
The $7.62 Disruption: How GLM-5 Exposes the Frontier Model Tax
GLM-5 achieves 95% of Claude Opus performance at 11x lower cost in the YC-Bench startup simulation, forcing a complete rewrite of enterprise AI procurement strategies.

The next time your CFO asks why the AI budget tripled, you might want to sit down. A new benchmark called YC-Bench just dropped a grenade into the center of enterprise AI procurement: GLM-5 is running within 5% of Claude Opus 4.6’s performance at one-eleventh the API cost. We’re talking $7.62 per run versus $86. In a simulated year-long startup test where nine out of twelve models went bankrupt, the Chinese underdog from Zhipu AI didn’t just survive, it nearly matched the industry’s most expensive reasoning model while spending pocket change.
If you’re still budgeting for AI like it’s 2024, you’re paying a frontier model tax that no longer buys you immunity from failure.
What YC-Bench Actually Measures (Hint: Not Another MMLU)
Most LLM benchmarks are multiple-choice speed runs that tell you nothing about production reality. YC-Bench is different. It simulates a full year of startup operations, hundreds of turns managing employees, payroll, contract selection, and cash flow. The twist? Feedback is delayed and sparse. You don’t know immediately if a decision was good. You find out weeks later when the client turns adversarial or the payroll hits.
The environment is brutal: ~35% of clients secretly inflate work requirements after you accept their contracts, deadlines compound, and your context window truncates to the last 20 turns. It’s a test of long-horizon coherence under uncertainty, the exact scenario where most “intelligent” agents collapse into loops or burn cash on bad decisions.
The Results Were Stark
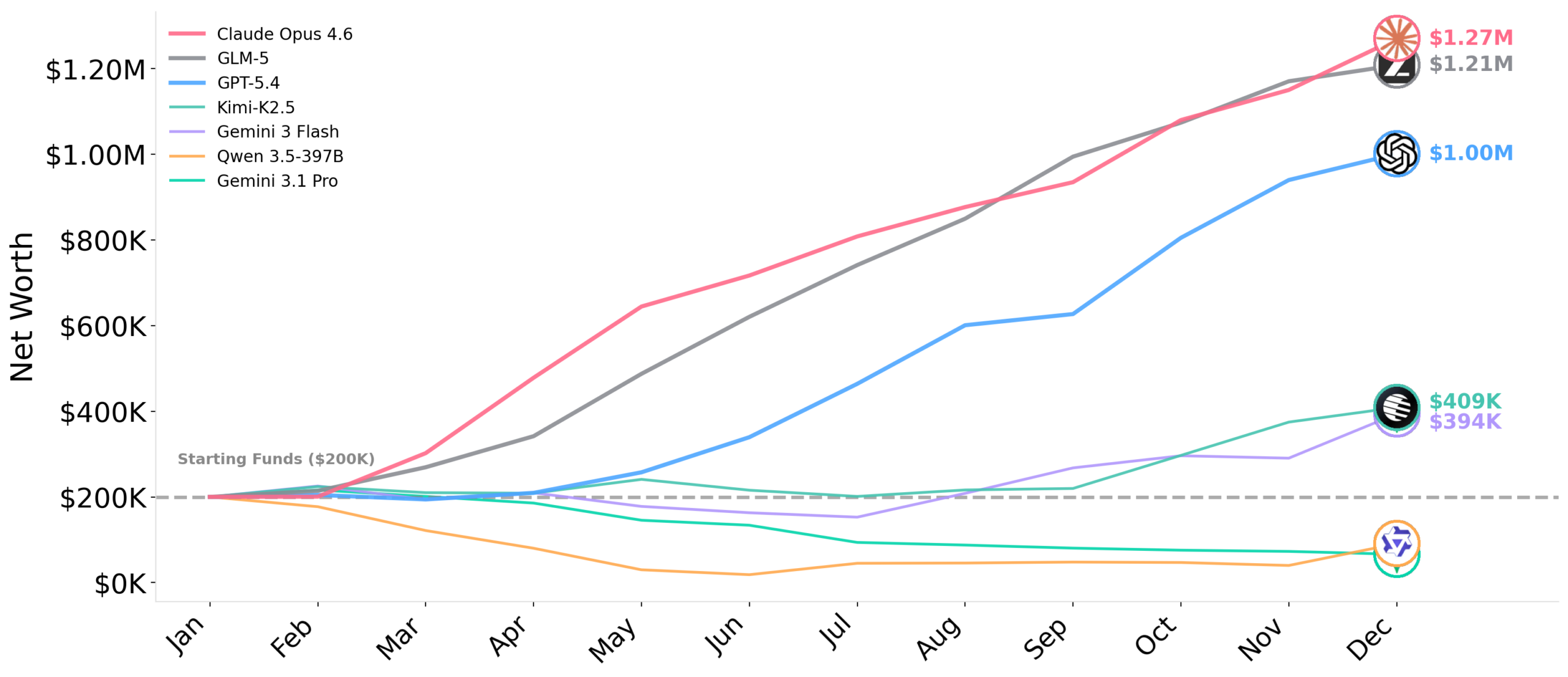
Out of 12 models tested across 3 seeds each, only three consistently surpassed the $200K starting capital.
| Rank | Model | Avg Funds | Cost/Run |
|---|---|---|---|
| 1 | Claude Opus 4.6 | $1.27M | ~$86 |
| 2 | GLM-5 | $1.21M | ~$7.62 |
| 3 | GPT-5.4 | $1.00M | ~$23 |
| 4 | Kimi-K2.5 | $409K | – |
Bankruptcy Rate Warning
Nine models, including Grok 4.20 Beta, Gemini 3.1 Pro, and Claude Sonnet 4.6, ended the year with less money than they started, several hitting zero. The “frontier” label didn’t save them from bankruptcy.
Key Success Factors
- Persistent scratchpad usage
- Client trust scoring mechanisms
- Adversarial pattern detection
- Efficient context utilization (80K+ tokens)
The Scratchpad Secret: Memory Beats Size
Memory Architecture Advantage
Top performers like Opus and GLM-5 actively used their persistent scratchpads, their only mechanism for retaining information across context truncation, to record what they learned about clients, employees, and strategies.
They rewrote their notes approximately 34 times per run.
Bottom models averaged 0-2 entries and often abandoned strategies they had just written down.
Why This Matters
This exposes a critical shift in what makes models production-ready. Raw reasoning ability means nothing if you can’t remember why you made a decision three hours ago.
GLM-5’s architecture clearly prioritizes this form of persistent state management, allowing it to maintain strategic coherence over long horizons without the premium pricing of Anthropic’s flagship.
Adversarial Clients: The $340 Afternoon
The primary failure mode was illuminating: adversarial client detection. Nearly half of all bankruptcies (47%) came from models accepting tasks from clients who inflated work requirements post-contract. Top models spotted the pattern and wrote explicit blacklists to their scratchpads. The rest distributed tasks indiscriminately, accepting high-reward contracts from clients with 0% success rates.
Production Reality Check
This mirrors what we see in production agentic pipelines. Models that look great on HumanEval collapse when faced with delayed feedback loops or hostile inputs. The scrutiny of efficiency claims through rigorous benchmark comparisons is becoming essential because synthetic benchmarks no longer predict real-world financial survival.
The Revenue-Per-Dollar Dark Horse
While GLM-5 dominates the raw performance-per-cost metric, Moonshot AI’s Kimi-K2.5 actually tops the revenue-per-API-dollar chart at 2.5× better than the next model. It generated $409K in final funds on a fraction of the cost, suggesting that for pure economic efficiency, maximizing return on inference spend, there are even more aggressive options than GLM-5, albeit with higher variance (Kimi went bankrupt in 1 of 3 seeds).
The implications for production budgeting are seismic. If you’re running agentic pipelines at scale, the difference between $86 and $7.62 per run isn’t marginal, it’s the difference between a viable product and a burning pile of VC money.
Production Implications: The End of the Frontier Moat
The immediate takeaway for engineering teams is brutal: there is no frontier model moat anymore. The only real competitive advantages left in enterprise AI are infrastructure, compliance, and unit economics.

Implement Model Cascades
If you’re building production systems, you need to implement model cascades immediately. Route simple queries to GLM-5 or Kimi-K2.5, escalate to Opus only for the 15% of tasks that actually require maximum reasoning capability, and pocket the 60-80% cost savings.
When to Still Pay the Premium
This doesn’t mean Claude Opus is dead. For tasks requiring Level 9-10 creative synthesis or maximum reasoning (GPQA Diamond scores above 90%), Opus still justifies its price.
But for the 80% of agentic workflows that involve document processing, code generation, or multi-step business logic, you’re paying 11× for capabilities you aren’t using.
Comparisons of small parameter models competing with larger counterparts suggest this trend is accelerating. GLM-5 is just the most dramatic example of a broader shift: the gap between open-weight and proprietary models has closed for everything except the absolute bleeding edge of reasoning tasks.
The Infrastructure Pivot
For teams running high-volume inference, the math now favors alternative computing infrastructures to reduce backend expenses. When your per-run cost drops below $8, self-hosting GLM-5 on optimized hardware can beat API pricing for workloads above ~1M tokens per day.
Effective Context Utilization
The benchmark also validates what many practitioners suspected: effective context utilization matters more than advertised context length. NVIDIA’s RULER benchmark shows models reliably use only 50-65% of their advertised context window. GLM-5’s efficiency likely stems from better utilization of its 80K context window rather than brute-force scaling.
The New Procurement Playbook
- Implement aggressive model tiering. Use GLM-5 or Kimi-K2.5 for the “retrieve and grade” steps in your agentic RAG pipeline, escalating to Opus only for final generation on complex queries. This cuts costs by 70% while preserving 95% of quality.
- Invest in scratchpad persistence. The benchmark proves that models which can’t maintain persistent state fail in long-horizon tasks. Ensure your agent architecture includes explicit memory management, not just context window stuffing.
- Monitor adversarial patterns. The 47% bankruptcy rate from adversarial clients suggests your production systems need explicit “client trust” scoring and blacklisting mechanisms, not just reactive error handling.
- Re-evaluate your “frontier” budget. If you’re spending $25/M output tokens on Claude Opus for tasks that GLM-5 handles at $2.30/M, you’re lighting money on fire. Strategies to reduce dependency on cloud API pricing should be on every platform team’s roadmap.
The YC-Bench results aren’t just a leaderboard update, they’re a market correction. The era of paying premium prices for marginal gains is ending. GLM-5 didn’t just match Claude Opus, it proved that the emperor’s new clothes cost $78.38 too much.



