The Open-Weight Rebellion: GLM-5.2 Just Made Closed-Source AI Look Like a Bad Gamble
The narrative has been consistent for two years: real frontier AI lives behind API walls. If you want Claude Opus or GPT-5.5, you pay per token and accept whatever usage policies get updated next Tuesday. Open-weight models were supposed to be a training ground, good enough for tinkering, never quite ready for production.
Then GLM-5.2 landed on Hugging Face with an MIT license, a 753B parameter footprint, and a benchmark score that rewrites the playbook.
The Benchmark That Matters Now
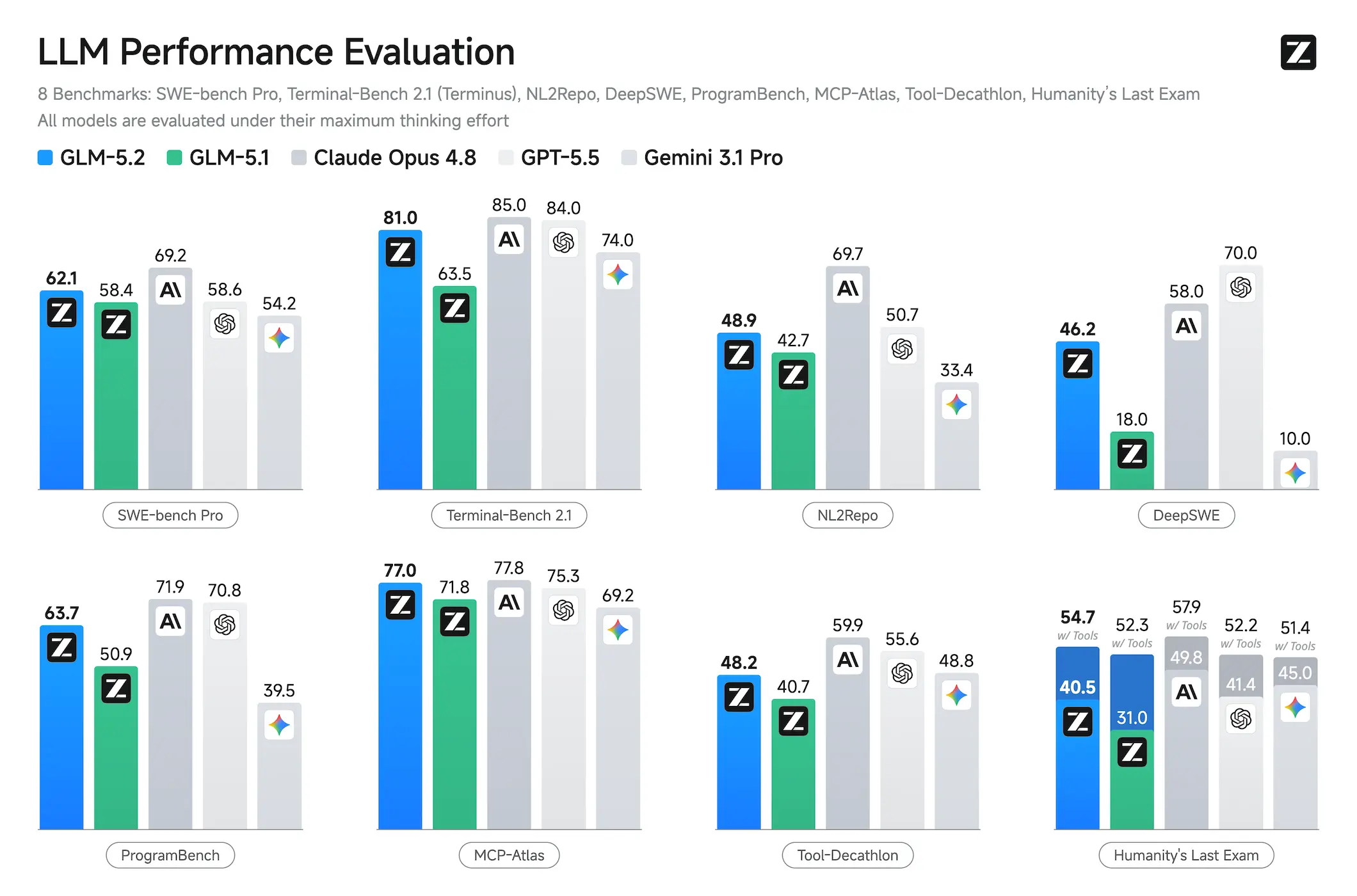
Terminal-Bench 2.1 isn’t another multiple-choice trivia contest. It tests models on real terminal-based coding tasks, the messy, multi-step work that separates demo-ware from engineering tools. For months, the 80% threshold felt like a closed-source exclusive club. Claude Opus 4.8 sat at 85.0. GPT-5.5 at 84.0. Gemini 3.1 Pro at 74.0.
GLM-5.2 hit 81.0 on Terminal-Bench 2.1. The first open-weight model to break that ceiling.
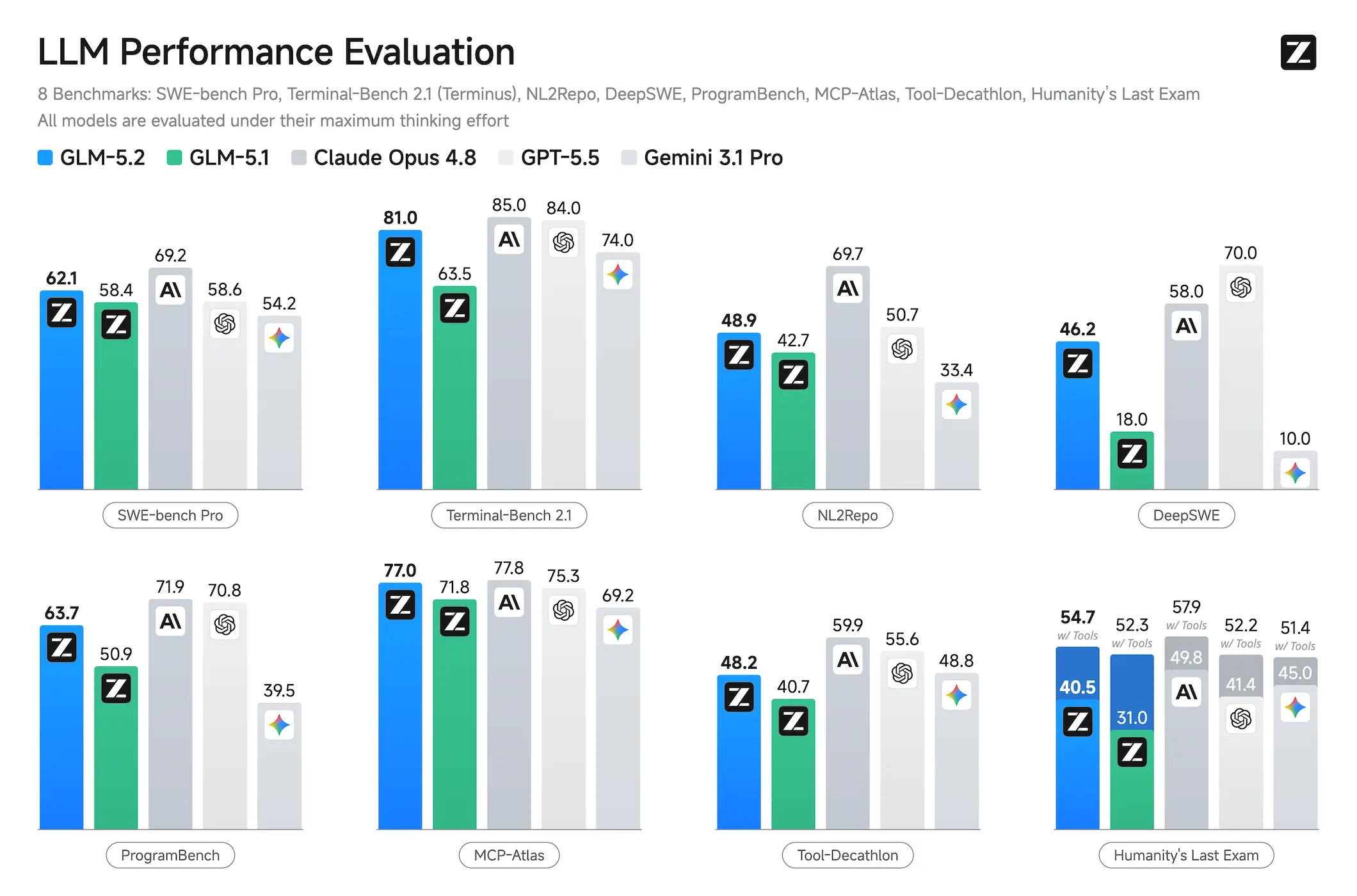
The gap to Opus 4.8 is now four points, close enough that the debate shifts from “can open-weight compete” to “how fast can it catch up.” For anyone running coding agents at scale, that difference is negotiable, especially when you can self-host the model and skip the per-token meter.
Where the Numbers Get Weird
Scratch the surface and the story gets more interesting than a single leaderboard slot. The DeepSWE benchmark, which measures autonomous software engineering capability, shows GLM-5.2 scoring 46.2, placing it above Claude Opus 4.6 and Sonnet, just below Opus 4.7. That’s not a fluke, it’s a pattern across multiple evaluation frames.
The full benchmark table tells a nuanced story:
| Benchmark | GLM-5.2 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 81.0 | 85.0 | 84.0 | 74.0 |
| DeepSWE | 46.2 | 58.0 | 70.0 | 10.0 |
| FrontierSWE | 74.4 | 75.1 | 72.6 | 39.6 |
| SWE-bench Pro | 62.1 | 69.2 | 58.6 | 54.2 |
FrontierSWE is where it gets spicy. This benchmark tests whether an agent can complete open-ended technical projects over hours to tens of hours. GLM-5.2 trails Opus 4.8 by less than 1%, and edges out GPT-5.5 by nearly two points. On PostTrainBench, where agents get an H100 GPU and must improve small models, GLM-5.2 outperforms both Opus 4.7 and GPT-5.5, ranking second only to Opus 4.8.
The model is not a one-trick pony. It’s competitive across the coding task spectrum, and on long-horizon benchmarks, it’s genuinely threatening closed-source leaders.
The Architecture That Makes It Work
None of this happens by accident. GLM-5.2 builds on the GLM-5 lineage, scaling from 355B parameters (32B active) to 744B parameters (40B active) with an MoE architecture. But the real innovation is IndexShare, a technique that reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length.
This is what makes the model’s 1M-token context actually usable, not just a spec sheet boast. Previous models claimed long contexts but degraded under real engineering pressure. GLM-5.2 underwent months of specialized training for coding-agent scenarios: large-scale implementation, automated research, performance optimization, and complex debugging. The result is a model that maintains quality across long, messy trajectories, not just accepts more tokens.
The Practical Reality: What Developers Actually Experience
The community response has been instructive. Early adopters report a model that feels different from its predecessors. One developer described it as having “a new found confidence in its judgment and taste”, pushing back on dubious instructions and asking for reconfirmation rather than blindly executing.
Real-world usage patterns reveal the tradeoffs:
- On Mac Studio 512GB: Usable but slow beyond 45K context. The model’s size (753B params in BF16) demands serious hardware for local inference.
- In coding agent harnesses: Works better with ForgeCode than ZCode, showing fewer tool failures and better token efficiency.
- As a daily driver: Massive improvement over GLM-5.1, but still below GPT-5.5 for general reasoning tasks.
The nuanced take from experienced users places GLM-5.2 roughly between Opus 4.7 and Opus 4.8 under similar token consumption. That’s not “open-weight beats everything”, it’s “open-weight is now genuinely competitive”, which is a fundamentally different statement than what was true six months ago.
The Economic Disruption Nobody’s Talking About
Here’s the part that keeps closed-source executives up at night: GLM-5.2 costs roughly 1/6th of GPT-5.5 per API call from inference providers. And if you can self-host, using vLLM, SGLang, or KTransformers, your marginal cost drops to electricity and hardware depreciation.
The VentureBeat coverage highlighted this directly: GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for a fraction of the cost. When the economics shift this dramatically, the closed-source business model starts looking fragile. Why build your entire engineering workflow around an API that could change pricing, policies, or availability overnight, when you can download a competitive model and run it yourself?
This dynamic is playing out across the open-weight landscape. For more context on how this competition is unfolding, check out the analysis on DeepSeek V4 and Qwen3.5, both massive open-weight models challenging closed-source incumbents from different architectural angles.
The License That Changes Everything
GLM-5.2 ships under an MIT license. No regional restrictions. No usage caps. No “research only” fine print. You can deploy it, fine-tune it, distill it, or build a product around it without asking permission.
This is not the norm. Many “open” models ship with restrictions that effectively neuter them for commercial use. The MIT license on a 753B frontier-competitive model is a power move, one that signals Z.AI’s confidence in their pipeline. They’re betting that commoditizing the current frontier accelerates demand for whatever comes next.
The geopolitical subtext here is impossible to ignore. The prior post on how GLM-5.2 turned a US export ban into an open-source power play lays out the timing that made this release a strategic countermove. When closed models get pulled from API access overnight due to regulatory shifts, having a downloaded copy with an MIT license becomes existential for engineering teams.
The Distillation Loop Nobody Wants to Admit
There’s an uncomfortable reality here that deserves honest discussion: how did an open-weight model get this good, this fast? The answer, in part, is distillation.
The relationship between closed-source frontier models and open-weight competitors has become symbiotic in ways the closed labs didn’t anticipate. Anthropic’s Claude models, in particular, have become unwitting training data sources. For a deeper dive into this dynamic, the analysis on how Anthropic became the unwilling godfather of open-weight AI is essential context.
This isn’t cheating, it’s how the field has always advanced. But it means the closed-source advantage is inherently leaky. Every API call generates outputs that can be used to train competitors. The moat isn’t as deep as the pricing suggests.
The Hardware Reality Check
Let’s be honest about the elephant in the room: GLM-5.2 at 753B parameters in BF16 requires serious hardware. We’re talking multiple GPUs, substantial RAM, and cooling that probably isn’t going to fit under your desk. The Nvidia Nemotron 3 Super takes a different approach, a 4-bit quantized alternative designed for broader deployment, even if it lacks the raw benchmark performance.
The practical implication is clear: open-weight freedom comes with infrastructure costs. For individual developers, the API route still makes sense. For teams building agentic coding pipelines, the math shifts once you hit enough volume to justify the hardware investment.
What This Means for the Next Six Months
GLM-5.2 doesn’t end the closed-source vs. open-weight debate, but it fundamentally changes the terms. The argument is no longer “open-weight can’t compete on frontier benchmarks.” The argument is now “open-weight competes well enough that the cost difference becomes the deciding factor.”
Three developments to watch:
- Terminal-Bench 3.0 is reportedly coming, and as one Reddit commenter noted, the initial scores will be telling before labs start optimizing for the new test. The real question is whether GLM-5.2’s architecture has headroom or if this release represents a peak before the next closed-source leap.
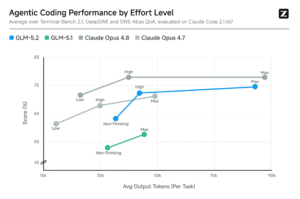
- Effort-level control introduces a new variable. GLM-5.2 supports Max and High reasoning modes, letting users trade performance for latency. This flexibility matters for production deployment where you can’t afford max compute on every request.
- The distillation pipeline accelerates. If GLM-5.2 can be used to generate training data for smaller, faster models, the entire ecosystem benefits. The gap between frontier and accessible narrows faster than any single model release suggests.
The old rules don’t apply anymore. You can download a model that beats closed-source competitors on long-horizon coding tasks, runs on open-source serving frameworks, and carries no usage restrictions. Whether that’s enough to disrupt the established order depends on how many engineering teams are willing to bet on hardware over API convenience.
Early evidence suggests the answer is: more than the closed-source labs are comfortable with.