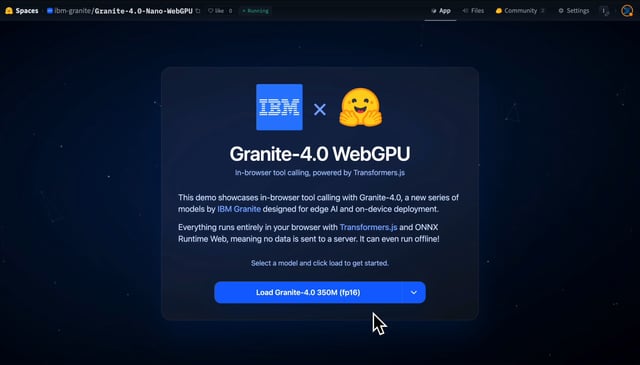
The cloud-first AI revolution has been, frankly, convenient but utterly humiliating for your data. Every query, every typo, every half-baked thought shipped off to someone else’s computer for judgment. IBM just threw a wrench in that entire parade with Granite 4.0 Nano, 300 million and 1 billion parameter large language models that run entirely in your browser using WebGPU. No API keys, no mysterious telemetry, just your hardware doing the work.
This isn’t just another incremental model release. It’s a fundamental shift in how we interact with AI, from begging remote servers for responses to commanding local silicon to think for itself.
The End of AI Purgatory
The Granite 4.0 Nano family comprises four instruct models and their base counterparts. The headliners are:
- Granite 4.0 H 1B, A ~1.5B parameter dense LLM featuring a hybrid-SSM based architecture
- Granite 4.0 H 350M, A ~350M parameter dense LLM with the same hybrid architecture
- Granite 4.0 1B and Granite 4.0 350M, Traditional transformer versions designed for workloads where hybrid architectures may not yet have optimized support
What’s revolutionary here isn’t just the size, it’s the performance. When competing sub-billion parameter models from Alibaba, LiquidAI, and Google are struggling to maintain quality at these scales, Granite Nano delivers surprisingly capable instruction following and tool calling. IBM trained these models with the same improved methodologies, pipelines, and over 15 trillion tokens of training data developed for the original Granite 4.0 models.
Recent experiments in extreme quantization, like reducing models to mere megabytes, show what’s possible when we push the boundaries of model compression. IBM’s approach takes this concept and makes it production-ready.
Performance That Belies the Size
The benchmarks tell a compelling story. Across general Knowledge, Math, Code, and Safety domains, Granite 4.0 Nano models demonstrate a significant increase in capabilities achievable with minimal parameter footprint. But more impressively, they shine where it matters for practical applications.
Granite Nano models substantially outperform similarly sized models on tasks critical for agentic workflows, particularly instruction following (IFEval) and tool calling (Berkeley’s Function Calling Leaderboard v3). This isn’t about being the smartest model, it’s about being the most useful model at this scale.
This performance profile makes them perfect for on-device applications where every megabyte counts but capability remains non-negotiable.
WebGPU: The Silent Enabler
IBM’s technical achievement rests on WebGPU, the modern successor to WebGL that provides unified and fast access to GPUs directly from browsers. As Chrome’s WebGPU documentation explains, WebGPU exposes modern hardware capabilities and allows rendering and computation operations on a GPU, similar to Direct3D 12, Metal, and Vulkan.
The Granite WebGPU demo uses Transformers.js to run the models 100% locally in your browser. This means your laptop’s GPU, previously relegated to displaying cat videos, now becomes a legitimate AI inference engine. No cloud dependencies, no Round-trip latency, just pure computational power harnessed where it belongs: on your device.
What makes this particularly compelling is that IBM open-sourced the demo source code, allowing developers to examine and extend the implementation. For enterprise environments where data sovereignty and privacy aren’t just buzzwords but regulatory requirements, this represents a seismic shift.
The Enterprise-Grade Edge
The Granite models carry IBM’s ISO 42001 certification for responsible model development, addressing a critical enterprise concern that often gets overlooked in the race for smaller, faster models. This certification gives organizations confidence that these models are built and governed to global standards, crucial for regulated industries considering on-premise AI deployment.
Developer communities are already taking notice. Many developers report being genuinely impressed by the Nano models running on WebGPU, noting that the hybrid “mamba+attn” architecture might legitimately be the way forward for efficient on-device inference.
This move aligns with growing interest in LLM-powered browser automation and local tool execution. The privacy advantages are undeniable, sensitive documents never leave your device, proprietary code stays proprietary, and personal data remains exactly that: personal.
The Architecture That Makes It Possible
IBM’s hybrid architecture combines state space models (SSM) with attention mechanisms, providing efficiency gains without sacrificing capability. This hybrid approach allows the models to process information more efficiently than traditional transformer-only architectures, particularly beneficial for the memory-constrained environments where these Nano models will operate.
The traditional transformer variants (Granite 4.0 1B and 350M) exist specifically for workloads where hybrid architectures may not yet have optimized support in popular runtimes like llama.cpp. This pragmatic approach ensures developers can integrate these models immediately while the ecosystem catches up with the more efficient hybrid versions.
What This Actually Means for Developers
The implications ripple far beyond technical novelty:
Instant Privacy-Centric AI: Applications handling medical records, legal documents, or financial data can now incorporate sophisticated AI without the Faustian bargain of cloud processing.
Reduced Operational Costs: No more playing roulette with cloud API pricing. Your inference costs become predictable electricity consumption rather than usage-based surprises.
Offline Capability: Airplane Wi-Fi? Rural connectivity? No problem. These models work entirely disconnected from the internet.
Browser-Native Integration: The distinction between web applications and local applications blurs significantly. Complex AI workflows can now run directly in browser tabs alongside other web content.
Tool Calling Everywhere: The ability to call browser APIs and interact with websites programmatically opens up automation possibilities previously requiring complex backend infrastructure.
The Quiet Revolution No One Predicted
While the AI world obsesses over trillion-parameter behemoths requiring data center-scale resources, IBM quietly delivered something more profound: AI that respects your privacy by default, runs on hardware you already own, and does useful work at human-compatible latencies.
At less than half the size of a typical mobile game, Granite 4.0 Nano models prove that intelligence doesn’t require gigawatt-scale data centers. Sometimes, it just needs the right architecture and the willingness to let users own their computation.
The era of begging cloud providers for AI access is ending. Welcome to the age of local sovereignty, where your data stays yours, your models run on your terms, and your browser becomes the most private AI assistant money can’t buy. Because the best AI isn’t the one that knows everything, it’s the one that knows when to stay quiet about what it processes for you.