The Databricks Exit: Why Broke Teams Are Building Better Data Stacks on Kubernetes
The email came down on a Tuesday: “Azure Databricks budget frozen until further notice.” By Wednesday, a data engineering team that had architected its entire pipeline around managed Spark clusters was scrambling for alternatives. By Friday, they had a working prototype on Kubernetes. Three months later, they realized they weren’t going back, not because they couldn’t afford Databricks, but because the open-source stack they’d built was actually better.
This isn’t a hypothetical. It’s playing out across the industry as economic pressures force a brutal reassessment of cloud spending. The real surprise? The teams being forced off platforms like Azure Databricks aren’t just surviving, they’re discovering that composable, open-source architectures offer freedoms that managed platforms never could.
The Budget Cut That Launched a Thousand Migrations
The catalyst is depressingly common. A Reddit post from a data engineering team laid it bare: promised Azure services evaporated when funds were cut. No more Databricks. No more Azure Data Factory. Just a mandate: rebuild everything open-source, on Kubernetes, for a fraction of the cost.
Their proposed stack reveals how the mindset shifts when vendor lock-in is no longer an option:
- Orchestration: Dagster instead of Azure Data Factory
- Data processing: Polaris (or Trino) instead of Databricks Spark
- Storage: Postgres with pgvector and pg_duckdb extensions
- Vector search: Chroma or pgvector instead of proprietary embeddings stores
- Ingestion: DLT (data load tool) for robust pipeline management
- Data lake: MinIO (though its maintenance mode status has teams eyeing alternatives)
- Transformations: dbt Core for SQL-based modeling
- Catalog: DataHub for metadata management
This isn’t just a cost-cutting exercise, it’s a fundamental re-architecting around composability. And the data suggests this is becoming the norm, not the exception.
The Open-Source Data Platform Isn’t a Theory, It’s a Fact
According to recent research, 96% of organizations maintained or increased their open-source use over the previous year, with more than a quarter reporting significant increases. Linux Foundation research shows 40, 55% penetration of open source in mission-critical domains, including databases and AI.
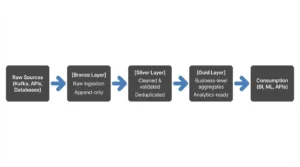
The monolithic data warehouse, or a single proprietary cloud database, is struggling to keep up with AI projects demanding fresh data, edge systems generating continuous streams, and regulators expecting fine-grained control over where data lives. The response? A modular, composable data stack where compute engines, storage layers, and orchestration tools evolve independently.

The “One Person Army” Problem Nobody Talks About
Here’s where the conversation gets uncomfortable. A top-voted comment on the Reddit thread captured the dark humor of modern data teams:
“We want a robust platform with full observability to serve multiple workloads including BI, Analytics, and ML/AI. We want 1 person with a masters degree and 10+ years experience to handle management, architecture, governance, engineering, ML/AI, analytics, devops, and project management. Also, we don’t want to actually pay for it.”
The reply was telling: “Ha that pretty much describes me except they are willing to pay a little (mostly they’re paying me).”
This is the hidden cost of the open-source “savings.” Yes, you’re not paying Databricks’ per-DBU pricing. But you’re paying in expertise, deep, broad expertise that spans infrastructure, data engineering, MLOps, and domain knowledge. The TCO calculation isn’t just infrastructure, it’s the salary of the unicorn engineer who can keep this stack running.
The math gets interesting when you model it out. A mid-sized Databricks deployment might cost $50,000/month. That’s $600K annually. A senior data engineer with the skills to manage an open-source stack might cost $200K. Add another $100K for managed Kubernetes and storage. You’re still saving $300K annually, but you’re also now critically dependent on a small number of people who understand the entire system.
Kubernetes: The New Foundation for Data Infrastructure
The Reddit thread specified everything must sit on Kubernetes. This isn’t accidental, it’s recognition that Kubernetes has become the de facto operating system for modern infrastructure. And it’s evolving rapidly to support AI workloads.
Kubernetes 1.34 introduced dynamic resource allocation (DRA), which fundamentally changes how GPU resources are requested. Instead of simply asking for “2 GPUs”, you can now specify GPU types, configurations, and even partial GPU allocations. It’s the difference between renting a car and specifying exactly the engine, transmission, and features you need.
An upcoming workload abstraction will enable smart scheduling for distributed AI training, allowing Kubernetes to express constraints like “all pods must start simultaneously or not at all.” For teams running Trino or Polaris for distributed query processing, this is a game-changer.

The Managed Open-Source Middle Path
Smart teams aren’t going fully DIY. They’re leveraging managed open-source services that preserve architectural control while offloading operational burden:
- NetApp Instaclustr: Curated, production-grade operations for Kafka, Cassandra, PostgreSQL
- Confluent Cloud: Fully managed Kafka with standard APIs, allowing workload portability
- Aiven: Multi-cloud managed PostgreSQL, Kafka, OpenSearch, ClickHouse with unified configuration
The key distinction: when underlying technologies remain truly open, governed by neutral foundations and standard licenses, organizations can change operators, move workloads, or bring operations back in-house. You’re not locked into a vendor’s roadmap, you’re buying operational expertise for a component you could theoretically run yourself.
This is the “composable data stack” vision: managed where it makes sense, self-managed where it differentiates your business. The data lives in open formats (Parquet, Iceberg) accessible via standard protocols. Engines like Kafka and PostgreSQL run anywhere. New tools, vector databases, AI feature stores, plug in without redesigning the entire platform.
The Real Cost Equation: It’s Not Just About Money
Let’s be brutally honest. Databricks is expensive because it works. You get a fully integrated platform with Spark, Delta Lake, MLflow, and governance features that just work together. The moment you move to open-source alternatives, you inherit integration as your full-time job.
Consider the stack complexity:
- Dagster for orchestration (replacing ADF)
- Polaris/Trino for query engine (replacing Spark)
- Postgres with pgvector and pg_duckdb extensions (replacing multiple databases)
- Chroma or pgvector for vector search
- MinIO (or alternatives) for object storage
- dbt Core for transformations
- DataHub for catalog
Each tool is excellent at its job. But the seams between them? That’s where engineering hours disappear. Data lineage across systems. Unified access controls. Consistent monitoring and alerting. These aren’t features, they’re full-time engineering projects.
The Reddit comment about being a “one man army” isn’t a joke, it’s a warning. The composable stack demands expertise in:
- Kubernetes administration and cost optimization
- Distributed query engine tuning
- Vector database scaling strategies
- MLOps pipeline reliability
- Data governance across disparate systems
- Security and compliance auditing
The AI Workload Wildcard
Here’s where the open-source stack shows its real power. Databricks’ optimized Spark runtime is fantastic for ETL and batch analytics. But modern AI workloads, especially those involving large language models, vector search, and real-time feature serving, require specialized tools that Databricks’ monolithic architecture struggles to accommodate.
The open-source stack embraces polyglot persistence by design:
- Postgres + pgvector handles transactional data and embeddings in one system
- Chroma offers specialized vector search with hybrid retrieval
- DuckDB provides lightning-fast local analytics for data exploration
- Polars delivers DataFrame operations that can run in-process or distributed
For AI teams, this flexibility is non-negotiable. You can’t shoehorn a RAG pipeline into a Spark-only mindset. You need the right tool for each job, with Kubernetes providing the unified operational layer.
The Verdict: Replace Databricks? Yes, But…
Can open-source stacks on Kubernetes replace Azure Databricks? Absolutely, but only if you understand what you’re trading.
You’re trading:
- Predictable costs for unpredictable engineering time
- Integrated features for composable flexibility
- Vendor support for community expertise
- Rapid onboarding for steep learning curves
The teams succeeding with this transition aren’t just cost-cutting, they’re strategically re-architecting for AI-native workloads that Databricks wasn’t built for. They’re leveraging Kubernetes’ dynamic resource allocation for GPU workloads. They’re using open table formats like Iceberg to avoid lock-in. They’re building data platforms where compute and storage truly scale independently.
The failure mode is clear: teams that treat this as a lift-and-shift, replacing Databricks with a hodgepodge of open-source tools without addressing operational complexity, end up with a fragile, unmaintainable mess and one burned-out engineer.
What Leaders Should Actually Do
-
Be honest about your team’s expertise. If you have a “one person army”, invest in their success with managed services where it matters. Don’t burn them out saving a few thousand dollars.
-
Start with the data, not the tools. Define your data products first, BI dashboards, ML models, real-time analytics. Then map them to the composable stack. Don’t build infrastructure for its own sake.
-
Embrace the 80/20 rule. Use managed open-source for 80% of your operational needs. Self-manage only the 20% that truly differentiates your business.
-
Invest in observability from day one. The seams between tools are where data quality dies. You need unified logging, monitoring, and lineage across the entire stack.
-
Think in terms of data planes, not data warehouses. The future is polyglot persistence with Kubernetes as the control plane. Design for portability, not perfection.
The open-source data stack on Kubernetes isn’t a cheaper Databricks, it’s a fundamentally different architecture. One that trades integration for composability, vendor lock-in for architectural freedom, and predictable costs for unpredictable complexity.
Whether that’s a good trade depends entirely on whether you’re optimizing for cost savings or competitive advantage. The teams winning with this approach aren’t saving money, they’re building data platforms that managed services can’t offer at any price.
The real question isn’t “Can open source replace Databricks?” It’s “What kind of data platform do you need to build, and are you willing to pay the real cost, whether that’s in dollars or engineering sweat?”
The data stack wars are just beginning. Where do you land: team managed platform or team composable chaos?