It’s a fair question on the surface. A 27B parameter model quantized to 4-bit should theoretically land around 13.5GB, not 22GB. But the NVFP4 format doesn’t work the way most people assume, and the results are far more interesting than a simple size comparison suggests.
The model card tells a surprising story: across nine benchmarks including MMLU Pro, GPQA Diamond, HLE, and AIME 2025, the NVFP4 quantized version actually matches or beats the FP8 baseline on several metrics. MMLU Pro? 86.3 vs 86.1. HLE? 21.8 vs 21.7. IFBench? 65.5 vs 65.1. The NVFP4 variant wins on four of nine benchmarks, ties on one, and loses by margins smaller than statistical noise on the rest.
This isn’t supposed to happen. Halving the bit width should cost accuracy. The fact that it doesn’t, at least not in any meaningful way, is the story worth understanding.
The 22GB Illusion: Why NVFP4 Isn’t “Real” 4-Bit
The first thing everyone notices is the size. A 27B parameter model at 4-bit should be around 13.5GB. The NVFP4 checkpoint lands at 22GB. That’s closer to 6.5 effective bits per parameter, which feels like a bait-and-switch.
The reality is more nuanced, and more interesting. NVFP4 doesn’t quantize every layer to 4-bit. As the model card explains, different layers are assigned different precision formats based on their sensitivity to quantization. The attention mechanism, for instance, typically stays in FP8 because it’s far more sensitive to precision loss than feed-forward layers.
This mixed-precision approach is the secret sauce. The embeddings and LM head stay in FP16. Attention layers get FP8. The feed-forward networks, where most of the parameters live, get the NVFP4 treatment. The result is a model that’s 2.5x smaller than FP16 but retains near-lossless quality because the precision is allocated where it matters most.
The Absmax Trap: Why Naive FP4 Quantization Destroys Models
To understand why NVFP4 works, you first need to understand why naive FP4 quantization fails. The problem is brutally simple: FP4 has only 16 representable states. When you try to cram a distribution of weights into those 16 slots, the outliers eat everything.
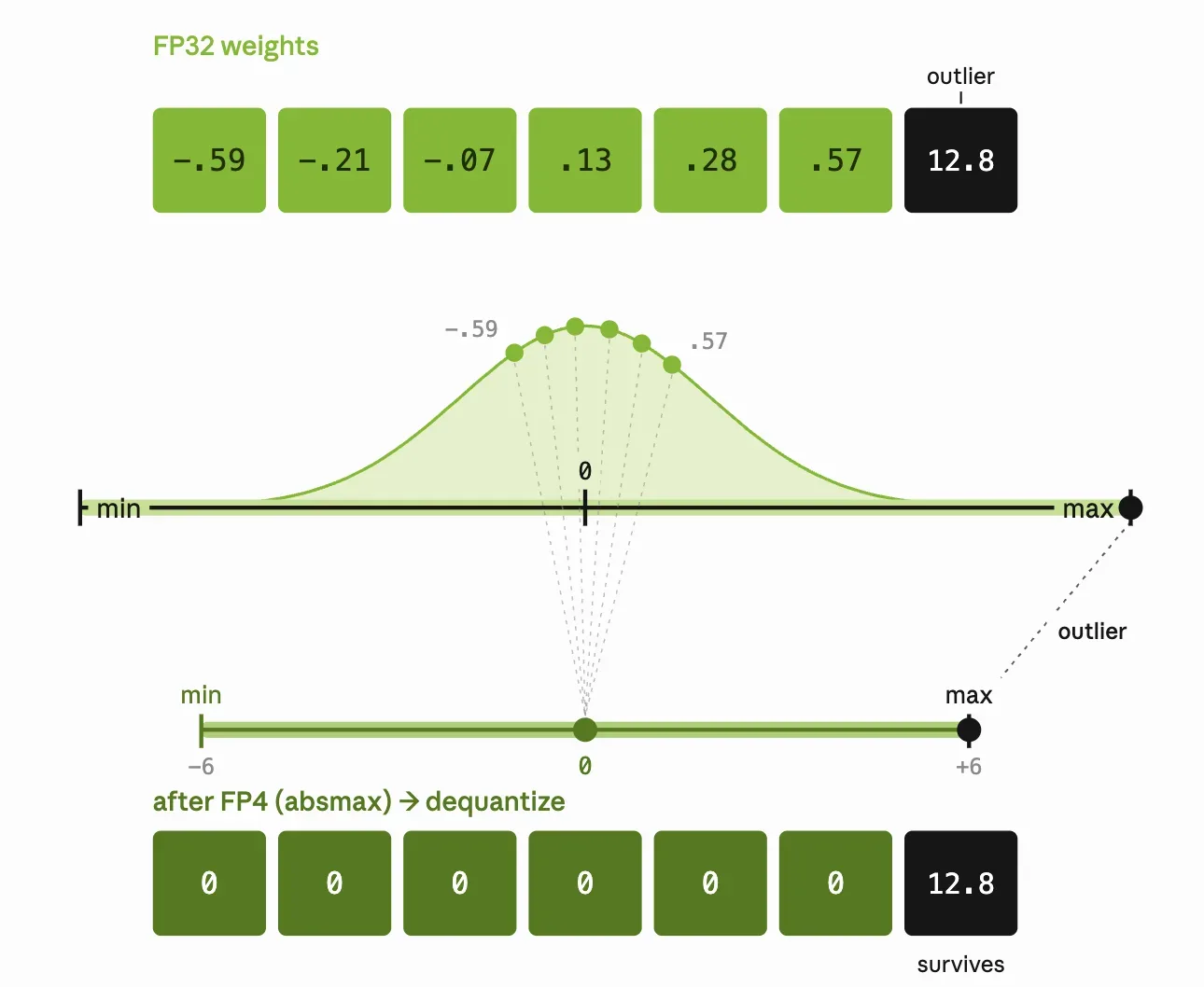
The diagram above illustrates the “absmax trap.” Under naive FP4 quantization, a single outlier weight of 12.8 forces the entire quantization grid to scale up, collapsing six smaller weights to zero. You lose almost all the signal because one aggressive value dominates the range.
NVIDIA’s solution is elegant: instead of using the absolute maximum, they apply a mean-squared-error (MSE) scaling that clips the outlier and preserves the smaller weights.
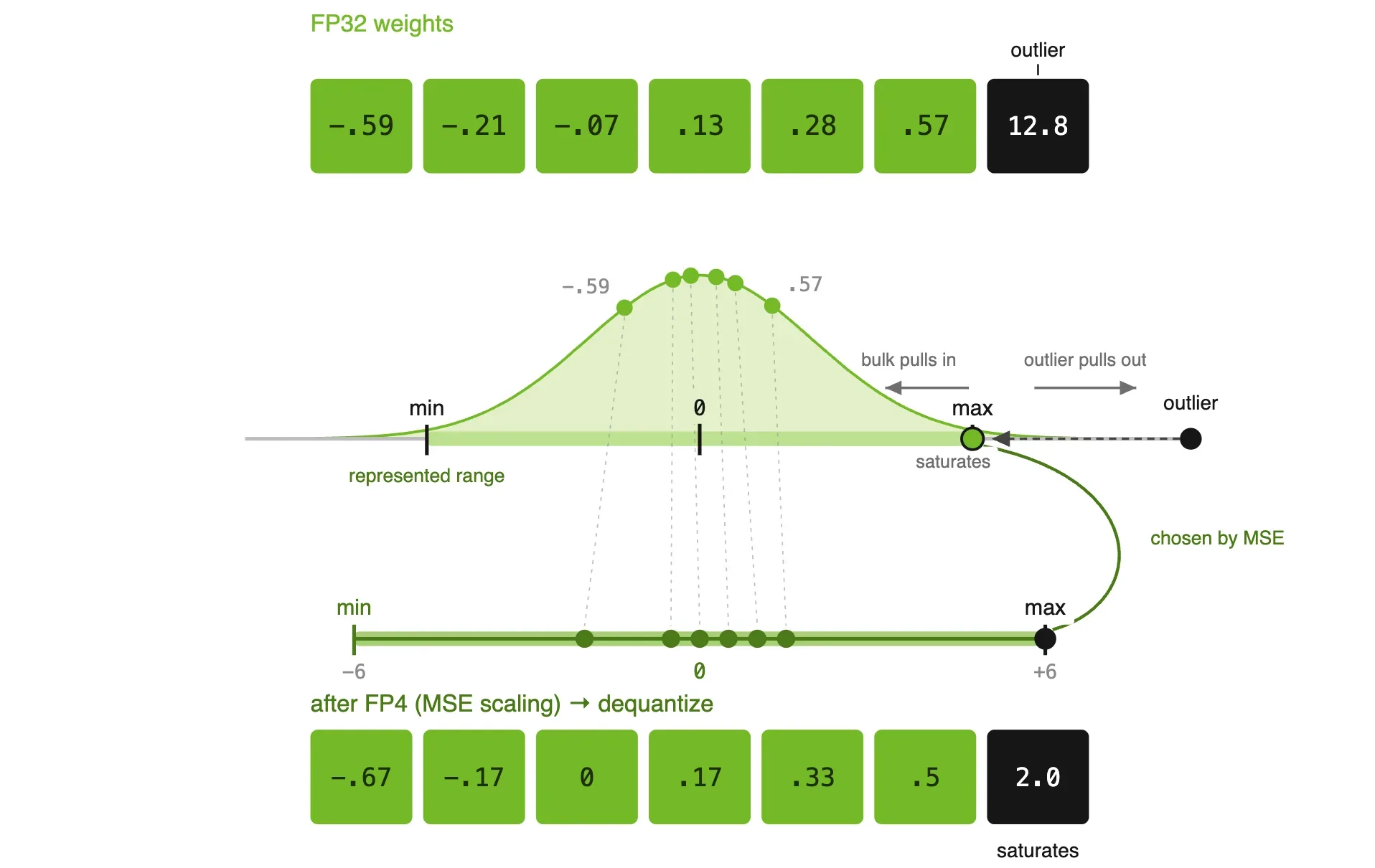
The MSE approach clips the outlier from 12.8 down to 2.0, but preserves the six smaller weights that would have been zeroed out entirely. The total error is lower because the majority of weights are preserved with reasonable fidelity, even if the extreme outlier takes a hit.
The Perplexity Cliff: Why FP4 Has a 4-to-6 Gap
FP4 isn’t just imprecise, it’s unevenly imprecise. The representable values in FP4 have a gap between 4 and 6 where no values can be represented at all. This creates a perplexity cliff that naive quantization schemes crash into.
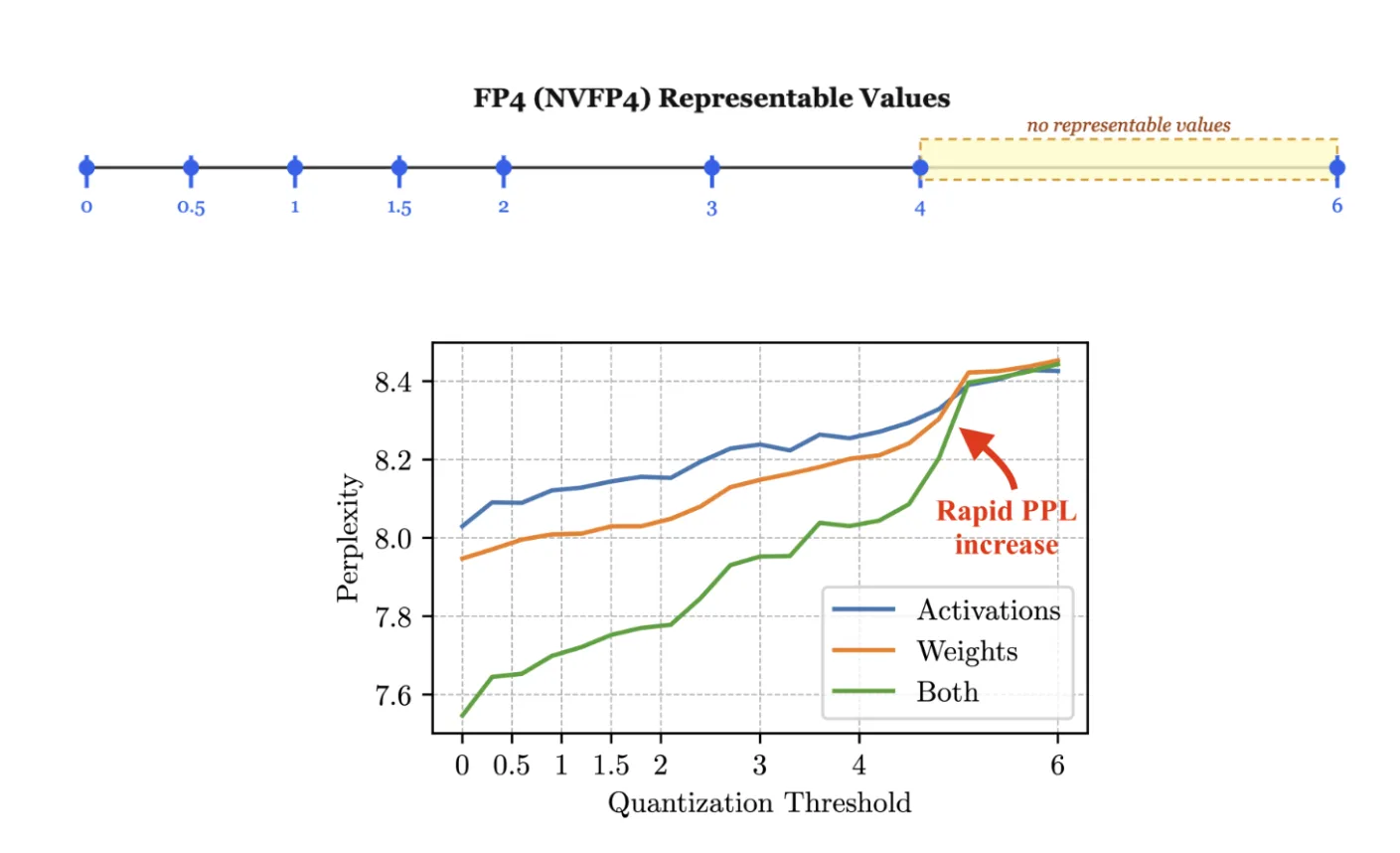
The perplexity curve spikes dramatically as the quantization threshold approaches maximal values. NVIDIA’s solution involves per-block scaling factors that effectively shift the quantization grid to match the local weight distribution. Each block of weights gets its own FP8 scale factor, and the optimal scaling is determined by minimizing mean squared error rather than preserving the absolute maximum.
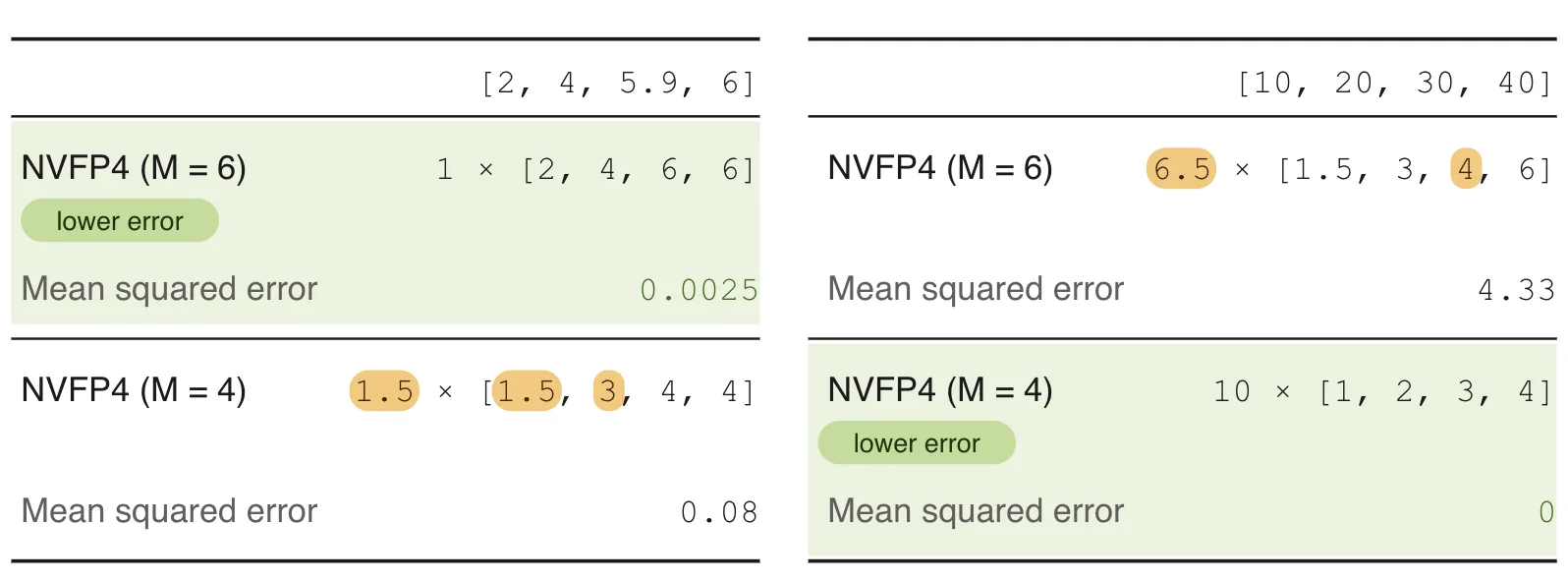
This per-block optimization is why NVFP4 can match FP8 quality despite using half the bits for the majority of weights. Each block of weights gets its own scaling factor, chosen to minimize the reconstruction error for that specific distribution. Some blocks prefer M=6 scaling, others M=4. The algorithm picks the right one for each.
The Blackwell Tax: Why NVFP4 Only Makes Sense on 5xxx Series GPUs
Here’s the catch that nobody in the Reddit threads is sugar-coating: NVFP4 is a Blackwell-native format. If you’re running on a 4090 or 3090, the GPU has to upcast NVFP4 to FP16 before doing any math, which eliminates the speed advantage entirely.
The format is designed for NVIDIA’s 5xxx series (Blackwell) GPUs, which have native hardware support for FP4 arithmetic. On those cards, the model runs faster and uses less memory. On anything older, you get the memory savings but none of the throughput benefits.
This creates a frustrating divide in the community. Users with RTX 5090s are reporting excellent results, one developer noted running the NVFP4 model with 163K context on a 5090 mobile at just 23.5GB, with MTP and TurboQuant 4 enabled. Meanwhile, users on 4090s or dual 5060 Ti setups are struggling with quality degradation and context limits.
The Benchmark Data Doesn’t Lie
The evaluation table from the model card tells a compelling story. Here’s the full breakdown:
| Precision | MMLU Pro | GPQA Diamond | HLE | τ²-Bench Telecom | MMMU Pro | SciCode | AIME 2025 | AA-LCR | IFBench |
|---|---|---|---|---|---|---|---|---|---|
| FP8 | 86.1 | 86.0 | 21.7 | 95.2 | 74.6 | 44.8 | 93.1 | 68.8 | 65.1 |
| NVFP4 | 86.3 | 85.5 | 21.8 | 95.4 | 74.3 | 44.5 | 92.7 | 68.3 | 65.5 |
The NVFP4 variant wins on MMLU Pro, HLE, τ²-Bench Telecom, and IFBench. It ties on the margin of error on everything else. The only benchmark where FP8 holds a meaningful lead is AIME 2025 (93.1 vs 92.7), and even that’s within a single question’s worth of difference.
This is remarkable. The quantization process reduced the model from 16-bit to an effective ~6.5-bit mixed precision, and the accuracy impact is essentially zero across nine diverse benchmarks spanning reasoning, coding, agentic tool-use, multimodal understanding, and long-context recall.
What This Means for Local Deployment
The practical implications are significant. A 27B model that fits in 22GB opens up serious local inference on consumer hardware. The RTX 5090 with 32GB VRAM can run this model with substantial context windows. One developer reported running it with 163K context on a 5090 mobile at 23.5GB, including MTP and TurboQuant 4.
For agentic coding workflows, this is a game-changer. The model supports vLLM’s prefix caching, which dramatically speeds up repeated inference patterns common in agent loops. As one commenter noted, “vLLM’s batching will see parallel agents absolutely fly.”
The model also supports the full 262K context length, though practical deployments will need to balance context size against VRAM constraints. The model card recommends using vllm serve nvidia/Qwen3.6-27B-NVFP4 --port 8000 --quantization modelopt --max-model-len 262144 --reasoning-parser qwen3 for deployment.
The Quality-Speed Tradeoff That Actually Works
The most impressive aspect of this release isn’t the raw numbers, it’s the real-world experience. One developer who runs their own evaluation system across a thousand questions reported switching to NVIDIA’s NVFP4 quant as their main driver, calling it “closest to BF16 of the quants, smallest, and fastest by a sizable margin.”
This aligns with the broader trend of distilled Qwen3 models outperforming larger frontier LLMs. The combination of efficient architecture and smart quantization is making local inference viable for tasks that previously required cloud API calls.
The model’s hybrid attention architecture, combining Gated DeltaNet and Gated Attention, is particularly well-suited to quantization. The different attention mechanisms have different sensitivity profiles, and the mixed-precision approach can allocate bits accordingly.
The Blackwell Dependency Problem
There’s an elephant in the room that the community is already debating: NVFP4’s reliance on Blackwell hardware. The format is designed for NVIDIA’s 5xxx series GPUs, which have native FP4 tensor cores. On Hopper (H100) or older architectures, the GPU has to simulate FP4 by upcasting to FP16, which eliminates the speed advantage.
This creates a two-tier ecosystem. Users with RTX 5090s or Blackwell datacenter GPUs get the full benefit: smaller memory footprint and faster inference. Everyone else gets the memory savings but runs at FP16 speeds. The format is effectively a Blackwell lock-in mechanism disguised as an open-weight release.
The NVIDIA CUTLASS bugs affecting Blackwell workstation performance add another layer of complexity. Early adopters are discovering that the theoretical speedups don’t always materialize in practice, particularly on workstation-class hardware rather than datacenter GPUs.
The Real-World Experience Gap
The Reddit discussion reveals a split between users who are getting excellent results and those struggling with quality. The difference often comes down to inference engine configuration and context length.
One user running on dual RTX 5060s reported getting the model to work with 50K context in vLLM, but couldn’t push to 128K without quality degradation. Another user on a single RTX 6000 Pro found that the FP16 version of Qwen3.6-27B would simply stop generating, suggesting that the NVFP4 quant is actually more stable for deployment on memory-constrained hardware.
The model’s support for Multi-Token Prediction (MTP) is a significant advantage for throughput. The NVFP4 checkpoint preserves the MTP layers, which can boost inference speed by predicting multiple tokens simultaneously. This is particularly valuable for coding and agentic workflows where latency matters.
For developers considering the switch from GGUF to NVFP4, the performance difference is stark. One user running Q6_K on llama.cpp with an RTX 6000 was getting 2000 tokens/s prefill and 90 tokens/s generation. Switching to vLLM with NVFP4 on comparable hardware would likely double or triple those numbers, especially with the Blackwell-native format.
The Verdict: A Genuine Step Forward, With Caveats
NVIDIA’s Qwen3.6-27B-NVFP4 is not a revolution. It’s an evolution, but a meaningful one. The quantization technique is sophisticated enough to preserve accuracy while cutting memory requirements by 2.5x. The mixed-precision approach is smarter than naive 4-bit quantization, and the per-block MSE scaling addresses the fundamental limitations of FP4’s representational capacity.
The model is a strong contender for local agentic coding, chatbot deployment, and RAG systems. It’s particularly compelling for developers who want to run Qwen3.5 locally for agentic coding without sacrificing quality.
But the Blackwell dependency is real. If you’re on a 4090 or older hardware, the speed benefits are theoretical. And the 22GB size, while impressive, isn’t the dramatic reduction that naive 4-bit math would suggest.
The bottom line: NVIDIA’s Qwen3.6-27B-NVFP4 is the best quantized 27B model available for Blackwell hardware, and it’s competitive with FP8 on quality metrics. For developers with RTX 5090s or Blackwell datacenter GPUs, it’s the clear choice. For everyone else, the GGUF ecosystem still offers more flexibility and broader hardware support.
The uncensored version of Qwen3.6-27B combined with 4-bit quantization adds another dimension to this story, but that’s a topic for another post. For now, the takeaway is clear: NVFP4 is a legitimate advancement in quantization technology, not just marketing hype. The benchmarks prove it, and the community’s early adoption confirms it.



