
T5Gemma 2: Google’s Encoder-Decoder Revival Challenges the Decoder-Only Orthodoxy
Everyone thinks encoder-decoder architectures have been relegated to machine translation museums while decoder-only transformers rule the AI frontier. Google just called that assumption into question with T5Gemma 2, a family of models that resurrect the encoder-decoder pattern with two deceptively simple architectural tweaks: tying embeddings across encoder and decoder, and merging self-attention with cross-attention into a single operation. The result? Models that process text and images with up to 128K context windows using as few as 370M parameters.
This isn’t nostalgia engineering. T5Gemma 2 outperforms its decoder-only Gemma 3 counterparts across most benchmarks while consuming less memory and enabling faster inference. For developers building on-device AI or specialized multimodal systems, that efficiency advantage could be the difference between shipping and shelving a project.
The Architecture: Two Tricks That Change Everything
The more radical innovation is merged attention. Traditional encoder-decoder models stack separate self-attention and cross-attention layers in each decoder block. T5Gemma 2 collapses these into a unified operation that simultaneously attends to the decoder’s own history and the encoder’s representation of the input.
| Setting | Performance | #Parameters |
|---|---|---|
| Baseline | 47.8 | 4417M (1180M) |
| w/ Tied Embedding | 47.7 | 4417M (590M) |
| w/ Merged Attention | 47.5 | 4049M (1180M) |
| w/ Cross Attention on Global Layers Only | 46.5 | 4233M (1180M) |
The numbers reveal the engineering sweet spot: tied embeddings cut embedding parameters in half with virtually no quality loss, while merged attention sacrifices only 0.3 performance points for a 6.5% total parameter reduction. The rejected ablation, applying cross-attention only to global layers, shows why partial solutions fail, dropping performance by a full point.
Multimodal and Long Context: Where Encoder-Decoder Shines
The model handles 128K token contexts using Gemma 3’s alternating local and global attention pattern. For long-context tasks, the separate encoder architecture proves decisive. A dedicated encoder with bidirectional attention on the full context creates richer representations than causal masking ever could. The decoder then cross-attends to these pre-digested representations, making long-context inference more efficient than decoder-only models that must propagate information through thousands of token positions.
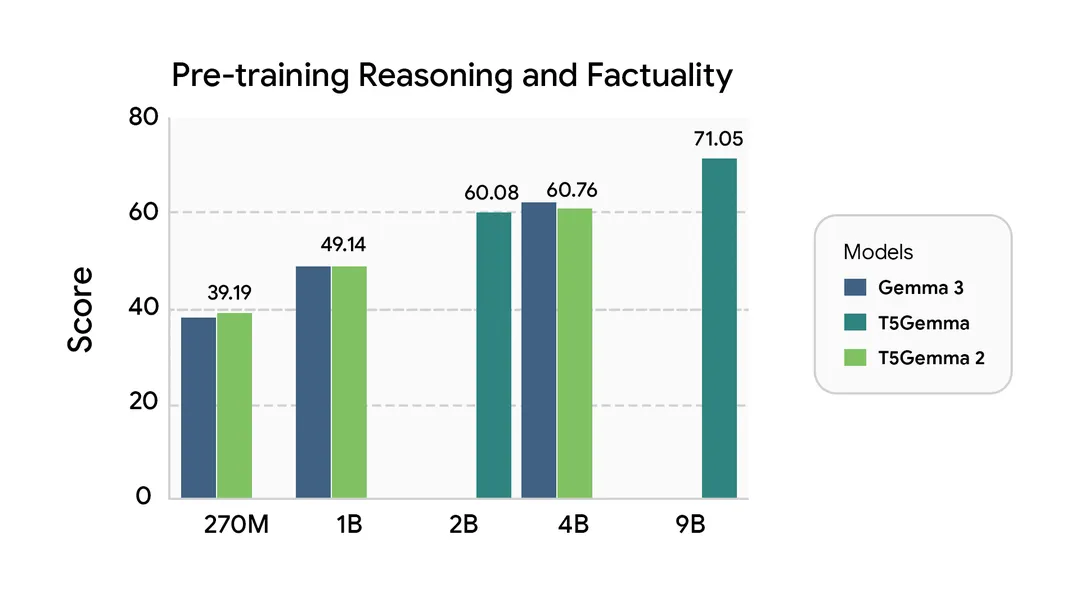
The performance curves show T5Gemma 2 4B-4B nearly matching Gemma 3 4B on reasoning tasks while using a more parameter-efficient architecture. More impressively, the 270M-270M and 1B-1B variants, adapted from text-only Gemma 3 checkpoints, deliver respectable multimodal performance despite never seeing images during their base model training.
Community Reaction: Surprise, Skepticism, and Strategic Questions
The discussion quickly turned pragmatic. Experienced practitioners noted that function calling, a critical capability for AI agents, maps naturally to encoder-decoder architectures. The encoder processes the conversation state and available tools, the decoder generates the function call. This makes T5Gemma 2 a stealth contender for building local AI agents that can control APIs without shipping massive models to edge devices.
Some developers viewed the release as strategic positioning rather than pure research contribution. The observation that Google has “little incentive to drop the 100B MoE everyone wants” reflects broader industry tension between open research and competitive advantage. Still, the availability of efficient 270M and 1B models unlocks applications that would be impossible with larger checkpoints.
Performance: The Numbers That Matter
| Capability | Benchmark | Gemma 3 4B | T5Gemma 2B-2B | T5Gemma 2 4B-4B |
|---|---|---|---|---|
| Reasoning | HellaSwag | 74.9 | 74.8 | 77.4 |
| STEM/Code | MMLU-Pro | 28.9 | 30.7 | 33.2 |
| Multilingual | XQuAD (all) | 68.1 | 58.0 | 70.6 |
| Multimodal | COCO Caption | 101.8 | – | 105.4 |
| Long Context | RULER 32K | 66.8 | 0.2 | 81.7 |
The pattern is clear: T5Gemma 2 matches or exceeds Gemma 3 performance despite the architectural constraints. The long-context results are particularly stark, T5Gemma 2 4B-4B scores 81.7 on RULER 32K where Gemma 3 4B hits 66.8, and the gap widens at 128K contexts.
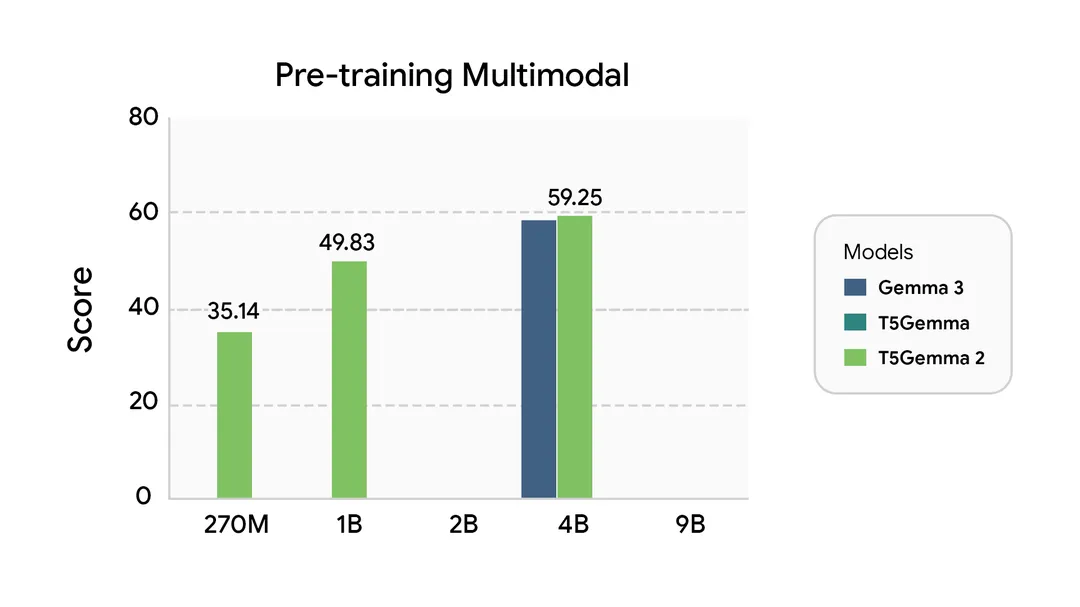
The multimodal benchmarks reveal another surprise: even the smallest T5Gemma 2 variant, built from a text-only Gemma 3 270M base, manages 35.1 average score across vision tasks. This suggests the encoder-decoder structure itself facilitates vision-language understanding, independent of pretraining data.
Fine-Tuning and Practical Deployment
For function calling scenarios, the architecture shines. The encoder digests the full conversation and available function signatures. The decoder, constrained by grammar or syntax, generates valid JSON or API calls. The community has already built tools to streamline this process, including notebooks for multi-turn tool calling and mobile action integration.
Post-training results (Table 5) show T5Gemma 2’s fine-tuning potential. With minimal supervised fine-tuning, no RL, no distillation from larger teachers, the 4B-4B model achieves 63.1 average on STEM/code tasks, outperforming Gemma 3 4B’s 60.9. The encoder-decoder structure appears to accelerate learning from limited downstream data, a crucial property for specialized applications.
Strategic Implications: Efficiency as a Feature
The tied embeddings and merged attention innovations directly address deployment constraints. A 370M parameter model that can handle 128K context and process images opens doors for:
– On-device document analysis
– Local AI assistants with tool use
– Privacy-preserving multimodal apps
– Edge computing scenarios where bandwidth is precious
This efficiency-first approach contrasts with the “bigger is better” arms race. Rather than matching GPT-4 or Gemini parameter-for-parameter in the open weights space, Google is optimizing for a different metric: capability per parameter.
The decision to release only pretrained models reinforces this strategy. Google provides the foundation, the community builds specialized solutions. It’s a分工 that acknowledges frontier model training is too expensive for pure open-source altruism, but efficient adaptation remains valuable for everyone.
The Bottom Line: A Niche Worth Watching
The merged attention mechanism simplifies inference. Tied embeddings shrink memory footprints. The encoder-decoder structure naturally fits transduction tasks. Combined with robust multimodal and long-context support, these features create a compelling toolkit for edge AI.
For organizations building AI agents, document processing pipelines, or multilingual translation systems, T5Gemma 2 deserves a hard look. The architecture trades raw generative power for efficiency and control, exactly what many production systems need.
The developer community’s initial skepticism may give way to pragmatic adoption as benchmarks demonstrate real-world advantages. When RAM is measured in hundreds of megabytes, not hundreds of gigabytes, every parameter counts. T5Gemma 2 counts them smarter.
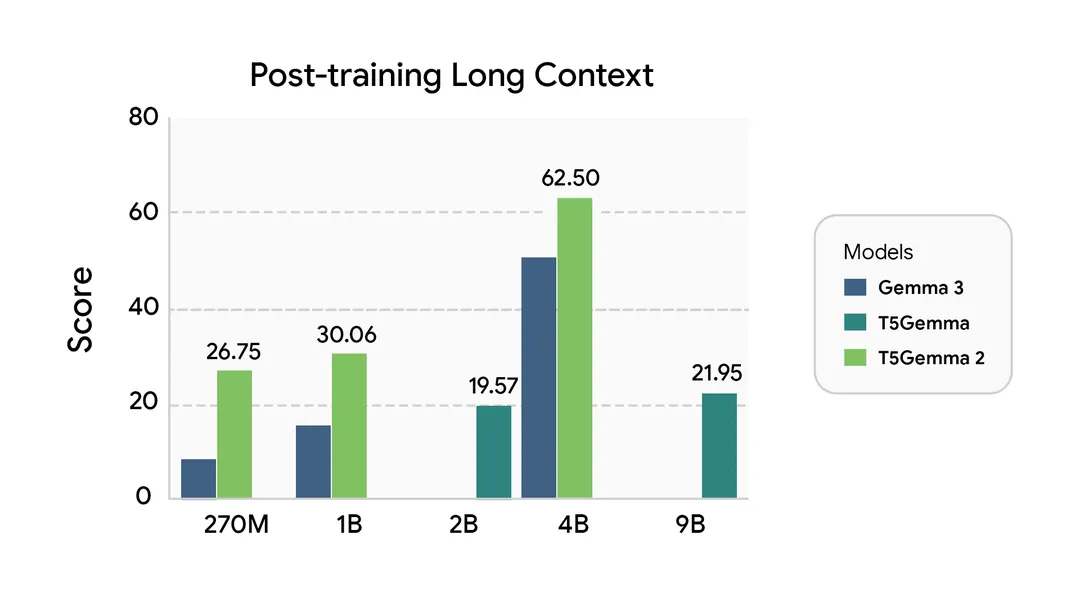
The long-context comparison tells the story: at 128K tokens, T5Gemma 2 4B-4B maintains 57.6 performance while Gemma 3 4B drops to 51.7. For applications processing long documents or extended conversations, that gap could determine user experience quality.
Getting started requires minimal friction: models are available on Hugging Face, Kaggle, and Vertex AI. The example notebook demonstrates basic usage, and the paper provides full architectural details.
Whether encoder-decoder models stage a full comeback or remain a specialized tool, T5Gemma 2 proves the architecture still has room to innovate, and efficiency is a feature that never goes out of style.



