

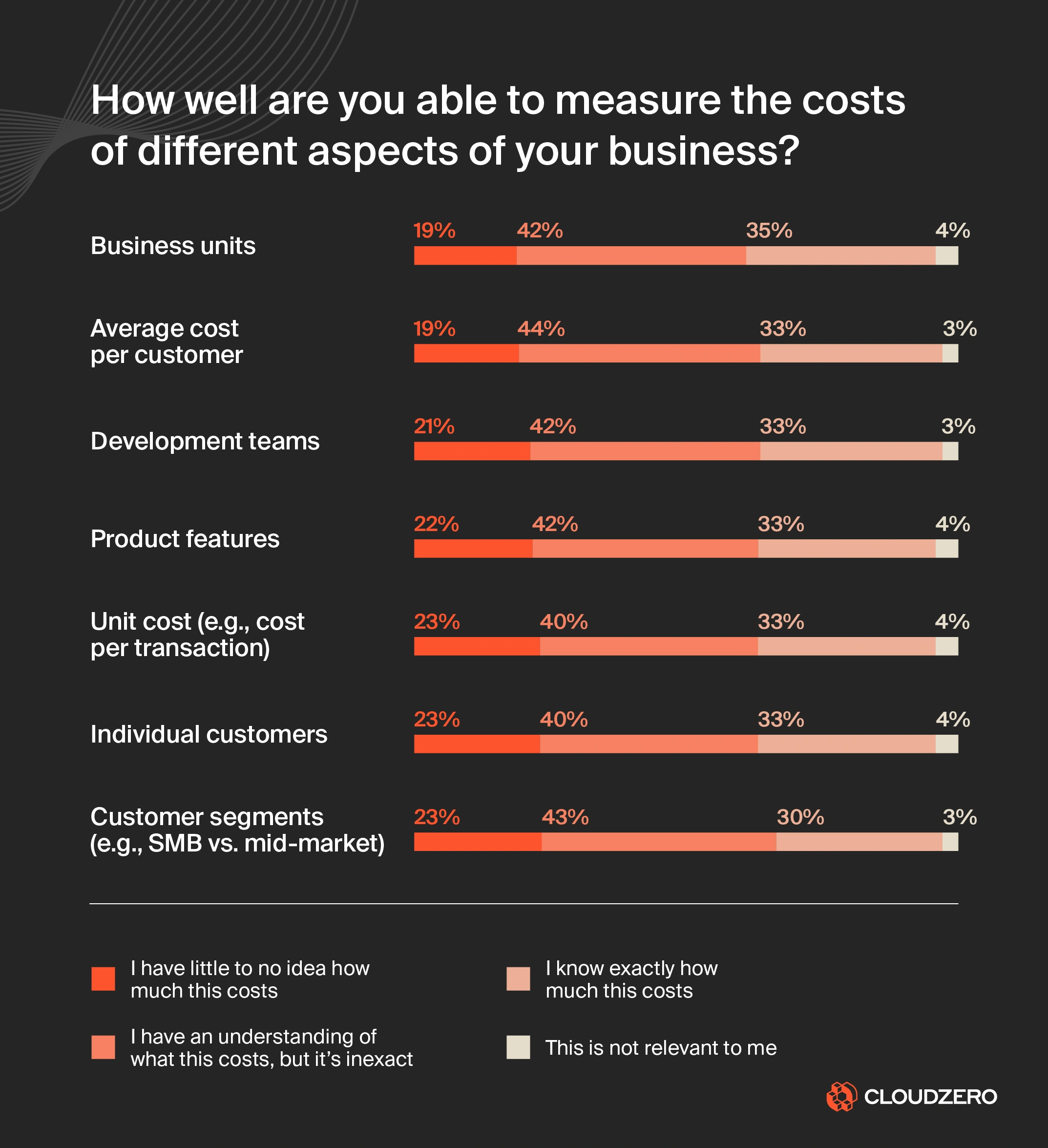
The headline is predictably spicy: Further Ado, with a field-leading Beyer speed figure of 106, was the model’s top pick, netting a 27.9% win probability against a 14.3% market-implied chance, a 1.95x value multiplier. Five longshots were tagged as value bets. The morning-line favorite, Renegade, drawing the historically cursed post position 1, was the model’s strongest fade.
But the real story isn’t about horseflesh. It’s about compute-flesh. This exercise is a microcosm of a massive, quiet shift: the democratization of statistical artillery via cloud economics. We can now ask “what if?” a trillion times for what was, historically, a desktop-class problem. What does that cost? More importantly, what does that enable? And is the signal worth the silicon?
Let’s dig into the bill.
The Mechanics of a Trillion-Race Blitz
First, the technical blueprint. The pipeline, built with the open-source Python library Burla, comprised four parallelized stages.
- Data Ingestion: A 114-task parallel scrape pulled 16 years of historical Derby results, Beyer speed figures, pedigree data, trainer/jockey stats, and the 2026 morning line.
- Model Training: 164 separate machine learning configurations (Gradient Boosting, Random Forest, Logistic Regression) were trained in parallel. The best ensemble achieved a log-loss of 0.12 on a holdout set.
- Hyperparameter Search: A Dirichlet distribution was used to sample 5,000 different weight combinations across ten features (stamina test, Beyer, dosage, post win-rate, etc.). Each combination was backtested against the 16 historical Derbies. The entire search, 5,000 parallel workers, returned results in 7 seconds. The optimal weights leaned heavily on raw horse capability: stamina test (19.2%), year-level Beyer (16.1%), and dosage score (15.9%). Trainer and jockey edges mattered less than the racing press narrative suggests.
- The Trillion Sims: The core act. Each horse was assigned a strength score from the model. Gaussian noise was added to simulate race-day variance. The horses were ranked. This was repeated 1,000,000,000,000 times, split across 10,000 worker tasks (each simulating 100 million races).
from burla import remote_parallel_map
import numpy as np
def simulate_race_batch(scores, n_sims, seed):
rng = np.random.default_rng(seed)
n = len(scores)
counts = np.zeros((n, 4), dtype=np.int64)
for _ in range(n_sims):
noise = rng.normal(0, 1.8, n) # calibrated upset rate
noisy = np.array(scores) + noise
exp_s = np.exp(noisy - noisy.max())
probs = exp_s / exp_s.sum()
order = rng.choice(n, size=4, replace=False, p=probs)
for rank, idx in enumerate(order):
counts[idx][rank] += 1
return {"counts": counts.tolist()}
# 10,000 worker tasks × 100,000,000 sims = 1,000,000,000,000 total
args = [(log_probs, 100_000_000, seed) for seed in range(10_000)]
results = remote_parallel_map(simulate_race_batch, args, grow=True)
total = np.sum([r["counts"] for r in results], axis=0)The result? A probability distribution for each horse’s finishing position, derived not from elegant calculus but from brute-force enumeration. Further Ado won 27.9% of the simulated races. The entire operation, from a cold start, took less than an hour.
The Price Tag: Cloud Economics at Hyperscale
So, what’s the damage for a trillion simulated derbies?
We don’t have the exact cloud invoice, but we can reverse-engineer a plausible range. A 1,000-vCPU cluster for ~49 minutes of sustained compute. If we assume modern, general-purpose instances (e.g., AWS’s c6i or GCP’s n2-standard), the on-demand rate is roughly $0.04-$0.06 per vCPU-hour.
Back-of-napkin math: 1,000 vCPUs * (49.9/60) hours * $0.05/vCPU-hour = ~ $41.58.
For about forty bucks, you bought a statistical certainty. The model’s backtest score of 126/160 (using a 10-5-2-1-0 scoring metric) passed a 2,000-permutation null test with a p-value of effectively zero. The signal was real.
This is the new reality of power-constrained compute infrastructure investments. Where once such an analysis would have been the domain of hedge funds or national labs, it’s now within reach of a determined individual with a cloud credit card. The barrier isn’t hardware or electricity, it’s orchestration software and the willingness to spin up ephemeral armies of silicon.
The Critical Divide: Precision vs. Practical Value
This is where the data science community on Reddit raised a crucial, skeptical eyebrow. The core critique wasn’t about the code or the cluster, it was about statistical overkill.
One experienced practitioner pointed out that unless you’re estimating an “extremely rare event of cosmic magnitude”, a trillion simulations is unnecessary precision. The model’s output probabilities (e.g., 27.9% vs. 14.3%) would likely have been nearly identical with 10,000 or 10 million runs. The marginal value of the last 990 billion simulations approaches zero.
This gets to the heart of modern ML economics: Is more compute always better, or just more expensive? The trillion simulations provided a comforting, rock-solid confidence interval. But did they change the betting recommendation? Probably not. The top picks were likely identifiable with far less firepower.
This is the classic cloud waste pattern, magnified. CloudZero’s 2024 State of Cloud Cost Report found that 22% of organizations have no visibility into their unit costs, and waste averages 28-32% of cloud spend. The trillion-sim project isn’t waste per se, it had a defined end, but it exemplifies the “because we can” mentality that FinOps teams battle daily. It’s the difference between total cloud spend and understanding your cost per inference or cost per feature.
From Horses to Hyperparameters: A New Paradigm for Experimentation
The real economic lesson isn’t in the single run’s cost. It’s in the iterative velocity that cheap, massive parallelism unlocks.
The project’s creator noted that running the 5,000-weight hyperparameter search locally, sequentially, would have taken ~20 minutes. On Burla’s parallel cluster, it took 7 seconds. Training 164 model configs locally: ~8 minutes. On the cluster: ~110 seconds.
This flips the experimentation workflow on its head.
| Task | Sequential Local | Burla Parallel |
|---|---|---|
| 164 ML Configs | ~8 min | ~110 sec |
| 5,000 Weight Combos | ~20 min | 7 seconds |
| 1M Monte Carlo Sims | ~6 min | ~90 sec |
| Total | ~34 min | ~5 min |
When you can test 5,000 hypotheses in the time it takes to get coffee, you stop optimizing for fewer experiments. You start asking different, more expansive questions. You can afford to include marginal features, run massive sensitivity analyses, and brute-force your way out of local optima. This is the same paradigm shift enabling scientific reasoning with trillion-parameter architectures, sheer scale allowing exploration of previously intractable search spaces.
The Unit Cost of a “Maybe”
The project’s most honest admission is buried in its methodology audit: “Takeout eats real edge.” Churchill Downs keeps ~17% of the win pool. To be profitable, a model needs to beat the market by more than that margin. The model identified five value bets with multipliers from 1.74x to 1.95x. The creator notes that only the top pick, Further Ado, was “stake-able at full bankroll”, the four longshots were “small saver tickets.”

This is the ultimate FinOps lesson for quantitative modeling: You must translate statistical edge into economic utility. A 1.95x multiplier sounds great, but after the track’s cut and the inherent variance of a 19-horse race, the expected value is thin. The compute cost (~$40) is just the entry fee. The real cost is the opportunity cost of capital tied up in bets and the risk of ruin.
Modern cloud cost management isn’t about stopping spend, it’s about understanding the unit economics of your decisions. What is the cost per simulation? The cost per hyperparameter tested? The cost per basis point of expected return? Tools that provide this level of granularity are moving from luxury to necessity.
Conclusion: The Democratization of Statistical Supremacy
Running a trillion Kentucky Derby simulations for less than the cost of a nice dinner isn’t a parlor trick. It’s a signpost. The raw economics of cloud computing have collapsed the time and cost of massive numerical experiments, reshaping fields from finance to pharmacology.
The controversy isn’t about whether it’s possible, it clearly is. It’s about whether this power leads to better decisions or just more precise, yet still flawed, ones. As one Reddit commenter with over a decade of experience in data science noted, these sophisticated models often foster overconfidence. The house edge, whether it’s a racetrack’s takeout or the unpredictable chaos of real-world systems, is a brutal and efficient destroyer of elegant math.
The trillion-sim project is a brilliant showcase of modern cloud capability. It’s also a cautionary tale about the diminishing returns of compute. The future belongs to those who can wield this scale intelligently, not just to ask questions a trillion times, but to ask the right questions first, and to know when the answer is good enough.
For engineering leaders, the imperative is clear: managing cloud spend is no longer just about turning off idle instances. It’s about instituting a culture of compute accountability. Every massive parallel job should be able to justify its existence not just in CPU-hours, but in the tangible business value or unique insight it generates. Otherwise, you’re just paying for a very expensive, very precise guess.

