Mistral just pulled off the kind of move that makes both enterprise vendors and open-source purists nervous: they shipped a 4-billion-parameter speech model that transcribes audio in under 500 milliseconds, released it under Apache 2.0, and claimed it runs on edge devices. The AI community’s reaction has been equal parts exhilaration and skepticism, and both sides have a point.
Voxtral Mini 4B Realtime isn’t just another incremental improvement in speech-to-text. It’s among the first open-source models to achieve offline-level accuracy with streaming latency that makes real-time voice applications actually feasible. At a 480ms delay, it matches the performance of leading offline transcription models while processing audio in 13 languages simultaneously. That’s not a minor achievement, it’s a direct assault on the proprietary APIs that have dominated voice AI for years.
But here’s where it gets interesting: the model’s most telling features might be the ones Mistral didn’t include.
The Streaming Architecture That Forces Hard Choices
Unlike conventional approaches that adapt offline models by processing audio in chunks, Voxtral Mini uses a natively streaming architecture with a custom causal audio encoder. This isn’t marketing fluff, it fundamentally changes how the model handles audio. The encoder processes sound as it arrives, using causal attention to ensure no “look-ahead” bias. Combined with sliding window attention in both encoder and language model backbone, it enables what Mistral calls “infinite streaming.”
The technical specs are compelling: approximately 3.4B language model parameters paired with a 0.6B audio encoder trained from scratch. At 12.5 tokens per second throughput, it can handle real-time transcription on minimal hardware. A single text token represents about 80ms of audio, giving developers fine-grained control over latency versus accuracy tradeoffs.
But this architecture comes with explicit tradeoffs that power users immediately spotted. As one developer noted in the launch discussion, the model lacks turn detection, critical for knowing when a speaker has finished. Mistral’s team confirmed it didn’t make the release deadline but promised it for the next version. For anyone building voice agents, this means you’ll still need a separate punctuation model, timing heuristics, or third-party text-based turn detection.
The community feedback reveals a pattern: Voxtral Mini is brilliant at what it does, but it’s not the kitchen-sink solution some expected. This is intentional design, not oversight.
Benchmarks vs. Reality: The 480ms Sweet Spot
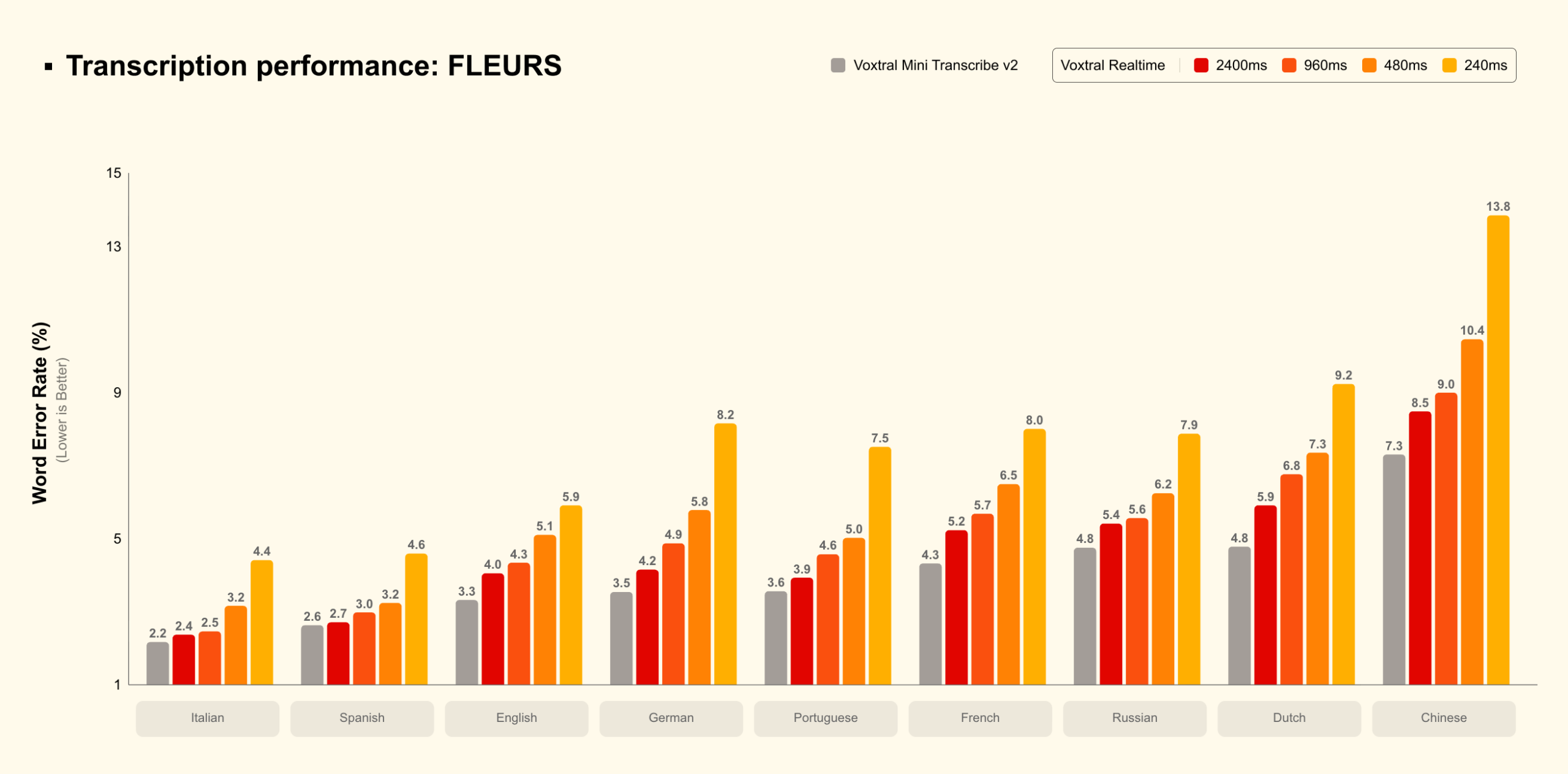
Mistral’s benchmarking data shows Voxtral Mini achieving an 8.72% average word error rate across 13 languages at 480ms delay, competitive with offline models while maintaining sub-second responsiveness. On English long-form audio, it hits 5.05% WER, nearly matching its offline sibling Voxtral Mini Transcribe 2.0’s 4.08%.
| Model | Delay | AVG (FLEURS) | English |
|---|---|---|---|
| Voxtral Mini Transcribe 2.0 | Offline | 5.90% | 3.32% |
| Voxtral Mini 4B Realtime | 480ms | 8.72% | 4.90% |
The performance degrades gracefully at lower latencies: 240ms yields 10.80% WER, while aggressive 160ms streaming hits 12.60%. For applications where every millisecond counts, like live voice assistants, the model can be pushed to sub-200ms territory, though accuracy suffers.
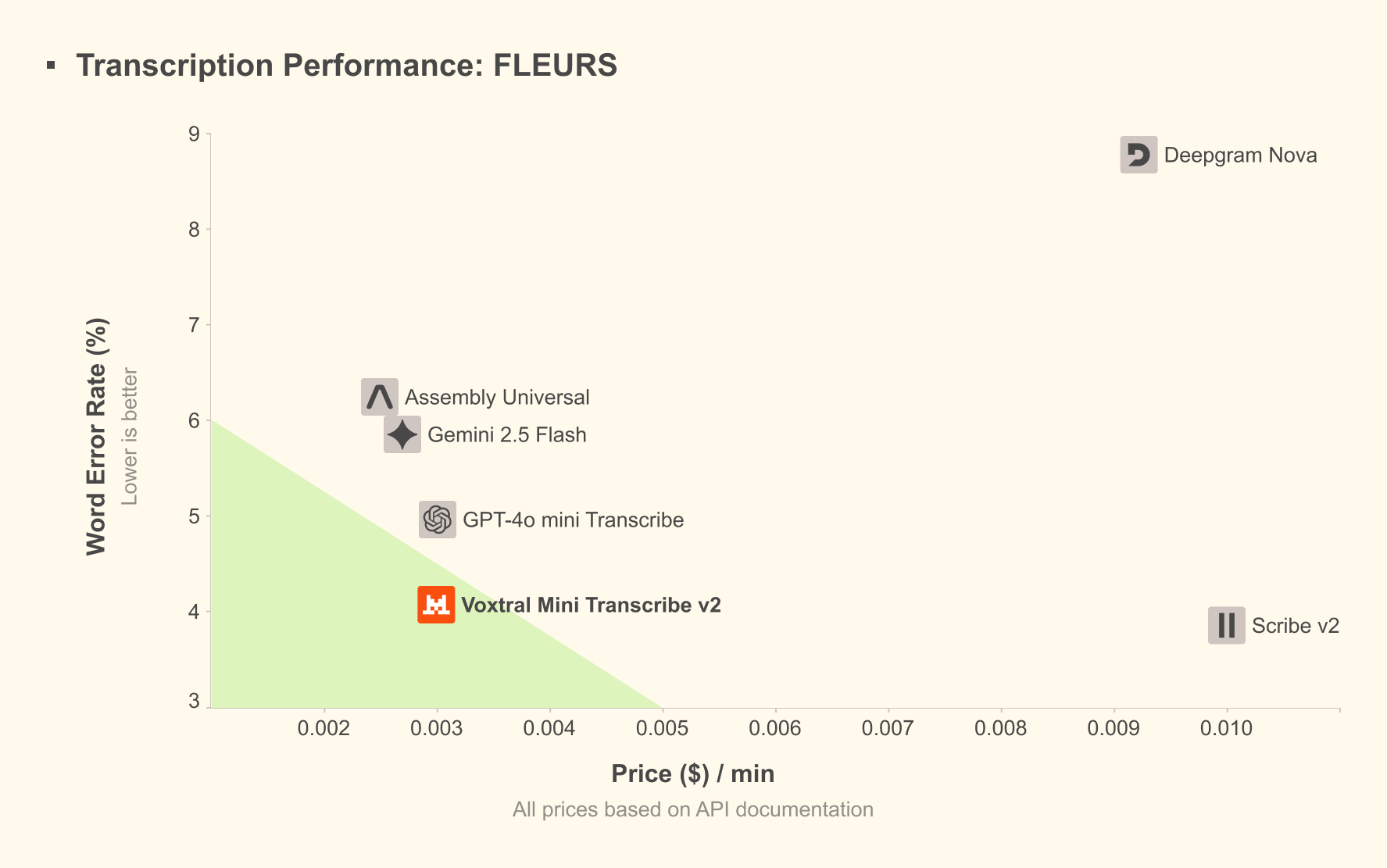
What’s controversial here is the comparison set. Mistral benchmarks against open-source baselines and real-time APIs, but enterprise buyers will compare it against closed systems like Deepgram Nova or AssemblyAI. The pricing tells the real story: Mistral charges $0.006 per minute for the hosted API, undercutting competitors by 50-80%. When you’re processing millions of minutes monthly, that delta becomes a board-level discussion.
The Open Source Catch-22
Here’s where Mistral’s strategy gets nuanced. The model ships under Apache 2.0 license, genuinely open weights, commercially usable, no attribution required. You can download the 8.87GB model from Hugging Face and deploy it anywhere. For European companies grappling with digital sovereignty requirements, this is a compliance godsend.
But there’s a catch: Voxtral Mini currently only works with vLLM. The model card explicitly states: “Due to its novel architecture, Voxtral Realtime is currently only supported in vLLM. We very much welcome community contributions to add the architecture to Transformers and Llama.cpp.”
This limitation sparked immediate debate. One developer commented: “I’m bummed this has come at the expense of even providing a PyTorch or HF transformers implementation. The model is small enough to even run on a Pi, but right now, if you don’t have vLLM compatible hardware, you’re out of luck.”
Another countered: “I have to agree that not having a torch or transformers implementation is sad… I’m pretty confident it can’t run on a Pi though. It is running whisper encoder at 12.5Hz, it should globally take more flops than Kyutai’s 2.6B STT, which takes 20% of my Apple M4 after heavy quantization.”
The controversy isn’t just about convenience, it’s about accessibility. By tying the model to vLLM, Mistral ensures production-grade performance but excludes hobbyists and edge deployments on constrained hardware. This is a deliberate choice: optimize for the enterprise use case where performance matters more than portability.
The Strategic Omissions: Diarization and Turn Detection
Mistral released two models: Voxtral Mini Transcribe 2.0 for batch processing, and Voxtral Mini 4B Realtime for streaming. The batch model includes speaker diarization, context biasing for 100 hotwords, and word-level timestamps. The real-time model has none of these.
As one commenter put it: “I was so excited for diarization, but… not on the open model. Still interested to check out the Realtime model.”
Mistral’s Pierre Stock explained the rationale to WIRED: “What we are building is a system to be able to seamlessly translate. This model is basically laying the groundwork for that.” The implication is clear: Voxtral Mini is a foundational component, not a finished product.
This approach reflects Mistral’s broader open-weight strategy, ship the core model, let the community build around it. It’s the opposite of OpenAI’s “we’ll handle everything” philosophy. But it also means developers must cobble together additional components: a separate diarization model, custom turn detection logic, and their own context biasing implementation.
The European Sovereignty Play
Mistral isn’t just selling a model, they’re selling independence. With €2 billion in funding and a $14 billion valuation, the company has positioned itself as Europe’s answer to US AI dominance. Voxtral Mini’s on-device capability directly addresses GDPR and HIPAA compliance concerns that keep European CTOs awake at night.
As WIRED noted, Mistral’s VP of science operations, Pierre Stock, threw shade at American competitors: “Frankly, too many GPUs makes you lazy. You just blindly test a lot of things, but you don’t think what’s the shortest path to success.”
This isn’t just bravado, it’s a business model. While US labs chase trillion-parameter general intelligence, Mistral focuses on efficient, specialized models that deliver ROI today. The approach resonates with European enterprises wary of cloud dependency and regulatory risk.
The geopolitical timing is impeccable. As US-European relations show strain, Mistral offers a sovereign alternative that complies with EU AI Act requirements and keeps data within borders. For applications like contact center automation or medical transcription, this isn’t a nice-to-have, it’s a deal-breaker.
What This Means for Voice AI’s Future
Voxtral Mini’s release signals a market shift. Real-time transcription is becoming a commodity, and the moat is moving from raw accuracy to system integration. The model’s limitations, no diarization, vLLM dependency, missing turn detection, are actually opportunities for developers to differentiate.
We’re already seeing this pattern with Mistral’s Devstral 2 backlash, where the community’s frustration with missing features led to rapid third-party improvements. Voxtral Mini will likely follow the same trajectory.
The pricing disruption is real. At $0.003/minute for batch and $0.006/minute for real-time, Mistral is forcing a 50-80% price correction across the industry. This puts pressure on closed API providers to justify their premiums, accelerating the shift toward open-weight models.
The Bottom Line: A Breakthrough, But Not a Silver Bullet
Mistral’s Voxtral Mini 4B Realtime is genuinely groundbreaking. It proves that open-source models can match proprietary APIs on latency and accuracy while running on modest hardware. For developers building voice assistants, live subtitles, or contact center automation, it’s a compelling alternative to cloud lock-in.
But it’s not the universal solution some hoped for. The vLLM dependency, missing diarization, and lack of turn detection mean you’ll still need a Frankenstein architecture for production systems. As one developer summarized: “This is the kind of tool that pushes the entire industry forward, but if you’re building anything with voice and haven’t tried this yet, you’re not behind, you’re just waiting for the ecosystem to catch up.”
The real innovation isn’t just the sub-500ms transcription. It’s Mistral’s bet that the future of AI is modular, open, and strategically incomplete. They’re not trying to win the feature checklist war. They’re trying to make the foundational models so accessible and affordable that the community builds the rest, and in doing so, creates an ecosystem they can shape but never fully control.
That’s either brilliant strategy or a recipe for fragmentation. Given Mistral’s track record of turning open-weight releases into market momentum, I’m betting on brilliant. But don’t throw away your existing transcription pipeline just yet.



