The AI world has a habit of handing you a miracle with one hand and a six-figure API bill with the other. But every so often, the formula flips. Z.ai just dropped GLM-5.2, a 753-billion-parameter monster, onto Hugging Face for free. And it doesn’t just play well with benchmarks, it tops them.
According to Sam Paech’s rigorous EQ Bench Creative Writing v3 leaderboard, GLM-5.2 is the highest-ranked open-weights model for creative writing, sitting at #8 overall with an Elo score of 1821.0. It’s sandwiched between Claude Opus 4.6 at 1924.6 and GPT-5.2 at 1780.3. For context, the models above it are all closed-source, proprietary systems with price tags that require CFO approval. GLM-5.2? It’s MIT-licensed. You can download it. You can own it.
The Creative Writing Crown: What the Numbers Actually Mean
The EQ Bench creative writing benchmark isn’t your typical “benchmaxxed” math test where an extra 2% means nothing in the real world. It’s a Claude-judged evaluation of narrative quality, style, originality, and slop avoidance. GLM-5.2 scores an 82.20 Rubric Score with a Slop Score of just 1.8, that’s the same low-GPT-ism frequency as Claude Opus 4.8 and Kimi K2.6. It manages this while producing outputs averaging 6,104 tokens, giving it enough runway for genuine narrative complexity.
What’s even more telling is the model’s progression. GLM-5 scored 1655.1 Elo. GLM-5.1 jumped to 1640.9. GLM-5.2 now sits at 1821.0. That’s a 10% improvement in creative writing capability in a single generation. This isn’t incremental, it’s a trajectory that suggests GLM-6 might genuinely threaten Claude Opus 4.8’s throne for a fraction of the cost.
The model achieved this by scoring high on both Style and Abilities axes while keeping repetition and slop metrics in check. Many models can write long, few can write long and well without descending into GPT-ism purgatory. GLM-5.2 threads that needle.
Beyond Prose: The Benchmark Table That Matters
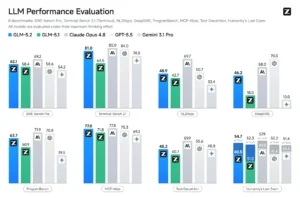
GLM-5.2 isn’t a one-trick pony. It’s not just the best open creative writing model, it’s a genuinely competitive frontier model across the board. Here’s how it stacks up against the closed-source heavyweights:
| Benchmark | GLM-5.2 | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | GLM-5.1 |
|---|---|---|---|---|---|
| SWE-bench Pro | 62.1 | 69.2 | 58.6 | 54.2 | 58.4 |
| Terminal-Bench 2.1 | 81.0 | 85 | 84 | 74 | 63.5 |
| AIME 2026 | 99.2 | 95.7 | 98.3 | 98.2 | 95.3 |
| GPQA-Diamond | 91.2 | 93.6 | 93.6 | 94.3 | 86.2 |
| FrontierSWE | 74.4 | 75.1 | 72.6 | 39.6 | 30.5 |
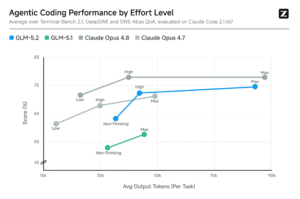
The Terminal-Bench 2.1 score is the real standout. GLM-5.2 hits 81.0, a massive jump from GLM-5.1’s 63.5. It’s now within spitting distance of GPT-5.5 (84) and Claude Opus 4.8 (85). For a model you can run on your own hardware, this is borderline absurd. It’s competitive with models that cost hundreds of thousands to run per year.
The 238GB Miracle: Running a 753B Model at Home
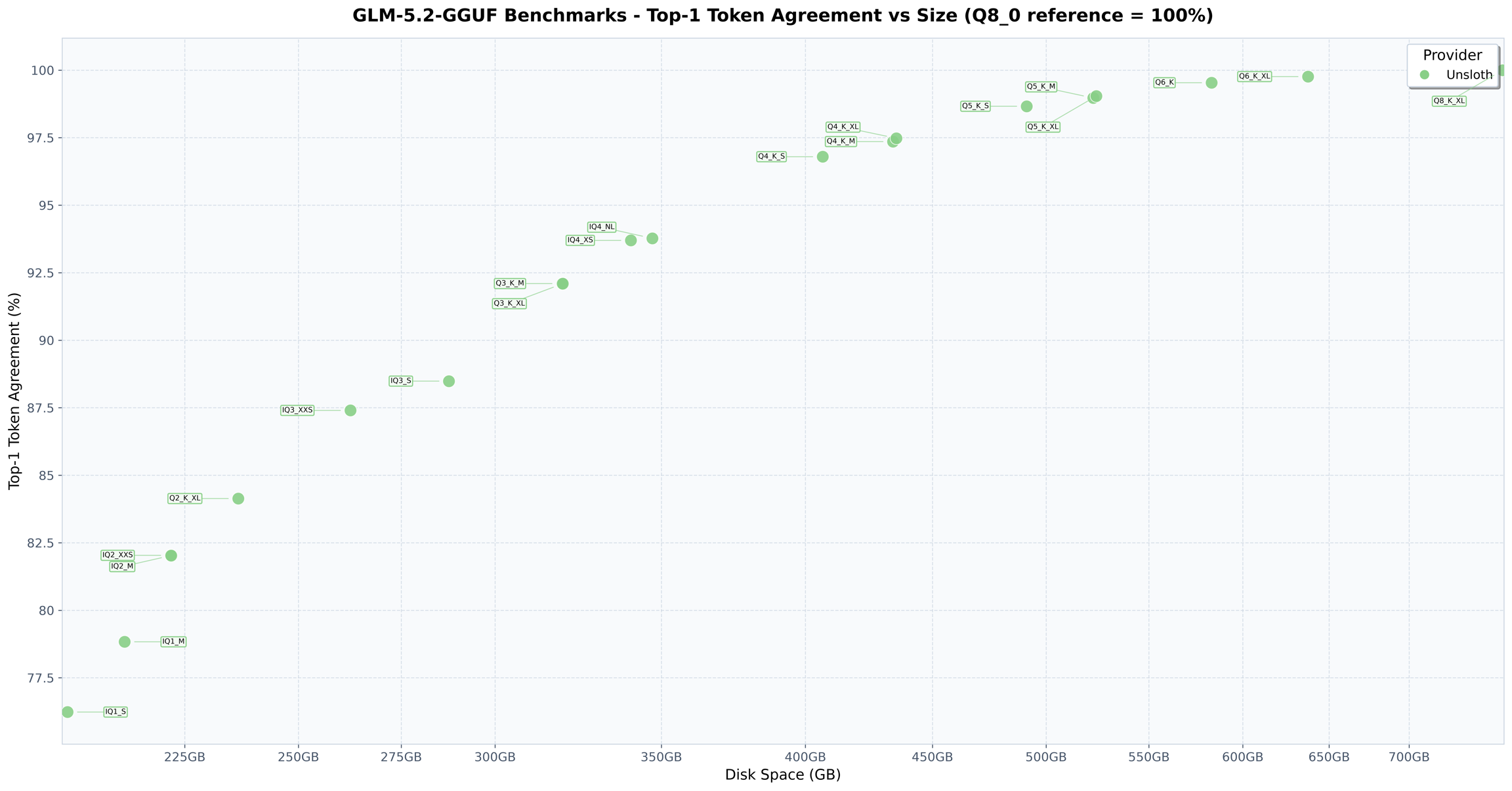
Here’s where things get interesting. The raw BF16 model is 1.51TB. That’s not a typo. It requires an enterprise-grade hardware cluster, think 8x H200 GPUs and a mortgage payment’s worth of electricity. But Unsloth’s Dynamic GGUF quantizations change the game entirely.
Their 2-bit UD-IQ2_M quantization shrinks the model to 238GB, an 84% reduction. And the accuracy retention? 82% top-1% accuracy. That means 82% of the time, the quantized model chooses the same next token as the full-precision version. On a 256GB unified-memory Mac (M4 Ultra Mac Studio or a maxed-out MacBook Pro), this runs.
Let me repeat that: a 753-billion-parameter frontier model, capable of writing fiction that rivals Claude, solving AIME 2026 problems at 99.2%, and performing agentic coding tasks, runs on a single, non-datacenter computer.
The 1-bit UD-IQ1_S quant goes even further, at 176GB. Unsloth’s Daniel Han demonstrated it generating a full, working Flappy Bird game in HTML/CSS/JS with zero syntax errors. This is not where models go to die, it’s where they go to live.

Hardware Reality Check
- 256GB Mac Studio / MacBook Pro: Run UD-IQ2_M (238GB). Expect 3-5 tok/s. This is a creative writing and code refactoring machine, not a real-time chatbot.
- Workstation + 24GB GPU + 256GB RAM: Run UD-Q2_K_XL (~280GB) or UD-IQ2_M. Use MoE offloading to fit the model across RAM and VRAM.
- Multi-GPU (2x A100/H100): Run Q4_K_M (~476GB) for near-lossless quality.
- Cloud rental: A Pod with an H200 + large RAM can run the 2-bit quant for a few dollars per hour.
As one developer on Hugging Face noted: “I am just 230 GB short on RAM to run this beast.” Another user ran UD-Q4_K_XL on a dual RTX PRO 6000 setup with 512GB of DDR5 RAM, achieving ~2.97 tok/s. It’s not fast, but it’s functional. For creative writing sessions where you’re generating long-form prose, that’s perfectly usable. You write the prompt, go make coffee, come back to a chapter.
The Free Inference Giveaway: Hugging Face’s Drug Dealer Tactic
As of this writing, Hugging Face’s Inference Providers are offering free GLM-5.2 inference for a limited window. You can hit their API with zero cost and test the model against your most creative prompts. This is exactly as dangerous as it sounds, once you taste frontier-level open writing, going back to smaller models feels like trading a Ferrari for a tricycle.
The setup is trivial. If you have a Hugging Face token, you can run:
from huggingface_hub import InferenceClient
client = InferenceClient()
completion = client.chat.completions.create(
model="zai-org/GLM-5.2",
messages=[{"role": "user", "content": "Write a short story about a robot learning to paint."}]
)
print(completion.choices[0].message.content)
The model defaults to a High reasoning effort mode. For complex creative tasks, you’ll want to pass reasoning_effort: "max" in your request. The difference is noticeable, max effort produces longer, more coherent narratives with richer character development. It’s the difference between a short story and a novella.
Creative Writing in Practice: What to Expect
I’ve been throwing prompts at GLM-5.2 for the past day, and the results are genuinely impressive. The model handles narrative voice with surprising consistency. It doesn’t forget character traits halfway through a paragraph. It maintains tone across long outputs.
The one consistent issue is pacing. GLM-5.2 has a tendency to be verbose, sometimes spending too many sentences on descriptive detail that doesn’t advance the plot. This is where the Slop Score metric becomes relevant, at 1.8, it’s low, but the model’s “natural” style is closer to Nabokov than Hemingway. If you want taut, minimalist prose, you’ll need to prompt for it explicitly.
For genre fiction, the model excels. It handles worldbuilding, dialogue, and action sequences with equal competence. I prompted it for a noir detective story and got a 4,000-word piece with a genuinely surprising twist ending. The judge (Claude) rated it 84/100 for style. That’s not “good for a robot.” That’s good for a human writer.
The Open-Weight Insurance Policy
The timing of this release is not coincidental. The same month GLM-5.2 dropped, the US government ordered Anthropic to take Claude Fable 5 offline worldwide. A model that developers had begun to integrate into their workflows vanished overnight. No warning. No transition. Just a memory hole.
As I’ve written before, GLM-5.2 is “the model you can actually own.” Once you download those 238GB of GGUF weights, no executive order can reach them. No API provider can rate-limit you. No licensing dispute can yank them from your server.
The developer community has noticed. The GLM-5.2 thread on Hacker News hit 729 points with 455 comments, with users explicitly praising Chinese labs for their openness in contrast to the sudden closure of Western frontier models. The sentiment isn’t political, it’s practical. Open weights are insurance against the fragility of closed ecosystems.
Jie Tang, founder of Z.ai, put it simply: “GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone.” That’s not just marketing. It’s a statement of strategy. While Anthropic was shutting down access, Z.ai was putting their best model on Hugging Face with an MIT license.
The Distillation Opportunity
The 753B model running at 3 tok/s is impressive, but it’s not a production workflow. The real long-term impact will come from distillation. As I explored in my previous analysis of GLM-5.2’s distillation potential, the 40B active parameters per token in this MoE architecture makes it an ideal teacher model.
Imagine a 27B dense model distilled from GLM-5.2’s creative writing capability. That model could run on a single RTX 4090 at real-time speeds while retaining 90%+ of the teacher’s narrative quality. The community is already asking for a “GLM-5.2 Flash” variant, a smaller, faster sibling in the vein of GLM-4.7-Flash.
This is the playbook that worked for DeepSeek-R1 and Qwen. The giant model proves the capability frontier, the small model makes it accessible. We’re likely months away from a distilled GLM-5.2 variant that matches Claude Sonnet’s creative writing ability on consumer hardware.
The Verdict
GLM-5.2 is the most important open-weight model release of 2026 so far. It’s not the absolute best at any single task, but it’s the most balanced, the most open, and the most accessible frontier model the community has seen.
| Task | Verdict |
|---|---|
| Creative Writing | Best open model, competitive with Claude Opus 4.6 |
| Coding (SWE-bench) | Beats GPT-5.5, within 7% of Opus 4.8 |
| Reasoning (AIME) | 99.2%, nearly flawless |
| Agentic Tasks | Strong, with built-in anti-hack mechanisms |
| Local Deployment | Viable on 256GB Mac or mid-range workstation |
| Price | MIT-licensed, free on Hugging Face |
The critics will point to the lack of independently verified benchmarks for GLM-5.2 specifically (vs. GLM-5.1). They’ll note that the model demands more hardware than most developers have. Both criticisms are valid. But they miss the point.
This model exists. It’s free. It’s yours. And in a landscape where the frontier can be revoked with a single executive order, that’s not just a technical advantage, it’s a fundamental shift in power.
The open-weight future isn’t coming. It’s running at 3 tok/s on your Mac Studio right now.