Simulating 19 horses a trillion times on a 1,000-vCPU cloud cluster costs less than you think. We unpack the compute economics and ask: what are we really paying for?
Moving beyond load testing dummies to find the real-world cracks in your scaling and failover plans.
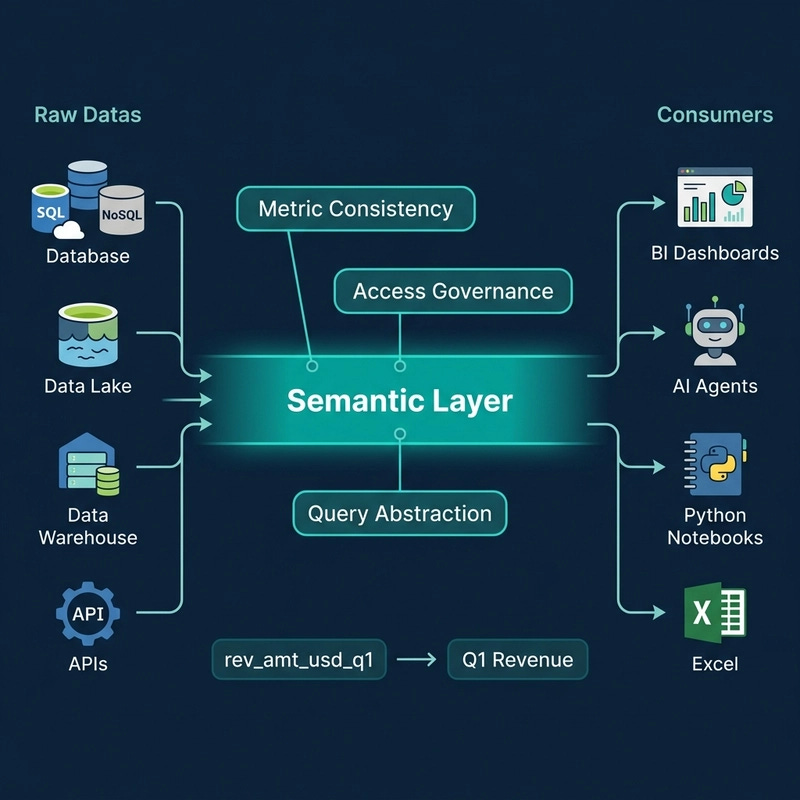
The hidden war between fast-moving BI teams and slow-moving architecture in legacy enterprises, why your manufacturing company has 50+ calendar tables and a fact table with CAD doubling.
Google’s Multi-Token Prediction drafters for Gemma 4 promise 2-3x inference speedups with zero quality loss. We dive into the mechanics, the ‘tiny’ 78M-parameter secret, and what it means for local AI’s future.
A $27,142 AI food truck operator for $3.51 per run, and why Western AI pricing just became indefensible.
An investigation into how Chrome downloads the Gemini Nano model without consent, violating EU law and racking up a staggering carbon debt.
Apple’s quiet removal of high-memory Mac Studio configurations isn’t just a supply chain hiccup, it’s a strategic throttling of the local LLM ecosystem. Our investigation into the 256GB and 512GB cuts reveals a deeper, more troubling calculus.
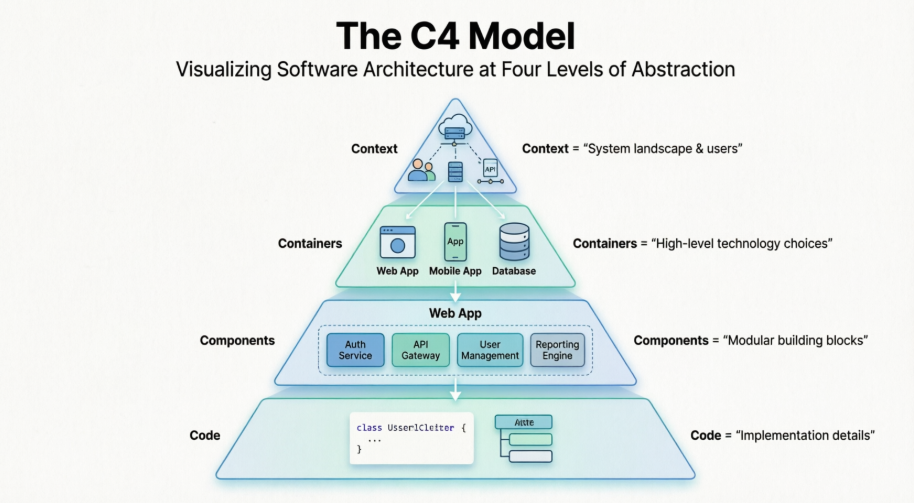
Simon Brown’s framework is a communication marvel, but for modern, dynamic systems, its static nature can leave you flying dangerously blind at runtime.
When LLMs graduate from filling in code snippets to drafting entire system designs, we’re outsourcing theory building to statistics. The resulting systems ship fast and collapse faster.
Anthropic bought Bun. Then Claude Code started collapsing. Now what happens to your infrastructure?
The new Medusa-style MTP support in llama.cpp beta isn’t just catching up, it threatens to rewrite the economics of local model serving.
The secret isn’t in your vault, it’s in your browser’s memory. A vulnerability in Microsoft Edge exposes the harsh reality of transient state security.