Let’s get one thing straight: a 550-billion-parameter model that runs on eight GPUs is impressive engineering, not magic. Nvidia’s newly released Nemotron-3-Ultra-550B-A55B-BF16 isn’t defying the laws of physics, it’s exploiting every architectural trick in the modern AI playbook to squeeze frontier-level reasoning into a deployment footprint that would have seemed impossible two years ago.
The model dropped on June 4, 2026, and the machine learning community has been dissecting it ever since. The headline numbers are tantalizing: 550B total parameters, only 55B active per forward pass, a 1-million-token context window, and a minimum GPU requirement of just 8x H100s (or 4x B200s for the NVFP4 quantized version). For anyone who’s tried to deploy a dense 70B model on a single GPU and still run into memory limits, this sounds like science fiction.
It’s not. It’s just very, very good engineering.

The Architecture: Why MoE Finally Matters for Deployment
The secret sauce here is Latent Mixture-of-Experts (LatentMoE), a hybrid architecture that interleaves Mamba-2 state-space layers, standard MoE feed-forward blocks, and selective attention layers. The result is a model that activates only 10% of its total parameters for any given token, drastically cutting compute and memory needs.
This isn’t new conceptually, Mixtral and DeepSeek have been doing this for a while. What makes Nemotron-3 Ultra different is the precision-first approach. The model was pre-trained using NVFP4 (Nvidia’s native 4-bit floating point format), meaning roughly 85% of layers operate at 4-bit precision natively. Attention and projection layers stay in BF16 or MXFP8 for stability, but the bulk of the model is already quantized from day zero.
This means you’re not downloading a BF16 checkpoint and then spending days figuring out which quantization scheme loses the least accuracy. The NVFP4 checkpoint on Hugging Face is production-ready out of the box.
The Multi-Token Prediction (MTP) heads are another clever optimization. Instead of predicting one token at a time, Nemotron predicts five tokens in a single forward pass using a shared-weight design. This enables native speculative decoding without needing a separate draft model, boosting throughput by up to 5x in long-generation scenarios.
The Benchmark Reality Check
Let’s talk about where this model actually lands. The benchmark table Nvidia published is unusually honest, they didn’t cherry-pick against weaker models.
| Benchmark | Nemotron-3 Ultra 550B-A55B | DeepSeek-V4-Pro 1.6T-A49B | Qwen-3.5 397B-17B | GLM-5.1 744B-A40B |
|---|---|---|---|---|
| SWE-Bench Verified | 71.9 | 74.0 | 69.9 | 73.8 |
| GPQA (no tools) | 87.0 | 87.8 | 87.1 | 86.1 |
| MMLU-Pro | 86.8 | 87.5 | 88.3 | 85.9 |
| IFBench (prompt loose) | 81.7 | 79.1 | 78.2 | 76.6 |
| RULER (1M tokens) | 94.7 | 94.2 | 90.1 | N/A |
| LiveCodeBench (v6) | 89.0 | 92.5 | 79.3 | 85.7 |
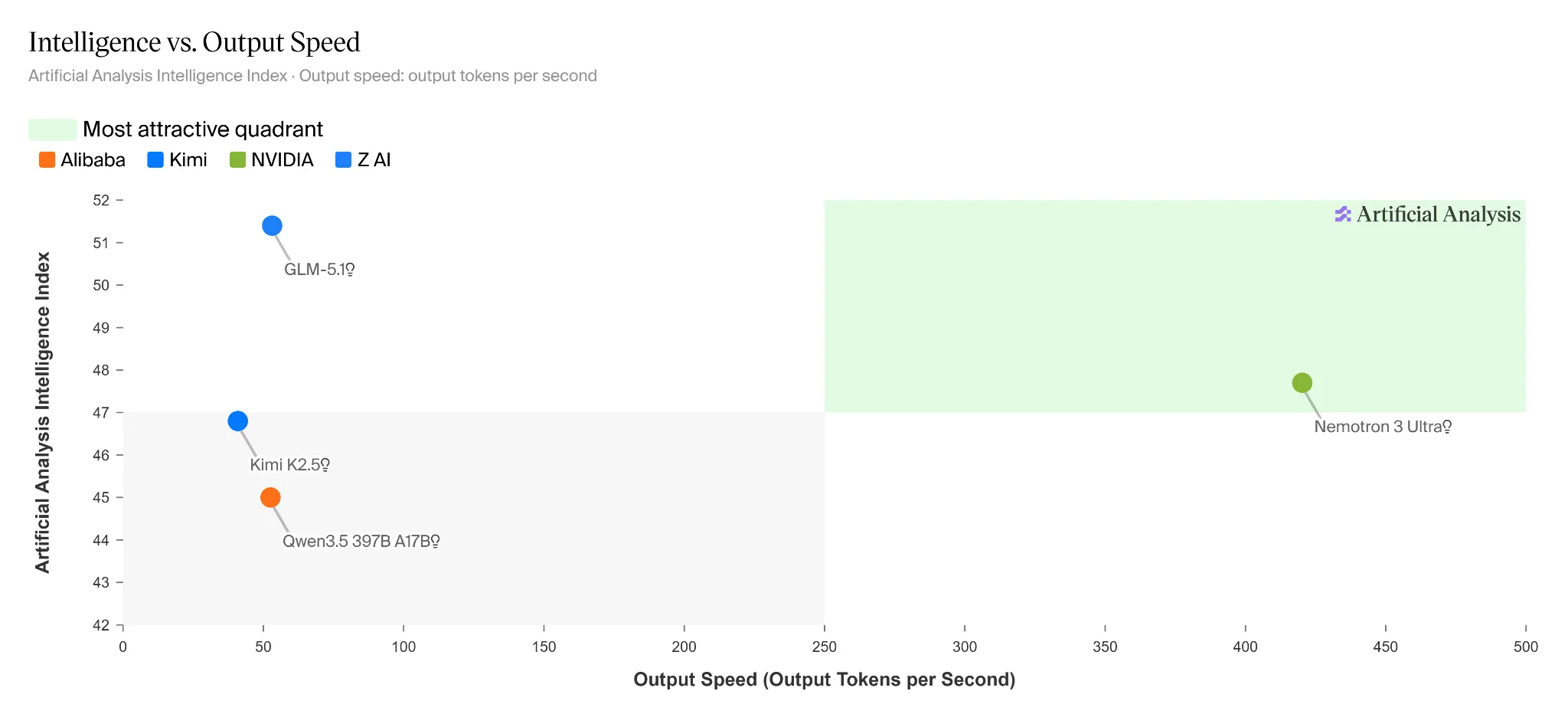
The pattern is clear: Nemotron-3 Ultra trades blows with models that have 2-3x more total parameters. It loses slightly on pure coding and reasoning benchmarks (DeepSeek-V4-Pro and Kimi-K2.6 still lead), but it dominates on speed and cost.
According to Nvidia’s benchmark data, Nemotron-3 Ultra achieves 5x higher inference throughput compared to GLM-5.1-754B-A40B and Kimi-K2.6-1T-A32B on the 8k input / 64k output setting. The Artificial Analysis Intelligence Index puts it at a score of 48, above all other US open-weight models, though trailing Kimi K2.6’s 54.
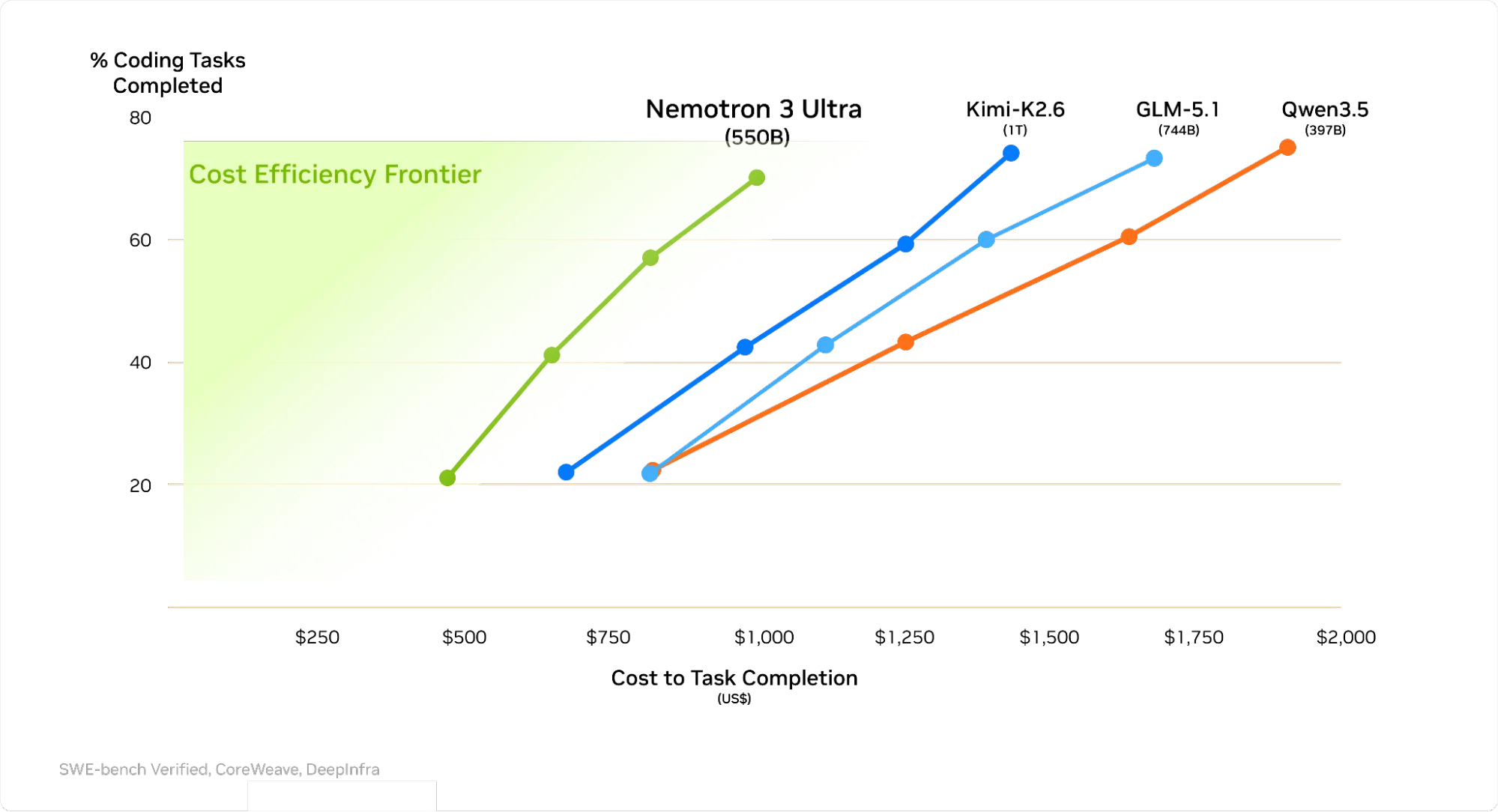
The cost savings are equally dramatic. Nvidia claims 30% lower cost to task completion on SWE-Bench Verified compared to comparable frontier models.
This is the model’s true competitive advantage: not raw intelligence, but intelligence per dollar and per watt.
What “Works on 8 GPUs” Actually Means
Let’s be precise about that claim because the technical community has been kicking this around on Reddit with varying degrees of accuracy.
The BF16 checkpoint requires:
– 8x GB200/B200/GB300/B300
– 16x H100 (80GB)
– 8x H200 (141GB)
The NVFP4 checkpoint (also officially released) drops this to:
– 4x GB200/B200/GB300/B300
– 8x H100
Yes, you can run the NVFP4 version on 8 H100s. But “run” here means functional inference, not necessarily blazing throughput. One Reddit commenter sarcastically noted that “0.8 t/s is enough for everyone” when discussing quantized deployments on consumer hardware. The reality is that on 8x H100s with chunked prefill and expert parallelism enabled, you can expect usable throughput for batch inference and agent workflows.
The vLLM deployment command from Nvidia reveals the infrastructure needed:
docker run -d --name nemotron-ultra-vllm \
--gpus all \
--ipc=host \
--network=host \
--shm-size=16g \
--ulimit memlock=-1 \
vllm/vllm-openai:v0.22.0 \
/model \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--dtype bfloat16 \
--max-model-len 262144 \
--gpu-memory-utilization 0.90 \
--max-num-seqs 16 \
--enable-chunked-prefill \
--speculative-config '{"method": "nemotron_h_mtp", "num_speculative_tokens": 5}'
Notice the --gpu-memory-utilization 0.90. You’re using 90% of the GPU memory on 8x H100s just to fit the weights with some KV cache headroom. This is not a model you run while also doing other work on those GPUs.
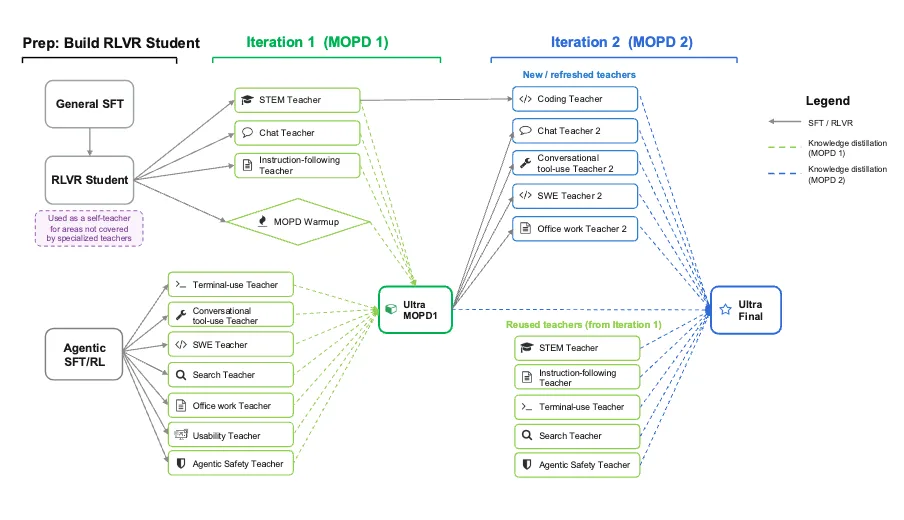
The Multi-Teacher On-Policy Distillation (MOPD) Secret
The most technically interesting part of Nemotron-3 Ultra’s training pipeline is Multi-Domain On-Policy Distillation (MOPD). This isn’t standard knowledge distillation where a static teacher generates labels for a student offline.
MOPD involves 10+ specialized teacher models, each trained on a specific domain (coding, math, legal, science, instruction following). During training, the student model generates rollouts across all these domains, and each teacher scores the student’s output in its area of expertise. The training runs asynchronously, with student rollout generation, teacher scoring, and student optimization fully pipelined.
The key innovation is that MOPD is iterative: after producing an MOPD-trained checkpoint, new rounds of teacher training are initialized from the updated student model. This co-evolution means both students and teachers get stronger over successive rounds.
This explains how Nemotron-3 Ultra achieves competitive accuracy despite having only 55B active parameters. It’s not just MoE sparsity, it’s the quality of the training signal from domain-expert teachers that elevates the student’s performance.
Where It Fits in the Ecosystem
Nvidia is now releasing the Nemotron-3-Ultra Base checkpoint (pre-instruction-tuned weights) for teams that want to do custom fine-tuning. The full toolchain includes NeMo-RL for distributed reinforcement learning, NeMo-Gym for interactive environment simulation, and the NVFP4 training schedules.
| Model | Total Params | Active Params | Target Deployment |
|---|---|---|---|
| Nemotron-3 Nano | 30B | 3B | Single GPU, edge |
| Nemotron-3 Super | 120B | 12B | Multi-GPU, mid-tier |
| Nemotron-3 Ultra | 550B | 55B | Datacenter, 8-16 GPUs |
If you’ve been following our coverage of Nvidia’s Nemotron-3-Super 120B model architecture, you know the Super already demonstrated strong reasoning for its size. The Ultra takes that same architectural philosophy and scales it 4.5x, adding the MOPD training pipeline on top.
For teams evaluating whether to jump from the Nemotron-3-Nano 30B hybrid reasoning model to Ultra, the decision comes down to workload complexity. If your agents are doing multi-step reasoning with tool calls across long contexts, Ultra’s 1M token window and 55B active parameters will matter. For straightforward Q&A and summarization, Nano or Super will serve you fine at a fraction of the infrastructure cost.
The Honest Assessment
The good: Nemotron-3 Ultra is the fastest US open-weights frontier model by a wide margin. The 5x throughput advantage over comparably sized models is real and measurable. The 1M context window with 95% RULER accuracy is genuinely impressive for long-document analysis. The fact that you can run it on 8 H100s (NVFP4) means a single DGX node can serve frontier-level reasoning.
The complicated: The intelligence gap with Kimi K2.6 (48 vs 54 on Artificial Analysis Index) is meaningful, not a rounding error. DeepSeek-V4-Pro still leads on coding and math. If raw benchmark scores are your primary selection criterion, Nemotron-3 Ultra isn’t the top. It’s the top US open-weights model, which is a different and arguably narrower crown.
The dismissive (from Reddit): “So, it loses to DS4 Flash in almost everything… a much smaller int4 native model. Wtf”, a comment that sparked a reply chain noting that “DS4 models are good on benchmarks but pretty mid in practice. Feel very undertrained.”
That last point is crucial. Nvidia models have historically underperformed on benchmarks relative to their real-world capability. The reverse is true for some competitors. Benchmarks are useful signals, not absolute verdicts.
License and Practical Path
The model ships under the OpenMDW-1.1 license, the Linux Foundation’s permissive license for open AI model distributions. Key terms: commercial use permitted, modification and distribution allowed, no attribution required in outputs. It’s slightly more restrictive than Apache 2.0 on redistribution conditions, but for most use cases (API access, internal deployment, fine-tuning for products), there’s no legal friction.
For deployment, your practical path looks like:
- Experimentation: build.nvidia.com free tier or OpenRouter
- Production API: NIM microservice ($4,500/GPU/year via NVIDIA AI Enterprise)
- Self-hosted: 8x H100s or 4x B200s, using vLLM/SGLang/TRT-LLM
Given that Nvidia also just released the Nemotron-3-nano 30B outperforms larger models, there’s now a coherent path from edge to datacenter within a single model family.
The Verdict for Builders
Nemotron-3 Ultra is the first open-weights model where the deployment efficiency is the feature, not the raw intelligence. If your bottleneck is infrastructure cost, GPU availability, or inference latency, this model is the best option in its class. If your bottleneck is pure reasoning capability on the hardest problems, Kimi K2.6 or DeepSeek-V4-Pro still lead.
The model’s performance on the Nemotron 3 hybrid architecture benchmark performance tests we’ve seen suggests that for agentic workflows, where error recovery, multi-step reasoning, and tool use matter more than benchmark trivia, the Ultra holds its own against any model on the market.
The really interesting development will be the community fine-tuning ecosystem. The NVFP4 weight format means teams can fine-tune on domain-specific data without compromising the efficiency gains. If we see domain-specialized Ultra variants appearing on Hugging Face within the next month (and we will), that’s when the model’s true value proposition becomes clear: frontier capability at mid-tier infrastructure cost.
For now, the takeaway is simple: Nvidia built a 550B model that fits on eight GPUs, and it works. That’s not a flex, it’s a roadmap for where the entire industry is heading.