Six months ago, the idea that an open-weight model could compete with Claude Opus or GPT on agentic coding tasks was aspirational at best. Today, it’s a measurable reality, and the numbers are forcing a hard conversation about whether the “open vs. closed” debate is even the right framing anymore.
The Hugging Face blog post that kicked off this discussion asked a deceptively simple question: Is your open model agentic enough? The answer, as of mid-2026, is increasingly “yes”, but only if you know exactly what you’re measuring and why.
The Benchmarking Problem Nobody Wants to Admit
The dirty secret of agentic AI benchmarking is that most published scores are measuring the wrong thing. A model that crushes SWE-Bench Verified might collapse on a real-world task that requires 47 tool calls across 12 minutes of wall-clock time. The reason is structural: agentic workloads are fundamentally different from the single-turn completions that traditional benchmarks test.
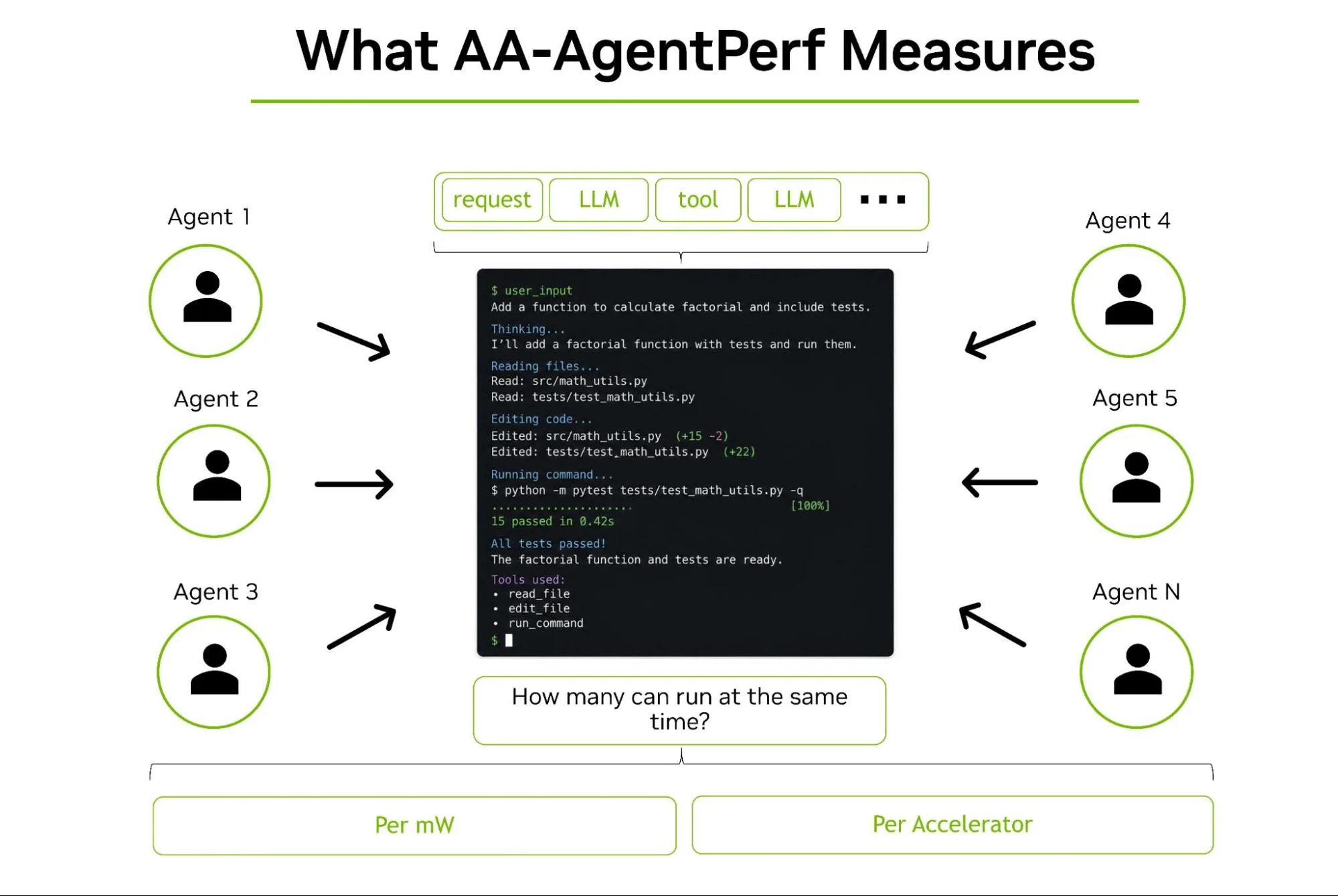
Agentic tasks produce non-deterministic sequences of requests and tool calls. The model’s trajectory, the complete sequence of actions, decisions, and observations as it traverses a task, is what matters, not whether it can write a function in isolation. This is why the new AA-AgentPerf benchmark from Artificial Analysis is such a big deal: it’s the first open, multi-vendor benchmark that measures concurrent AI agent support under real-world coding trajectories, with hardware results normalized per accelerator and per megawatt.
Why Traditional Benchmarks Fail Agentic Workloads
The fundamental problem is that agentic workloads are structurally different from the single-turn completions that most benchmarks test. An agent doesn’t just answer a question, it plans, executes tool calls, reads results, adjusts, and repeats. This non-deterministic sequence of actions is what the AA-AgentPerf benchmark from Artificial Analysis finally captures properly.
The benchmark measures GPU performance across prerecorded agentic coding trajectories with interleaved reasoning and tool use. Sequence lengths range from 5K to 131K tokens, with a mean of approximately 27K. Tool calls are mapped to representative CPU-side tasks with a one-second median delay. The test set is kept private to prevent benchmark-targeted optimization, a crucial design choice that many other benchmarks have failed to make.
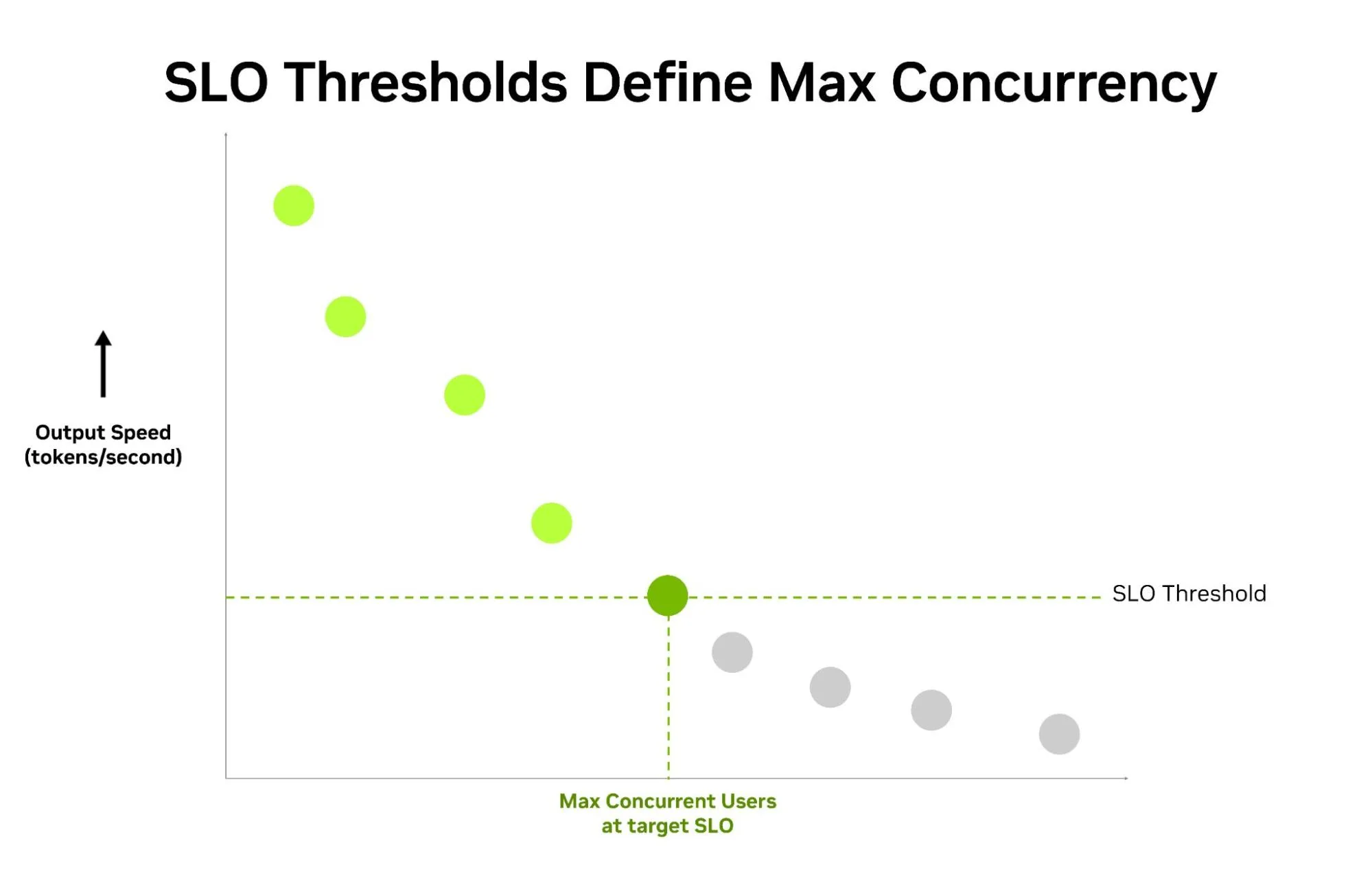
The SLO Framework: Why Speed Alone Is a Trap
The AA-AgentPerf benchmark introduces something most model comparisons ignore: Service Level Objectives (SLOs) that define acceptable performance. A model that generates 300 tokens/second but takes 10 seconds for the first token is useless for interactive agent work. The benchmark enforces strict thresholds across three tiers:
| Model | SLO tier | P25 output speed (tokens/second) | P95 TTFT (seconds) |
|---|---|---|---|
| DeepSeek-V4-Pro | SLO #1 | 30 | 10 |
| SLO #2 | 100 | 5 | |
| SLO #3 | 300 | 3 |
This is the kind of practical constraint that most benchmark comparisons conveniently ignore. A model that scores 85% on SWE-Bench but takes 12 seconds for the first token is useless for interactive agent work. The SLO framework forces you to care about the user experience, not just the final score.
The Open Model Landscape: Who’s Actually Competitive?
The data from mid-2026 paints a clear picture: the gap between open and closed models for agentic tasks has collapsed from a chasm to a crack. Here’s where things stand:
Kimi K2.7 Code: The Token Efficiency Champion
Moonshot AI’s latest release is a 1-trillion parameter MoE model with 32 billion activated parameters. The headline numbers are impressive: +21.8% on Kimi Code Bench v2 (62.0 vs 50.9), +11.0% on Program Bench (53.6 vs 48.3), and +31.5% on MLS Bench Lite (35.1 vs 26.7). But the real story is the 30% reduction in thinking-token usage compared to K2.6. For teams running high-volume agentic pipelines, that efficiency compounds into real cost savings.
On agentic benchmarks, K2.7 Code shows roughly 10% improvement over K2.6 across Kimi Claw 24/7 Bench, MCP Atlas, and MCP Mark Verified. The MCP Mark Verified score of 81.1 actually beats Claude Opus 4.8’s 76.4, a genuinely differentiated capability for tool-call-heavy workflows.
GLM-5.2: The Open-Weight Model That Changes the Conversation
If Kimi K2.7 is the efficiency play, GLM-5.2 is the capability play. Released June 13, 2026 by Z.ai (formerly Zhipu AI), this 753-billion parameter MoE model with MIT licensing scores 62.1% on SWE-bench Pro and 81.0% on Terminal-Bench 2.1. That puts it within four points of Claude Opus 4.8 on the latter benchmark and ahead of GPT-5.5 on both.
The cost difference is staggering: GLM-5.2 at $1.40 per million input tokens and $4.40 per million output tokens, roughly one-sixth the cost of Claude Opus 4.8. For a team running thousands of agentic coding sessions per month, that’s not a rounding error, it’s a budget line item.
Ornith-1.0: The Self-Scaffolding Wildcard
The most architecturally interesting release of June 2026 might be Ornith-1.0 from DeepReinforce. The key innovation is that the model learns its own agent scaffold during reinforcement learning post-training, rather than relying on human-designed harnesses. The 397B MoE variant scores 77.5 on Terminal-Bench 2.1 and 82.4 on SWE-Bench Verified, putting it in the same band as Claude Opus 4.7 and DeepSeek-V4-Pro.
The 35B variant is arguably more impressive: it beats Qwen3.5-397B on Terminal-Bench 2.1 (64.2 vs 53.5), a 397B-class model, despite having 10x fewer active parameters. That’s the kind of efficiency gain that makes you rethink your entire infrastructure strategy.
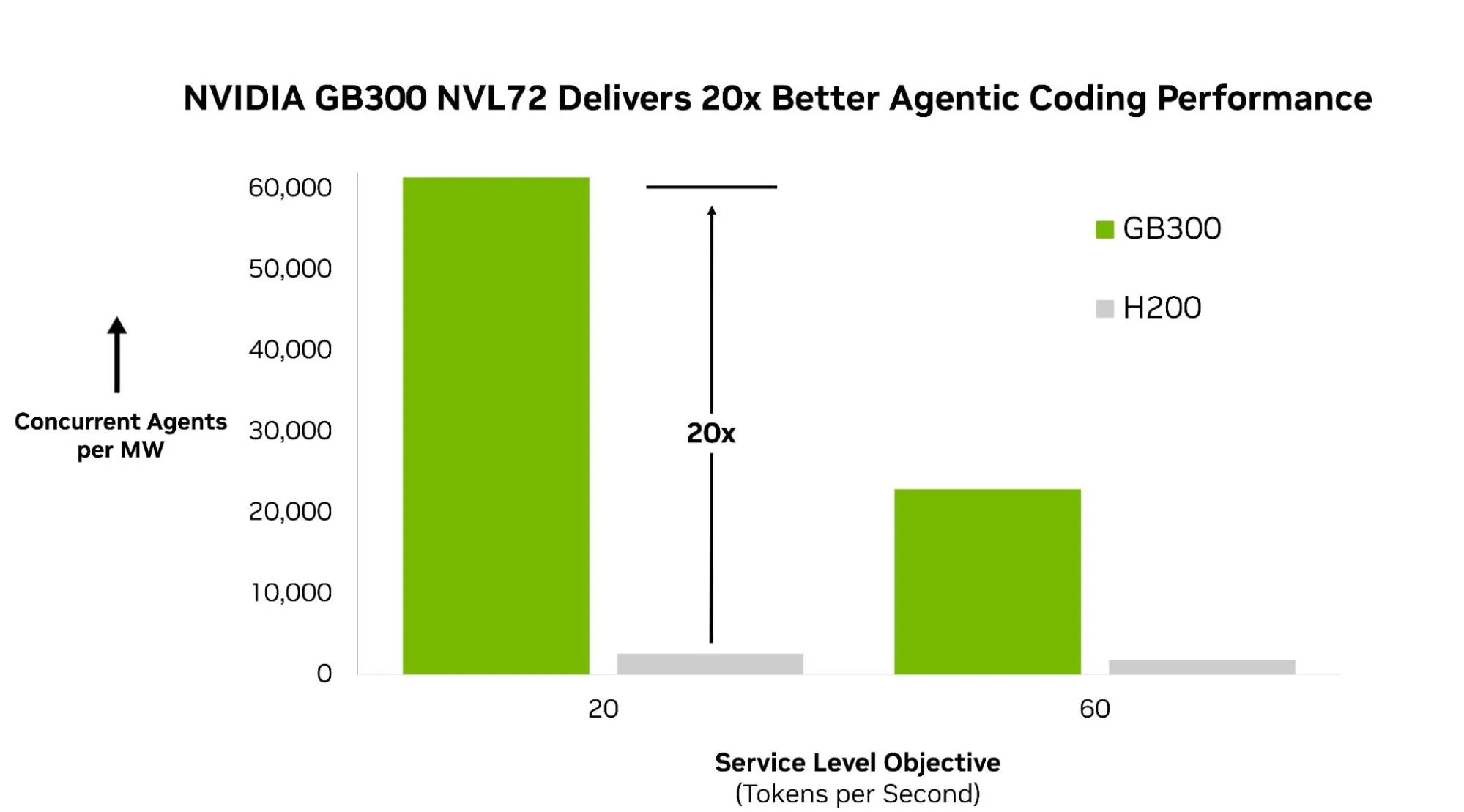
The Infrastructure Reality Check
All this benchmark talk is meaningless if you can’t actually run these models. The AA-AgentPerf benchmark provides the most practical data here: NVIDIA GB300 NVL72 delivers up to 20x more concurrent agents per megawatt than the previous generation H200. At SLO #1 (30 tokens/second output, 10-second TTFT), the GB300 supports 61.4K concurrent agents per megawatt versus the H200’s 2.6K.
| Benchmark | Value of metric | NVIDIA GB300 NVL72 | NVIDIA H200 |
|---|---|---|---|
| Concurrent agents per MW | Energy efficiency | 61.4K | 2.6K |
| Concurrent agents per GPU | Hardware efficiency | 57.5 | 1.4 |
For teams building production agent systems, this is the data that actually matters. A model that scores 85% on SWE-Bench but requires 10x the infrastructure cost to serve at scale is not a practical choice.
The Practical Benchmarking Framework
If you’re building agentic systems today, here’s the framework I recommend based on the data:
-
Start with your SLOs, not the model. Define your acceptable output speed and time-to-first-token before you look at any benchmark. A model that scores 85% on SWE-Bench but takes 8 seconds for the first token is useless for interactive agents.
-
Test on your actual trajectories. The AA-AgentPerf approach of using prerecorded agentic trajectories with interleaved tool calls is the right methodology. If you can’t run that benchmark, at minimum test with your own tool-call patterns and sequence lengths.
-
Measure cost per completed task, not cost per token. A model that uses 30% fewer thinking tokens (like Kimi K2.7 Code) might be cheaper at a higher per-token price because it finishes tasks faster.
-
Consider the infrastructure multiplier. The AA-AgentPerf data shows that hardware choice can create a 20x difference in concurrent agent capacity. A cheaper model on expensive hardware might be worse than a more expensive model on efficient hardware.
The Verdict: Open Models Are Ready, But Not for Everything
The data from mid-2026 is clear: open-weight models have closed the gap to proprietary systems on agentic tasks to a remarkable degree. GLM-5.2’s 62.1% on SWE-bench Pro, within seven points of Claude Opus 4.8’s 69.2%, is a number that would have been dismissed as impossible six months ago. Kimi K2.7 Code’s 30% reduction in thinking tokens while improving benchmark scores is the kind of efficiency gain that changes production economics.
But the honest read is that no single model wins across all dimensions. Claude Opus 4.8 still leads on the hardest, most contamination-resistant benchmarks. GPT-5.6 Sol Ultra’s vendor-reported numbers would put it ahead of everything else if independently confirmed. The open models win on cost, flexibility, and increasingly narrow capability gaps.
The most important takeaway: the gap between the best open-weight model and the best closed-source model is now measured in single-digit benchmark points, not generations. Six months ago, that sentence would have been dismissed as wishful thinking. Today, it’s the data.
For teams building production agent systems, the practical path forward is clear: benchmark on your own tooling, with your own trajectories, and your own SLOs. The models are ready. The question is whether your evaluation methodology is.



