The AI world just got a lot more interesting. Not because another proprietary API got marginally better, but because Z.ai dropped GLM-5.2, a 753B-parameter, MIT-licensed monster, onto Hugging Face for anyone to download.
This isn’t another “open-ish” release with a research-only license. This is the real deal: commercial use, fine-tuning, distillation, and self-hosting are all on the table from day one. And the community is already salivating over what comes next.
The Numbers That Matter First
Let’s get the specs out of the way, because they matter for the story that follows.
| Metric | GLM-5.2 | GPT-5.5 | Claude Opus 4.8 |
|---|---|---|---|
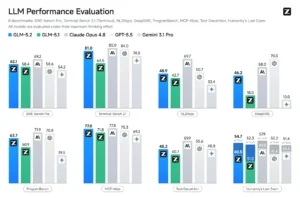
| FrontierSWE | 74.4% | 72.6% | 75.1% |
| Terminal-Bench 2.1 | 81.0 | , | , |
| AIME 2026 | 99.2 | , | , |
| API Input/Output | $1.40 / $4.40 | ~$8 / ~$24 | ~$10 / ~$30 |
GLM-5.2 scores 51 on the Artificial Analysis Intelligence Index, ranking it #1 among open-weight models and third overall behind only Fable 5 and Opus 4.8. It beats GPT-5.5 on FrontierSWE, a long-horizon engineering benchmark, at one-sixth the API cost.
That price delta isn’t just a rounding error. It’s a strategic weapon.
The Architecture Nobody’s Talking About Enough
GLM-5.2 uses a Mixture-of-Experts (MoE) architecture with 753B total parameters but only 40B active per token. This means every inference call only activates a fraction of the model’s brain, keeping compute costs manageable despite the massive scale.
The real engineering contribution is IndexShare, Z.ai’s improvement on DeepSeek Sparse Attention. Here’s what makes it special: by reusing a single lightweight indexer across every four sparse attention layers, they reduce per-token FLOPs at 1M context by 2.9×. That’s the difference between “advertised context” and “actually usable context.”
The model also ships improved Multi-Token Prediction (MTP) layers that boost speculative decoding acceptance by up to 20%. For inference providers, this means serving the full model at 112 tokens per second becomes practical rather than theoretical.
Wait, But Can Anyone Actually Run This Thing?
Here’s the tension that makes this release so spicy. GLM-5.2 is too big to run on consumer hardware, and the community is simultaneously thrilled and frustrated about it.
The hardware requirements break down like this:
| Quantization | Memory Required | Minimum Setup |
|---|---|---|
| FP8 Weights | 744, 890 GB | 8× H200 or 8× H100 server node |
| 4-bit (Q4_K_M) | 476, 500 GB | Mac Studio cluster or 6× 80GB enterprise GPUs |
| 2-bit (Q2_K_XL) | 241, 280 GB | Single 256GB Mac Studio or RTX 4090 + 256GB system RAM |
| 1-bit Dynamic | 176, 180 GB | 192GB Mac Studio or 24GB GPU + 192GB system RAM |
One Reddit user running a 13-year-old HP Z820 workstation with 512GB RAM reported 0.5, 1 token per second on DeepSeek’s 671B model. They predicted GLM-5.2 would be similar. “This is equivalent to human typing speed”, they noted. “The experience will be like texting your AI.”
For context, a 512GB Mac Studio M3 Ultra can hit 12 tokens per second on the 2-bit quant. That’s usable, but the hardware costs five figures.
The Distillation Promise Changes Everything
The headline feature of GLM-5.2 isn’t something Z.ai built. It’s what the community can now build with it.
Distillation is the real story here. Once you have a frontier-level model running on an enterprise cluster, you can use it to generate high-quality synthetic data, reasoning chains, coding solutions, agentic trajectories, and then fine-tune that knowledge into dramatically smaller architectures.
The last time this happened at scale was with DeepSeek R1, which spawned dozens of distilled 7B, 14B, and 32B variants that punched way above their weight class. GLM-5.2 promises the same dynamic, but starting from a higher base.
The open-weight rebellion is already forcing the conversation. The question isn’t whether distillation will happen, it’s whether the distilled versions will narrow the gap enough to make the full 753B model unnecessary for most use cases.
Early indications from similar distills suggest a well-executed 70B model trained on GLM-5.2 outputs could retain 85, 90% of the parent’s reasoning capability while running on a single enterprise GPU. For a model that rivals GPT-5.5, that’s transformative.
What the Community Is Already Discovering
Early adopters who have gotten GLM-5.2 running locally are reporting surprising results. One user on a 512GB M3 Ultra cluster noted 18 tokens per second with the mxfp4 quant and no stability issues. Another reported that the model’s conversational quality “isn’t like a springtime romp in an alpine meadow, but it’s also not like talking to a brick wall or being told to go to sleep by your weird uncle.”
The sentiment that keeps surfacing: GLM-5.2 is the first open-weight model that practitioners seriously consider substituting for Opus or GPT-class workflows. One developer called it “the first open model I could comfortably replace Opus/GPT with.”
But there are gaps. The model lacks vision capabilities, which matters for anyone whose daily workflow involves analyzing screenshots or design references. Multiple users noted this as the primary reason they can’t fully switch. Some are solving it with auxiliary models, using Gemini 3.1 Flash-Lite as an “eyes” sub-agent while GLM-5.2 handles the reasoning, but that’s a workaround, not a solution.
The Geopolitical Context Is Impossible to Ignore
GLM-5.2’s release timeline reads like a strategic opera:
- June 12, 2026: US government restrictions force Anthropic to suspend Fable 5 access
- June 13, 2026: Z.ai announces GLM-5.2 will go fully open-source
- June 17, 2026: Weight live on Hugging Face
The timing wasn’t accidental. Z.ai’s official tagline, “Frontier Intelligence Belongs to Everyone”, lands differently when geopolitical forces have just demonstrated that API access can be revoked overnight.
This geopolitical power play has reshaped how enterprises think about model procurement. When you control the weights, no government can cut off your access. That’s not a philosophy argument anymore, it’s a risk management calculation.
Z.ai has been on the US BIS Entity List since January 2025. That means US federal customers and defense primes will avoid the model regardless of license. But for everyone else, and especially for the broader developer ecosystem outside the US, the MIT license represents genuine autonomy.
What Distillation Actually Looks Like in Practice
The path from “frontier model on an enterprise cluster” to “runs on your laptop” follows a relatively well-established playbook:
- Generate synthetic reasoning data using GLM-5.2 itself, including chain-of-thought trajectories, coding solutions, and agentic workflows
- Fine-tune a smaller architecture (8B, 70B, or 120B dense models) on this data
- Evaluate and iterate until the distilled model meets quality thresholds
The key insight from recent distillation work is that the quality of the teacher’s outputs matters more than the teacher’s size. A smaller model trained on high-quality reasoning chains from a frontier teacher consistently outperforms larger models trained on scraped internet data.
Plausible targets for GLM-5.2 distillation include a 70B dense model that rivals current 200B+ sparse models, or an 8B model optimized for specific domains like code generation or mathematical reasoning. The quantization work done on GLM-4.7 suggests that aggressive compression techniques can preserve surprising amounts of capability.
The Hard Truth About Hardware
The enthusiastic optimism about distillation collides with economic reality when you price the compute.
Running GLM-5.2 at FP8 on 8× H200 GPUs costs roughly $200/hour in cloud rental. That’s the entry ticket for generating the synthetic data you need for a meaningful distillation run. A serious effort would need thousands of hours of inference time spread across multiple model configurations.
The cost efficiency arguments are compelling at scale, but they assume existing infrastructure. For a startup or individual researcher, the upfront compute cost to produce a high-quality distilled model is nontrivial.
That said, this is exactly the kind of problem that open-source communities excel at solving. Expect shared datasets, pre-distilled checkpoints, and collaborative training runs to emerge within weeks.
The Dark Horse: IndexShare and Long-Context Feasibility
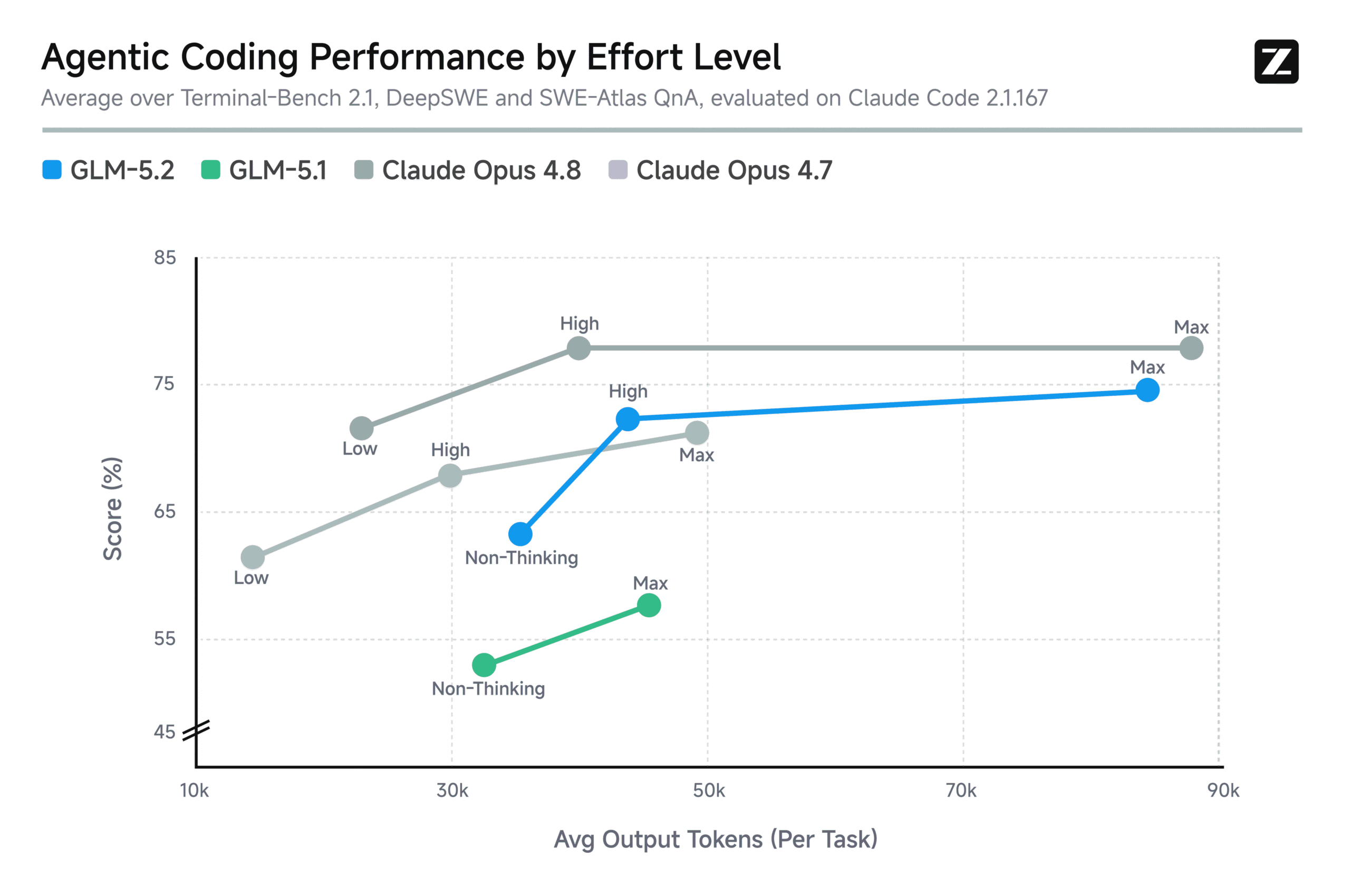
One of the most underappreciated aspects of GLM-5.2 is how it handles the 1M token context window. Most models that claim long context degrade sharply on retrieval and consistency as trajectories lengthen. GLM-5.2’s IndexShare mechanism, combined with training on “messy, long-horizon Agent trajectories”, appears to produce genuinely usable long-context behavior.
This matters because agentic coding is the benchmark that’s replacing short-form QA. A model that can hold a coherent conversation over 100K tokens of codebase context, maintaining understanding of file structure, dependencies, and build configurations, is more valuable than a model that scores higher on multiple-choice tests.
The independent benchmark data supports this. Terminal-Bench 2.1, which evaluates agentic terminal use, shows GLM-5.2 scoring 81.0, the first open-weight model to break 80% on this evaluation. For context, GLM-5.1 scored 63.5. That’s a 27.6% improvement in a single generation.
Distillation Can’t Fix Everything
Let’s be honest about the limitations. GLM-5.2 wins on agentic coding and long-context tasks, but it’s not a universal champion. On Text Arena it’s only #25 overall, roughly flat versus GLM-5.1. The strongest independent wins are in coding, agents, and terminal tasks, not general text or creative writing.
Distillation inherits these gaps. A distilled 70B model fine-tuned on GLM-5.2’s coding outputs will excel at coding tasks but won’t magically develop better creative writing or nuanced reasoning abilities than the teacher had.
The lesson is to pick your domain carefully. If you’re building a coding agent, GLM-5.2 distillation is your best bet. If you need multimodal or text-heavy capabilities, wait for a later release or look elsewhere.
What Happens Next
The next 3-6 months will determine whether GLM-5.2 becomes a founding moment for local AI or a footnote in the open-weight story. The variables that matter:
- Speed of community distillation: How quickly do usable 8B and 70B variants emerge? The first weekend of GLM-5.2’s availability already showed MLX running on Mac Studio clusters. Expect the first distillates within 2-4 weeks.
- Quality of synthetic data: Will the community generate diverse, high-quality reasoning chains, or lazy copy-paste datasets? Early efforts set the ceiling for everything that follows.
- Hardware availability: As used Mac Studios and enterprise servers flow into the secondary market, the hardware barrier drops. The stealth launch history of the GLM series suggests the supply chain is already adapting.
- Benchmark evolution: If the community shifts toward long-horizon agentic coding as the primary evaluation, GLM-5.2’s strengths become more pronounced. If short-form QA remains dominant, the advantage is smaller.
The strategic shift toward agentic competition is already underway. Chinese AI labs are betting that ecosystem capture through open weights will outlast the technical moat of closed APIs. GLM-5.2 is the strongest test of that thesis yet.
GLM-5.2 is the most capable open-weight model ever released, and its MIT license unlocks a distillation pipeline that will redefine what’s possible on local hardware. The hardware requirements for the full model are punishing, but the distilled derivatives will run on gear you can actually afford.
The story isn’t about the 753B model sitting on enterprise clusters. It’s about the 70B model that will run on your workstation next quarter, trained on reasoning data from a model that beats GPT-5.5.
That’s the open-weight revolution in action. It doesn’t announce itself with a press release. It shows up in a GitHub repo, in a quantized checkpoint, in a model that was once “too big to run” and is now your daily driver.
GLM-5.2 won’t be the last open model to crash the frontier. But it’s the one that proved the frontier was never truly closed.