalness in zero-shot custom voice scenarios across nine languages: English, French, German, Spanish, Dutch, Portuguese, Italian, Hindi, and Arabic. The model adapts to new voices with as little as 3-5 seconds of reference audio, capturing not just tone but “disfluencies”, those natural pauses and verbal stumbles that make speech sound human rather than robotic.
But here’s where the narrative gets complicated.
The Open-Weights Gambit: CC BY-NC 4.0 and the Missing Encoder
Mistral released the weights on Hugging Face under CC BY-NC 4.0, Creative Commons Attribution Non-Commercial. That NC clause is the first red flag for enterprise adoption. You can prototype, research, and build internal tools, but the moment you want to ship a product that generates revenue, you’re back to Mistral’s API at $0.016 per 1k characters.
Critical Limitation: The open-weights release doesn’t include the voice cloning encoder. The Hugging Face repo ships with 20 preset voices, but if you want to clone your CEO’s voice for the company IVR system, you need the API. The local version is essentially a very good generic TTS system with fixed personas.
This distinction sparked immediate frustration in the developer community. The prevailing sentiment on technical forums is that releasing a TTS model without the voice adaptation encoder is like shipping a car without the engine, you can look at it, but you can’t drive it anywhere interesting.
The licensing constraints aren’t arbitrary cruelty, they’re likely inherited from the training data. The reference voices come from datasets like EARS, CML-TTS, IndicVoices-R, and Arabic Natural Audio, all carrying non-commercial restrictions. As one developer noted, Mistral can’t release what they don’t own, but that doesn’t make the limitation any less painful for practitioners hoping to build commercial voice agents offline.
Edge Computing Theater: Smartwatch-Sized or Server-Only?
Mistral’s marketing leans heavily into edge deployment, “fits on a smartwatch”, runs on “3GB of RAM”, the usual IoT buzzword bingo. Technically, this is true. The BF16 weights can squeeze onto a 16GB GPU for serving via vLLM Omni, and the model latency clocks in at 70ms for a 500-character input with 10 seconds of reference audio.
But let’s talk about what “runs on a smartphone” actually means in 2026. While the model can technically fit in 3GB of RAM, achieving the advertised 90ms time-to-first-audio requires optimized inference stacks. The Hugging Face documentation recommends vLLM Omni with specific concurrency tuning:

| Concurrency | Latency | RTF | Throughput (char/s/GPU) |
|---|---|---|---|
| 1 | 70 ms | 0.103 | 119.14 |
| 16 | 331 ms | 0.237 | 879.11 |
| 32 | 552 ms | 0.302 | 1430.78 |
Notice that throughput peaks at 32 concurrent requests, but latency quadruples. For a real-time voice assistant requiring sub-200ms response times, you’re looking at single-digit concurrency per GPU. That “smartwatch” deployment is technically possible, but practically useless for anything beyond demo apps unless you’re running quantized INT8 versions that sacrifice quality.
This puts Voxtral in an awkward middle ground: too heavy for true edge deployment on consumer devices without significant optimization, yet lighter than the cloud-only behemoths. It’s optimized for enterprise edge, think call center appliances and automotive systems, not your iPhone.
The ElevenLabs Problem: Performance vs. Ecosystem
Mistral claims Voxtral outperforms ElevenLabs Flash v2.5 in human preference tests, particularly in zero-shot voice adaptation. The company emphasizes “emotional expressiveness” and cross-lingual voice preservation, generating English with a French accent when prompted with French reference audio, for instance.
These are genuine technical achievements. ElevenLabs has dominated the TTS space through a combination of quality and developer experience, but their pricing and API-only approach have left a vacuum for open alternatives. Mistral’s concurrent speech-to-text breakthrough earlier this year signaled their intent to own the full voice stack, and Voxtral TTS completes the circle.
However, ElevenLabs’ ecosystem advantage remains formidable. Voice cloning, dubbing, and the “Flash” tier’s latency optimization are polished products with comprehensive documentation. Voxtral’s open-weights release, by contrast, requires significant engineering investment to match ElevenLabs’ out-of-box experience, especially when the voice cloning feature requires API access anyway.
For developers seeking truly open alternatives, alternative lightweight open-source TTS models like KaniTTS2 (400M parameters, full voice cloning, permissive license) or Kokoro offer more freedom, albeit with different quality trade-offs.
Deployment Reality: Who Should Actually Use This?
If you’re building a voice agent for customer support, sales automation, or real-time translation, Voxtral TTS presents a compelling value proposition, provided you’re comfortable with Mistral’s platform lock-in for advanced features. The API pricing ($0.016/1k characters) undercuts ElevenLabs significantly while delivering comparable quality, and the cross-lingual capabilities are genuinely impressive for global deployments.
The open-weights release serves a different purpose: it’s a Trojan horse for enterprise adoption. Companies can evaluate the model locally, ensure it meets quality bars for their specific use cases (those “disfluencies” and accent nuances vary wildly by domain), then migrate to the paid API for production voice cloning. It’s a savvy move that mirrors Mistral’s comprehensive open-weight strategy across their model lineup.
For researchers and hobbyists, the CC BY-NC license is restrictive but functional. You can build conversational AI demos, experiment with cascaded speech-to-speech translation systems, or fine-tune the 4B parameters on your own non-commercial datasets. Just don’t expect to ship a voice cloning app without negotiating enterprise terms.
The technical implementation is straightforward for those familiar with vLLM:
import httpx
import soundfile as sf
import io
payload = {
"input": "Paris is a beautiful city!",
"model": "mistralai/Voxtral-4B-TTS-2603",
"response_format": "wav",
"voice": "causal_male",
}
response = httpx.post(
"http://localhost:8000/v1/audio/speech",
json=payload,
timeout=120.0
)
audio_array, sr = sf.read(io.BytesIO(response.content), dtype="float32")
But remember: that causal_male voice is one of twenty presets. If you want Margaret from accounting to read your compliance documentation, you’ll need the API key.
The Verdict: Progress With Pragmatic Limitations
Voxtral TTS represents a meaningful advance in open-weight audio generation, the architectural sophistication of the flow-matching approach, the multilingual support, and the edge-deployment potential are all legitimate achievements. The 90ms TTFA and sub-100ms model latency put it in conversation with the fastest proprietary systems.
Yet the release strategy feels calculated rather than altruistic. By withholding the voice cloning encoder and slapping on an NC license, Mistral ensures the “open” version serves as a high-quality demo while the real utility remains monetized. It’s a far cry from the Apache 2.0 releases that built Mistral’s reputation in the LLM space.
For enterprises evaluating voice AI stacks, the calculation is simple: Voxtral offers 80% of ElevenLabs’ quality at 60% of the price, with the option to self-host generic voices if data sovereignty demands it. For the open-source purists hoping to build fully offline voice cloning systems, the search continues. The weights are open, but the voices remain rented.



