A funny thing happened in the AI landscape this week: while giants like OpenAI and Anthropic chase trillion-parameter moonshots, French upstart Mistral quietly dropped what might be the most strategically significant model release of the year. A full spectrum of open-weight AI models spanning from smartphone-friendly 3B parameters to enterprise-grade 675B, all under Apache 2.0 licensing.
The immediate verdict from developers? Finally, something we can actually use.
The Complete Open-Weight Stack
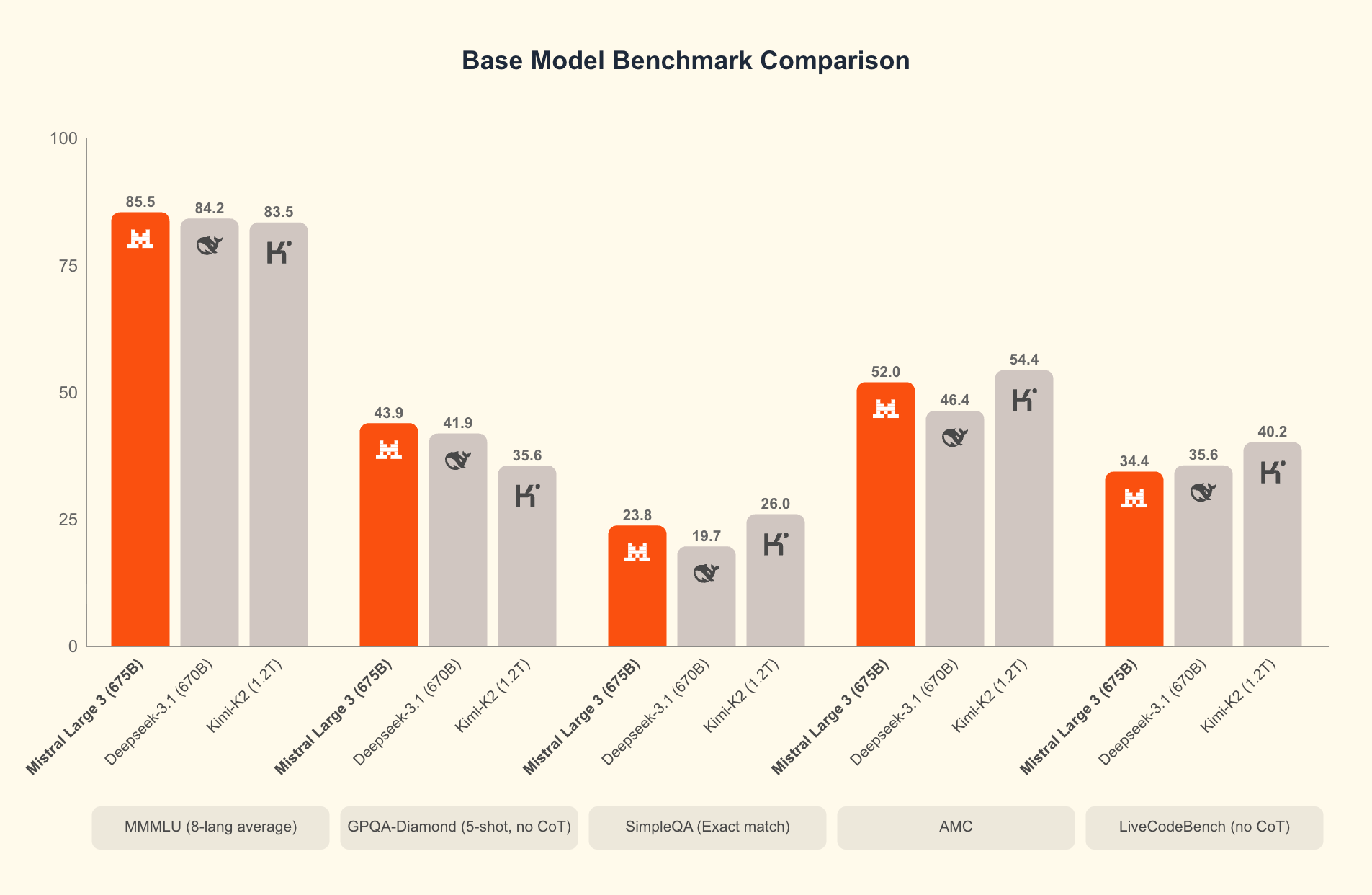
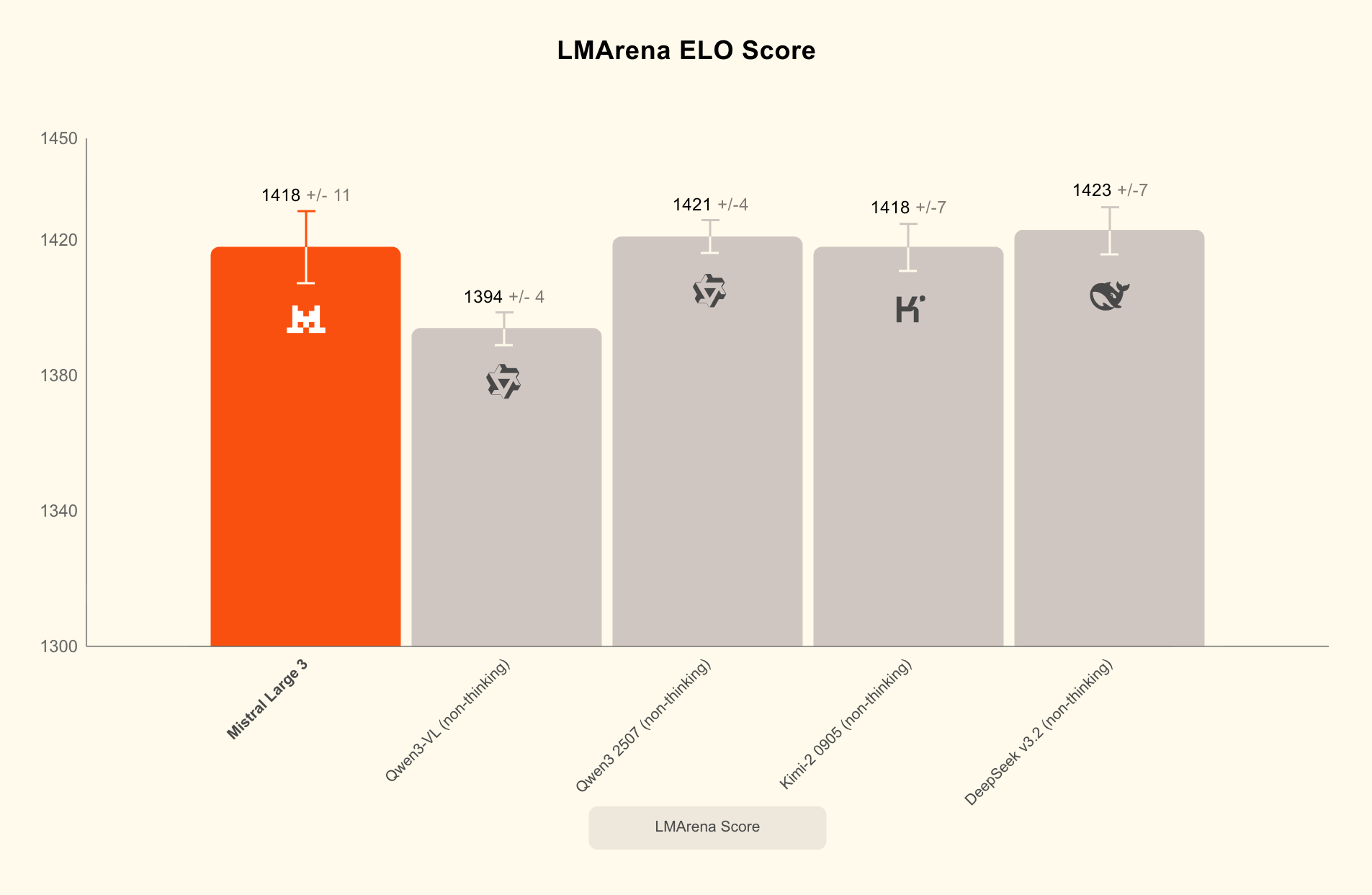
Mistral 3 isn’t just a single model, it’s a comprehensive ecosystem addressing every tier of the AI deployment landscape. At the top sits Mistral Large 3, a 675B parameter mixture-of-experts model with world-class multilingual performance that “trades blows with Qwen 3 (1421) and Kimi-2 (1418)” according to LMarena leaderboards. With 41B active parameters, it represents Mistral’s first MoE architecture since the seminal Mixtral series, trained from scratch on 3,000 NVIDIA H200 GPUs.
More critically, the Ministral family, 3B, 8B, and 14B variants, delivers what the community has been demanding: efficient, capable models that can actually run locally. Each comes in base, instruct, and reasoning flavors, with vision capabilities baked in across the board.
The “Giant Hole” That Has Developers Talking
Reaction across developer forums reveals one glaring gap: the jump from 14B to 675B leaves what many describe as “a giant chasm” in the sweet spot for consumer-grade hardware. As one commenter put it, “Leaving nothing between 14B and 675B is really funny, just a giant chasm.”
This sentiment echoes across the community, with developers noting that “the middle range is where most serious local setups actually operate.” The consensus suggests that a dense 80B, 150B model or smaller-expert MoE around 200B would have hit the perfect balance between quality and feasibility for enthusiast-grade hardware.
Performance That Punches Above Its Weight
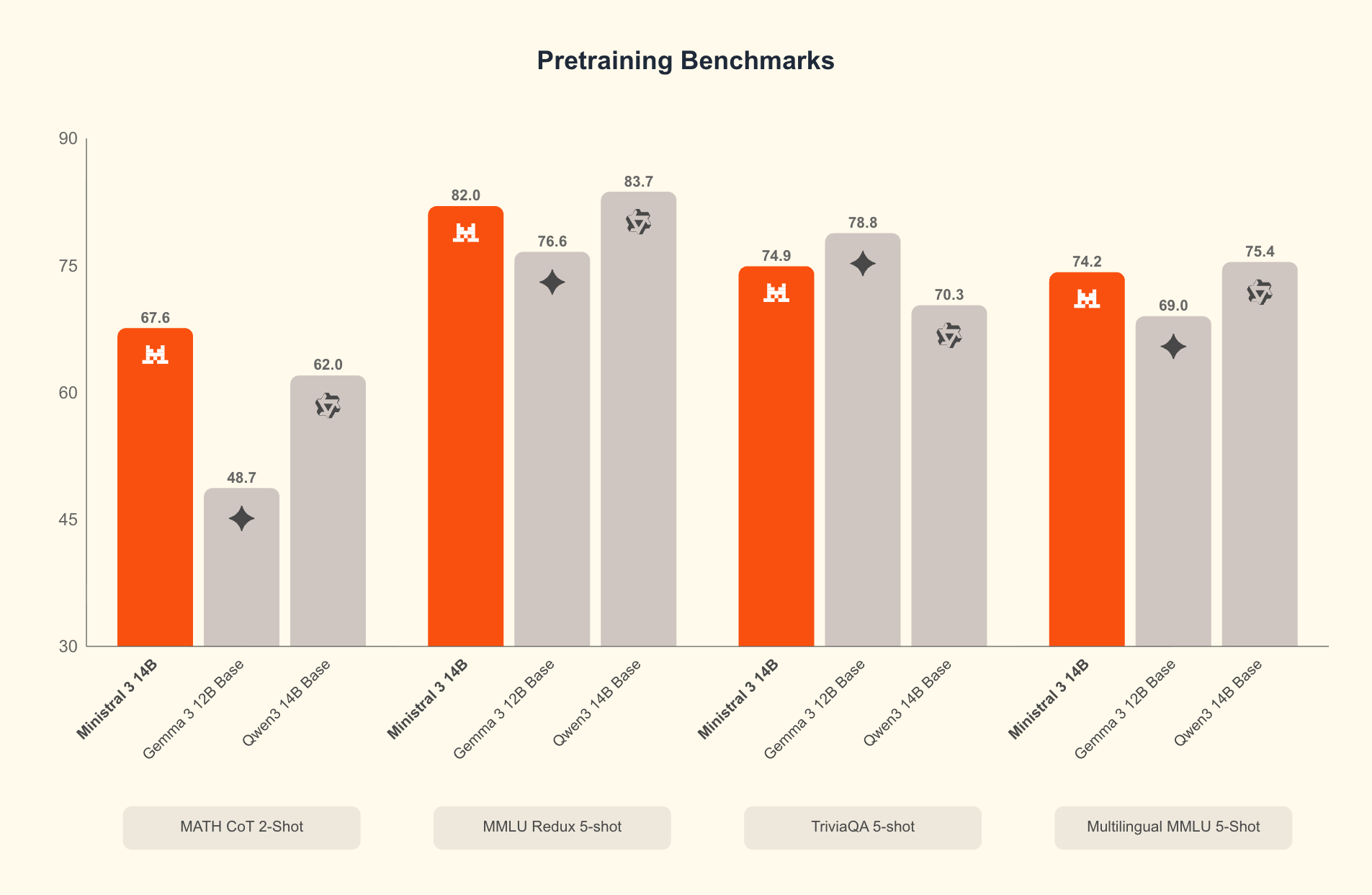
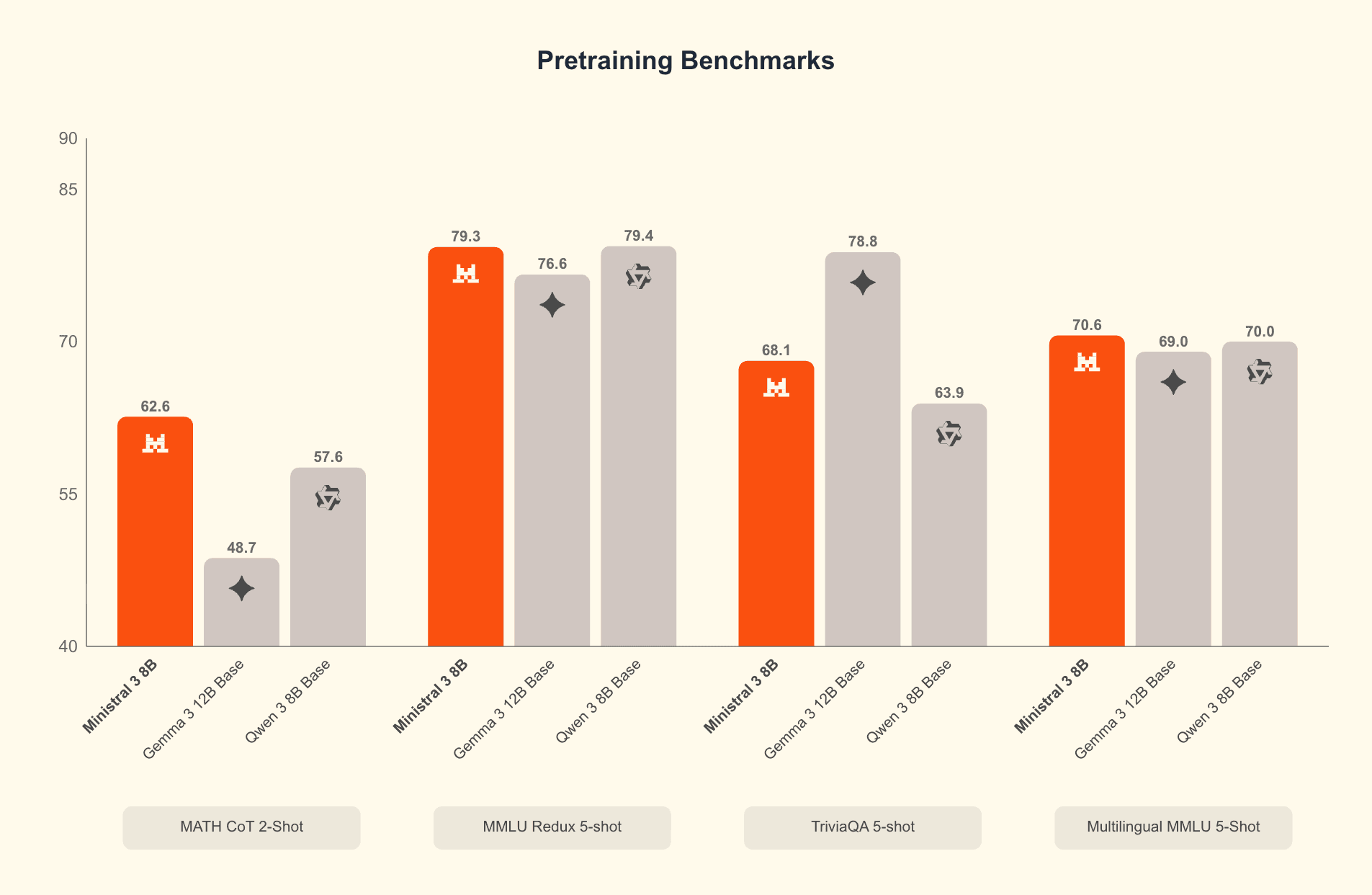
The Ministral models aren’t just small, they’re efficient. Early testing reveals the 14B variant performs competitively with the previous 24B lineup while being “far lighter on VRAM and compute.” For setups like dual P40 GPUs, the 14B becomes “basically the sweet spot, you get 24B-level capability without blowing past your VRAM budget.”
The technical specifications reveal why these models excel in constrained environments. Ministral 3 14B requires just 32GB of VRAM in BF16 format, dropping below 24GB when quantized. The 8B model fits comfortably in consumer-grade hardware, while the 3B variant can run on smartphones and embedded devices.
But performance extends beyond raw parameter counts. Each model variant is optimized for specific workloads:
# Example deployment for Ministral 3 14B Reasoning
vllm serve mistralai/Ministral-3-14B-Reasoning-2512 \
--tensor-parallel-size 2 \
--tokenizer_mode mistral --config_format mistral --load_format mistral \
--enable-auto-tool-choice --tool-call-parser mistral \
--reasoning-parser mistralThe reasoning variants particularly shine in mathematical and coding tasks, achieving 71.2% on GPQA Diamond compared to Qwen3-14B’s 66.3%. This capability comes from Mistral’s explicit training for “complex, multi-step reasoning and dynamic problem-solving.”
Apache 2.0: The Silent Game-Changer
Perhaps the most significant aspect of this release goes beyond technical specifications. Every model in the Mistral 3 family ships under Apache 2.0 licensing, making them fully usable for commercial and research work without restrictive usage terms.
This stands in stark contrast to OpenAI’s closed models and even other “open” models with more restrictive licenses. As one AWS blog post noted, Amazon Bedrock has added these models alongside 18 other open-weight options, giving enterprises unprecedented deployment flexibility.
The Apache 2.0 licensing means corporations can fine-tune, deploy, and commercialize these models without legal ambiguity, a critical consideration for enterprise adoption.
Edge Deployment: Where Mistral Excels
Mistral’s edge-first philosophy shines in hardware requirements. While their 675B flagship demands serious infrastructure (running efficiently on Blackwell NVL72 systems or 8×A100/H100 nodes), the Ministral models can deploy on “affordable hardware, from on-premise servers to laptops, robots, and other edge devices that may have limited connectivity.”
This accessibility matters for practical deployment scenarios. As noted in AWS documentation, Ministral 3 8B “can run on a single 1xH200 GPU” while still delivering “best-in-class performance […] ideal for chat interfaces in constrained environments, image and document description and understanding, specialized agentic use cases, and balanced performance for local or embedded systems.”
The 3B variant pushes this even further, enabling “image captioning, text classification, real-time translation, data extraction, short content generation, and lightweight real-time applications on edge or low-resource devices.”
The Enterprise Reality Check
While benchmarks tell one story, real-world performance tells another. Early adopters report mixed experiences with the Ministral 3 14B Instruct variant compared to Mistral Small 3.2 24B. In testing involving “relatively simple programming tasks, some visual document Q&A, some general world knowledge Q&A, and some creative writing”, users found Ministral 3 “much more willing to write long form content” with “perhaps its writing style is better too.”
However, the smaller model showed weaknesses: “For world knowledge, Ministral 3 14B was a very clear downgrade from Mistral Small 3.2.” The 14B variant also demonstrated a tendency toward “repetitive loops when writing stories”, though it remained “competitive among current open models in this size class.”

NVIDIA Partnership: Hardware Meets Software
Mistral’s collaboration with NVIDIA demonstrates the practical reality of deploying models at this scale. Large 3 ships with optimized checkpoints in NVFP4 format, built with llm-compressor, specifically designed for Blackwell systems.
The technical partnerships extend beyond inference optimization. NVIDIA integrated “state-of-the-art Blackwell attention and MoE kernels” and collaborated on “speculative decoding, enabling developers to efficiently serve long-context, high-throughput workloads on GB200 NVL72 and beyond.”
This hardware-software co-design represents the maturation of open-weight AI deployment, moving beyond theoretical performance to practical, scalable infrastructure.
The Missing Middle Ground
Despite the comprehensive model portfolio, developer feedback consistently points to one strategic gap: the absence of models between 14B and 675B. As one commenter summarized, “Same here, that middle range is where most serious local setups actually operate. A dense 80B, 150B or a smaller-expert MoE in the 200B range would’ve hit the perfect balance between quality and feasibility.”
What This Means for the AI Ecosystem
Mistral 3 represents more than just another model release, it’s a strategic declaration in the battle for AI dominance. By covering the full spectrum from edge to enterprise with open-weight models, Mistral positions itself as the pragmatic alternative to closed-source giants.
The timing is significant. As enterprises grow wary of vendor lock-in and seek more control over their AI infrastructure, Mistral offers a compelling proposition: frontier-class capabilities without the black-box dependency.
Accessibility extends beyond licensing to practical deployment. With models available across major platforms including Hugging Face, Amazon Bedrock, Azure Foundry, IBM WatsonX, and Mistral’s own AI Studio, developers have unprecedented flexibility in how they integrate these capabilities.
The release also signals a maturing of the open-weight ecosystem. As Guillaume Lample noted, initial benchmark comparisons can be misleading because “large closed-source models may perform better out-of-the-box, but the real gains happen when you customize.” This highlights the value proposition of open models: the ability to fine-tune and specialize for specific use cases.
The Road Ahead: What’s Next for Open-Weight AI?
Mistral 3 sets a new benchmark for comprehensive model coverage, but the real test will be adoption and fine-tuning. The Apache 2.0 licensing ensures these models will see extensive community development, with specialized variants likely emerging across different domains.
Developer sentiment suggests the next logical step would be filling the mid-range gap, perhaps with a 30B-70B model optimized for the enthusiast hardware market. As one commenter noted, “I wish they’d released something around GLM Air size, around 100B might be nice.”
For now, Mistral has delivered what might be the most practical open-weight AI stack available. Whether this translates into widespread adoption remains to be seen, but the foundation is undoubtedly solid. As one developer summarized: “It’s open weight, European and comes in small variants. Enough for me to welcome all these models.”
The AI landscape just got more interesting, and more accessible.