Alibaba’s FunAudioLLM team just dropped CosyVoice 3, and the claims are bold: nine languages, zero-shot voice cloning, 150ms bi-streaming latency, and “production-ready” performance. The benchmarks look impressive, 0.81% character error rate on Chinese, 78% speaker similarity, training on one million hours of audio. But here’s what the Hugging Face page won’t tell you: getting it to sound as good as the demo requires patience, precise configuration, and a tolerance for occasional hallucinations.
The gap between “works in the lab” and “works in the wild” has plagued text-to-speech for years. CosyVoice 3 might be the first open-source model to genuinely narrow that gap, but it’s also a masterclass in why “production-ready” is a loaded term.
The “In-the-Wild” Problem Nobody Talks About
Most TTS models are benchmarked on clean audiobook data with perfect punctuation and neutral accents. Real-world audio is messy: spontaneous speech, code-switching, background noise, emotional inflections, and text that ranges from informal tweets to technical documentation. CosyVoice 3’s core innovation is its training paradigm: instead of just learning pronunciation, its speech tokenizer is trained simultaneously on automatic speech recognition, emotion recognition, language identification, audio event detection, and speaker analysis.
This multi-task approach means the model doesn’t just learn what to say, it learns how to say it in context. The result is a system that handles numbers, symbols, and varied text formats without a traditional frontend module. When it works, the prosody naturalness surpasses even some commercial systems.
But “when it works” is doing a lot of heavy lifting. Early adopters report that CosyVoice 3 can be temperamental. One developer noted that Russian language synthesis “sounded like gibberish” out of the box, requiring additional tinkering. Another observed that while the model produces clearer audio than competitors when everything aligns, it occasionally inserts unnatural pauses between words and requires multiple attempts to avoid hallucinations.
Voice Cloning: Brilliant When It Aligns, Frustrating When It Doesn’t
The zero-shot voice cloning capability is genuinely impressive, 10 seconds of reference audio is enough to synthesize speech in a different language while preserving vocal identity. Theoretically. In practice, the model demands precision: you need both the audio sample and an accurate text transcription of what was said in that sample. Get the transcription wrong, and the output degrades into noise.
This isn’t a bug, it’s a feature of how the system maintains content consistency. The model uses the reference text as a grounding mechanism, ensuring the cloned voice doesn’t drift. But it also means voice cloning isn’t as “zero-shot” as marketed. You’re not just dropping in audio, you’re curating a mini-dataset.
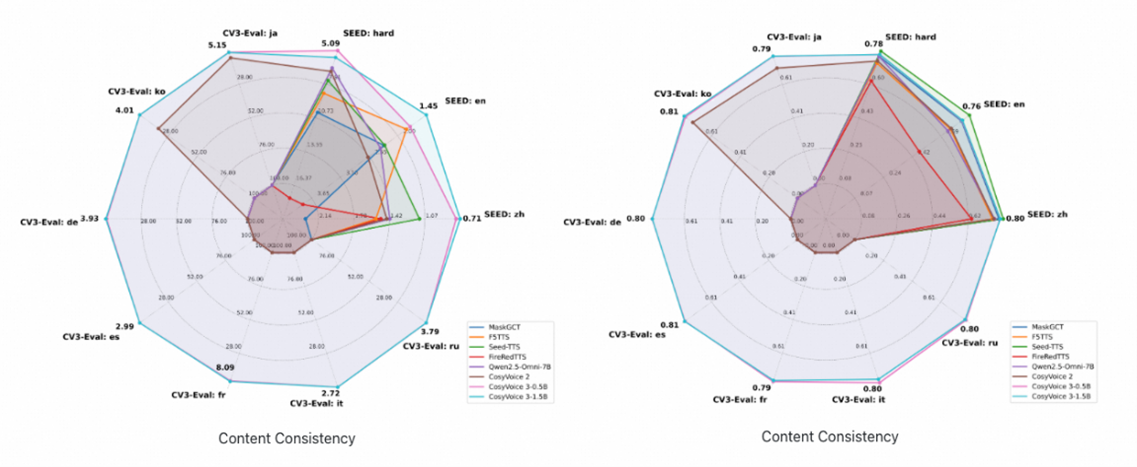
The evaluation metrics bear this out. On the challenging “test-hard” set, CosyVoice 3 achieves 5.44% CER, significantly better than CosyVoice 2’s 6.83% but still far from perfect. For comparison, the RL-tuned version drops this to 5.44% CER while maintaining 75% speaker similarity, a trade-off that might matter more for production systems than raw accuracy.
The Chatterbox Shadow
No discussion of CosyVoice 3 is complete without addressing the elephant in the room: Chatterbox Turbo. The Reddit community has already drawn battle lines. One tester put it bluntly: “Chatterbox turbo is much faster, more stable and has a more natural intonation. CosyVoice hallucinates more and quite often takes multiple attempts to get a hallucination-free output.”
Another user pushed back, noting that CosyVoice’s Japanese performance exceeded Chatterbox’s older multilingual model, while a third dismissed Turbo as “english only, what a joke.”
The reality is more nuanced. Chatterbox Turbo prioritizes stability and naturalness for English, while CosyVoice 3 optimizes for flexibility and multilingual coverage. The benchmarks reflect this: CosyVoice 3’s 2.24% WER on English trails some competitors but its 1.21% CER on Chinese leads many open-source alternatives. If your use case is English-only customer service, Chatterbox might be safer. If you need to clone a Mandarin speaker’s voice into Spanish while preserving their Shandong accent, CosyVoice is your only option.
Deployment: Not for the Faint of Heart
Let’s talk about what “production-ready” actually means. The installation process is straightforward for an AI researcher but Byzantine for a typical DevOps engineer:
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
git submodule update --init --recursive
conda create -n cosyvoice -y python=3.10
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
Then download multiple model files:
from huggingface_hub import snapshot_download
snapshot_download('FunAudioLLM/Fun-CosyVoice3-0.5B-2512', local_dir='pretrained_models/Fun-CosyVoice3-0.5B')
snapshot_download('FunAudioLLM/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')Optional but recommended: install the ttsfrd package for better text normalization, which involves unzipping resources and installing platform-specific wheels.
The model runs on a modest 4GB VRAM for the 0.5B version, making it accessible for single-GPU deployment. But optimal performance requires specific PyTorch and cuDNN versions, especially on newer hardware like Blackwell 6000 series cards. One developer reported an hour of troubleshooting just to get Russian working.
For production scaling, the team provides Docker containers, FastAPI servers, gRPC endpoints, and TensorRT-LLM integration promising 4x acceleration. The bi-streaming architecture, processing text input while generating audio output, achieves that touted 150ms latency, but only after you’ve navigated the configuration maze.
The Differentiable Reward Optimization Trick
CosyVoice 3’s secret sauce is DiffRO (Differentiable Reward Optimization), a post-training method that applies reinforcement learning directly to speech tokens rather than full audio waveforms. This makes RL feasible at scale, optimizing for transcribability, emotional expression, and style adherence without the computational nightmare of traditional audio-based reward models.
The result is measurable. The RL-tuned version (Fun-CosyVoice3-0.5B-2512_RL) drops Chinese CER from 1.21% to 0.81% and English WER from 2.24% to 1.68%. Speaker similarity takes a slight hit (78.0% to 77.4% on Chinese), but the trade-off is worth it for applications where accuracy trumps perfect timbre.
This technique is particularly effective for “in-the-wild” scenarios. When the model encounters messy text, think social media posts with emojis, numbers, and slang, DiffRO helps it stay on track instead of hallucinating plausible-sounding but wrong content.
The Geopolitical Undertone
Alibaba releasing a state-of-the-art multilingual TTS as open-source isn’t just a technical milestone, it’s a strategic move. While Western companies gatekeep voice AI behind APIs and usage caps, Chinese labs are dumping fully-trained models onto Hugging Face. The model supports nine languages including Russian, French, and Italian, languages where collecting training data might raise eyebrows in other contexts.
The 18+ Chinese dialects coverage is unprecedented. Most TTS systems treat “Chinese” as Mandarin and call it a day. CosyVoice 3 handles Cantonese, Shanghainese, Sichuanese, and others, reflecting Alibaba’s domestic market needs but also creating a resource the global research community lacked.
This isn’t purely altruistic. It’s a flex that says: we have the data, the compute, and the talent to train models that work across linguistic boundaries you haven’t even considered.
Should You Actually Use This?
Use CosyVoice 3 if:
– You need multilingual or cross-lingual voice cloning
– You’re building a system that must handle messy, real-world text
– You have the ML ops capacity to tune and troubleshoot
– Latency matters, but perfect stability doesn’t
Skip it if:
– You need bulletproof English-only TTS
– You want plug-and-play simplicity
– Your use case can’t tolerate occasional hallucinations
– You lack GPU resources
The model is undeniably powerful. When it works, it produces audio that rivals systems 3x its size. But “production-ready” depends on your production environment. For a research lab or a tech-savvy startup, CosyVoice 3 is a gift. For a Fortune 500 company wanting to deploy customer-facing voice agents next week, it’s a science project.
The benchmarks don’t lie, but they don’t tell the whole truth either. CosyVoice 3 represents a genuine step forward for open-source TTS, particularly in multilingual capabilities. Just don’t expect it to sound like the demo without reading the manual. Twice.