
The Trojan Horse in Your Timeline
Another day, another multimodal model release. You’ve seen this movie before: a Chinese AI lab drops an open-source vision model, the benchmarks look suspiciously cherry-picked, and the “native function calling” claim gets buried under a mountain of marketing speak.
Except this time, the community isn’t just nodding along. The Reddit thread on r/LocalLLaMA hit 373 upvotes in under a day, with developers actually excited, not because of the 108B parameter behemoth, but because of its 9B Flash sibling that runs on consumer hardware. Something’s different here.
GLM-4.6V isn’t just another VLM. It’s Zhipu AI’s attempt to solve the fundamental problem that’s been plaguing AI agents: the translation tax between what models see and what they do.
The Vision-Action Gap Nobody Wants to Talk About
Let’s be blunt: current “multimodal agents” are duct-taped together. You take a vision model, convert images to text descriptions, feed that into an LLM, have the LLM decide on function calls, execute those calls, then maybe convert the results back into images. Each conversion step introduces latency, errors, and context loss.
The research team at Z.ai identified this bottleneck explicitly in their technical documentation. Their breakthrough isn’t just adding vision to a language model, it’s integrating native function calling directly into the multimodal architecture. This means images, screenshots, and document pages pass directly as tool inputs without text conversion, while visual outputs (charts, rendered pages, search results) feed back into the reasoning chain.
This isn’t semantic sugar. It’s a structural rethinking of how multimodal models should operate.
Two Models, One Goal: Actually Useful AI
Zhipu AI released two versions, and this dual-strategy tells you everything about their target audience:
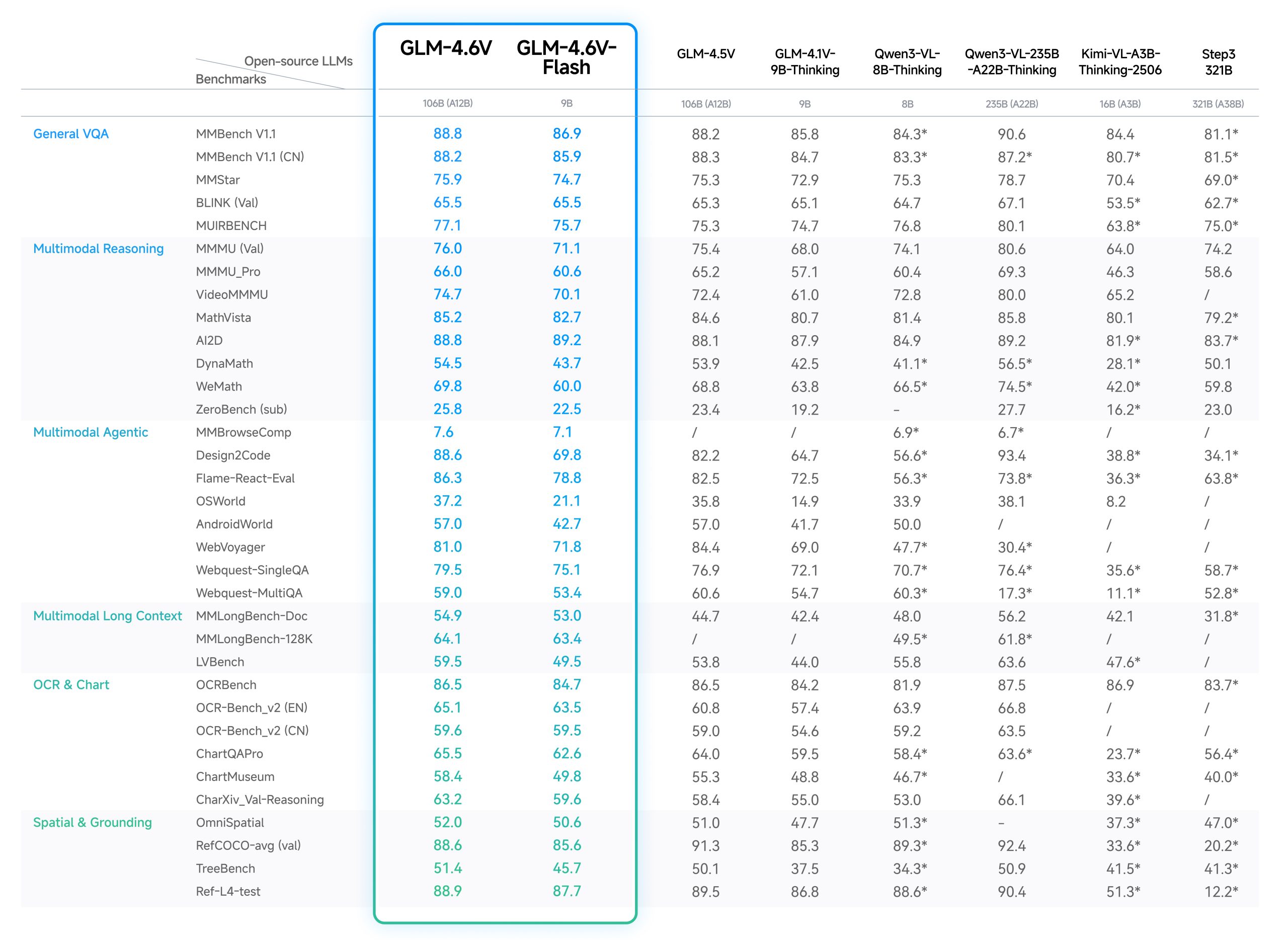
GLM-4.6V (108B): The cloud workhorse for companies that measure their compute budget in mortgage payments. It scales to 128K tokens and achieves SOTA performance on MMBench, MMStar, and the usual benchmark suspects.
GLM-4.6V-Flash (9B): The real disruptor. Optimized for local deployment with low-latency applications, it’s what actually gets developers excited. As one Reddit commenter noted, “It seems like only Mistral, Qwen and Z.AI remember the sub 10B model sizes.”
The community’s reaction is telling. While the 108B version gets polite nods, the Flash model sparks discussions about running it on consumer GPUs, fine-tuning costs, and edge deployment scenarios. This reflects a growing frustration with the “bigger is better” arms race that leaves independent developers priced out of innovation.
Native Function Calling: Technical Reality Check
Here’s where things get spicy. The term “native function calling” gets thrown around like confetti at a tech conference, but GLM-4.6V’s implementation actually deserves the label.
The architecture allows direct visual tool use, meaning the model can:
- Take a screenshot of a UI as input
- Identify a button element visually
- Generate a function call to click that coordinate
- Process the resulting updated screenshot
- Continue reasoning without converting anything to text
This closes the perception-action loop that has hobbled previous agent frameworks. In benchmark evaluations, GLM-4.6V shows particularly strong performance on agentic tasks like Design2Code, WebVoyager, and AndroidWorld, tasks that require acting on visual information, not just describing it.
The code implementation reflects this design:
from transformers import AutoProcessor, Glm4vMoeForConditionalGeneration
import torch
MODEL_PATH = "zai-org/GLM-4.6V-Flash"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://example.com/screenshot.png"
},
{
"type": "text",
"text": "Click the login button and extract the resulting URL"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH)
model = Glm4vMoeForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype="auto",
device_map="auto"
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
# The model can now reason about the image and generate function calls
generated_ids = model.generate(**inputs, max_new_tokens=8192)The key difference? The function calling mechanism operates directly on the multimodal embedding space, not as a separate text-generation step.
The Performance Tradeoff Elephant in the Room
But here’s the controversial part that nobody on Z.ai’s marketing team is tweeting about: vision capabilities come at a cost.
A Reddit commenter raised the critical question: “How much does adding vision onto a text model take away from the text performance?” This is the dirty secret of multimodal models. With fixed parameter counts, every million tokens of visual understanding capacity is a million tokens not dedicated to text reasoning.
The Z.ai team acknowledges this in their documentation, noting that “pure text QA capabilities still have significant room for improvement.” They optimized for visual multimodal scenarios during training, which means text-only tasks may see degradation compared to text-focused models like GLM-4.6-Air (which, notably, never materialized as a separate release).
Empirically, studies on similar multimodal models show a 1-3% degradation on text benchmarks. The community is already debating whether vision actually enhances text performance through richer world understanding, or if it’s just a capacity drain. The truth likely depends on the task, visual grounding helps with spatial reasoning but might hurt pure logical deduction.
Community Verdict: Hope Mixed with Skepticism
The developer response has been refreshingly pragmatic. On the llama.cpp GitHub PR, contributors are actively working on support, with one noting they’ve successfully stripped vision layers from older GLM-V models to create text-only versions.
This reveals a deeper trend: modularity is becoming a requirement, not a feature. Developers want the ability to selectively enable capabilities based on their use case and hardware constraints. The fact that GLM-4.6V’s architecture allows for vision layer removal suggests Z.ai understands this, even if it’s not front-and-center in their marketing.
The Reddit discourse is equally revealing. Comments about “the sub 10B model sizes” being forgotten by most labs highlight a community fatigue with inaccessible AI. Z.ai’s decision to release a competitive 9B model alongside their flagship is being celebrated as a recognition that democratization matters.
The Real Controversy: Are We Ready for Agents That Actually Act?
But here’s what should keep AI safety folks up at night: GLM-4.6V’s native function calling doesn’t just make agents more capable, it makes them more autonomous in ways we’re not prepared for.
When a model can:
– Parse a screenshot of your bank account
– Identify the “transfer funds” button
– Execute that action based on a spoken command
– Verify success by reading the confirmation screen
…you’ve crossed from “helpful assistant” into “unlicensed financial operator” territory. The current function calling framework lacks the granularity for nuanced permission systems. It’s either “can call any function” or “can’t call functions at all.”
The AI community’s obsession with capability benchmarks has outpaced our development of governance frameworks. GLM-4.6V’s technical achievement is undeniable, but it arrives before we’ve solved the preceding model’s alignment problems.
How to Actually Use This Thing (If You Dare)
For the brave souls ready to experiment, here’s the practical path:
For cloud deployment:
# Install via vLLM
pip install vllm>=0.12.0
pip install transformers>=5.0.0rc0
# Or SGLang for better multimodal performance
pip install sglang>=0.5.6.post1For local inference:
The Flash model runs on a single RTX 4090 with quantization:
# llama.cpp support is in development
# Track progress here: https://github.com/ggml-org/llama.cpp/pull/16600For API access:
from openai import OpenAI
client = OpenAI(
api_key="<z.ai-api-key>",
base_url="https://open.bigmodel.cn/api/paas/v4/"
)
response = client.chat.completions.create(
model="glm-4.6v",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "screenshot.png"}},
{"type": "text", "text": "What happens if I click the blue button?"}
]
}
]
)The Novita AI integration offers an OpenAI-compatible endpoint with build-in discounts during their Build Month promotion, making it the fastest path to production if you trust third-party model hosting.
The Questions Nobody’s Asking (But Should Be)
-
Legal liability: When GLM-4.6V misinterprets a visual element and executes a destructive function call, who’s responsible? The user who provided the screenshot? Z.ai? The platform hosting the model?
-
Security implications: How do we prevent adversarial images designed to trigger specific function calls? A carefully crafted icon on a malicious website could theoretically instruct the model to extract and exfiltrate data from other tabs.
-
The text performance sacrifice: Are we entering an era where “multimodal” becomes a euphemism for “mediocre at everything”? The 1-3% text degradation might seem minor until you scale it across millions of API calls.
-
Open source vs. open weights: Z.ai released the weights under MIT license, but the training data and full pipeline remain proprietary. Is this “open source” in any meaningful sense, or just a savvy marketing play?
Bottom Line: Infrastructure, Not Innovation
GLM-4.6V’s most significant contribution isn’t a novel architecture, it’s treating native multimodal function calling as a requirement rather than a feature. The vision-action gap has been the dirty secret holding back agentic AI, and Z.ai is forcing everyone else to address it.
The 9B Flash model’s existence is arguably more important than the 108B flagship’s benchmark scores. It suggests Zhipu AI understands that useful AI must be accessible AI, a lesson Western labs seem to have forgotten in their race to trillion-parameter models.
But let’s not confuse infrastructure with enlightenment. GLM-4.6V gives us better tools to build agents that see and act. It does nothing to solve the fundamental questions of whether we should and how we control them.
The models are available on HuggingFace and Z.ai’s platform. Try them. Benchmark them. But don’t mistake technical capability for wisdom.
The real controversy isn’t what GLM-4.6V can do, it’s that we’re deploying it before answering the more important question: what happens when it works exactly as designed?



