Most engineers have stared at a whiteboard at 2 AM, wondering if their Kafka setup will survive the first real traffic spike or if their database scaling strategy is secretly a ticking time bomb. The question isn’t whether you need validation, it’s what to do when the senior architect who could sign off on your design is either too busy, too expensive, or doesn’t exist yet.
The Reddit thread that sparked this discussion hits a nerve because it exposes a dirty secret: senior architecture reviews are a luxury that many teams can’t afford, either in time or availability. Yet shipping unvalidated architecture is how you end up with systems that collapse under their own weight, and careers that collapse with them. The good news? There’s a playbook for validating architecture without waiting for the mythical senior reviewer to descend from the ivory tower.
The Peer Review Mirage (And What Actually Works)
The most upvoted advice in the thread is deceptively simple: talk to your teammates. Not in a formal review meeting, but in casual 1:1s and brainstorming sessions. The key is treating architecture as a collaborative sport rather than a solo performance. When you finally write the design doc, list those early brainstorm participants as contributors. This isn’t just political cover, it’s distributed sense-making.
But there’s a catch, and the thread exposes it immediately: the Dunning-Kruger effect is real, and outspoken junior engineers can derail a design with confident ignorance. The solution isn’t to avoid peer input, it’s to structure it. One engineer pointed out that most docs have “approved reviewers” separate from commenters, mirroring code review workflows. Anyone can view and comment, but only designated reviewers can sign off. This creates a meritocracy of feedback while preventing the loudest voice from winning.
This approach directly addresses the risks of unreviewed architecture in production systems. When you can’t get senior review, you need guardrails that scale with your team’s expertise, not against it.
Break It Before It Breaks You: The Isolation Test
One experienced engineer’s approach is brutally pragmatic: “When I don’t have experience in a particular technology, I set up a dummy load test in isolation to try to break it, then scale accordingly.” This isn’t fancy, but it’s effective. Before you bet your production system on Kafka or that new database replication scheme, you build a minimal version and throw synthetic traffic at it until it cries uncle.
The methodology is straightforward but requires discipline:
- Understand your cloud provider’s service limits before you hit them unexpectedly
- Model the scaling profile of each component, does it scale linearly, exponentially, or fall off a cliff?
- Run integration scale tests in dev environments that mirror production topology
- Have a fallback plan that isn’t “hope for the best”
This is where validating performance claims in optimized frameworks becomes relevant. Whether it’s a database or an AI framework, vendor benchmarks lie. Your traffic patterns are unique, and the only way to know if something works is to break it yourself.
Documentation as Validation: The Mermaid Diagram Revolution
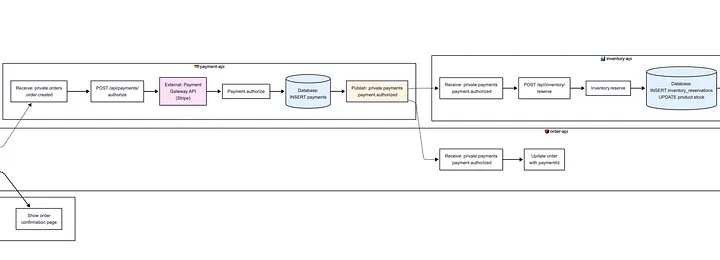
The most sophisticated approach comes from the O’Reilly article about reverse-engineering architecture with Claude Code. The author discovered that forcing yourself to document end-to-end flows in excruciating detail, using Mermaid diagrams with strict rules, is itself a validation exercise.
The process is illuminating:
### diagram.mermaid Requirements
**CRITICAL RULES:**
1. **File Format**: Must be pure Mermaid syntax with `.mermaid` extension- NO markdown headers
- NO markdown code fences (no ```mermaid wrapper)
- Starts directly with `flowchart LR`
2. **Use Swimlane Format**: `flowchart LR` (left-to-right with horizontal swimlanes)
- Each repository is a horizontal swimlane (subgraph)
- Flow progresses left to right
The act of mapping every API call, database interaction, and event publication forces you to confront gaps in your understanding. When you can’t draw the flow, you don’t understand it. The article’s example shows a 27-step e-commerce flow that covers everything from order creation to shipment, with explicit failure scenarios. This level of detail isn’t for executives, it’s for catching your own mistakes.

This approach aligns perfectly with visual validation tools for complex systems. When senior reviewers are scarce, rigorous visual documentation becomes your first line of defense against architectural drift.
Checklists and Frameworks: The ATAM Method
For those who want more structure, the thread mentions ATAM (Architecture Tradeoff Analysis Method) as a way to evaluate risks systematically. While the video link provided is a start, the real value is in adopting a checklist mentality:
- Scalability risks: Where will this break under load?
- Complexity costs: How hard is this to debug at 3 AM?
- Change velocity: Can we modify this without a rewrite?
- Operational burden: What’s the pager load?
One engineer is exploring “structural reasoning prompts” to help less experienced engineers think through these steps earlier. This is essentially creating a decision framework that encodes senior-level thinking into a repeatable process. It’s not as good as having a senior architect, but it’s infinitely better than winging it.
This is where established data modeling patterns for layered architectures become useful reference points. You don’t need to reinvent the wheel, you need to know which wheels have been proven to work.
Measure or It Didn’t Happen
The thread’s most brutally honest advice: “If you’re making a big change to solve X, you need to measure X now, and measure X afterwards. Otherwise you’re just pissing in the wind.” This seems obvious, but it’s the most skipped step in architecture validation.
The key is deciding what to measure before you build. Are you optimizing for latency? Throughput? Error rates? Cost? Each goal requires different validation strategies:
| Goal | Validation Method | Failure Indicator |
|---|---|---|
| Latency | Load testing with percentile tracking | P99 > 500ms |
| Throughput | Gradual ramp to predicted peak | Saturation at < 80% target |
| Cost | Load testing with cloud billing alerts | Cost per request > target |
| Reliability | Chaos engineering (kill instances) | Error rate > 0.1% |
This metrics-first approach is how you avoid the real-world consequences of unreviewed data migrations. When you can’t get architectural review, you must get data.
The Ultimate Validation: Can You Change It?
One commenter reframed the entire discussion: “The telltale sign of a good architecture is that it is easy to change. The real question is not ‘will this handle the load?’ but ‘how hard will it be to change?'” This is the senior architect’s secret filter.
An architecture that handles today’s load but requires a rewrite to add a new feature is a failure. An architecture that struggles under load but can be scaled incrementally is a success. This perspective shift changes how you validate:
- Modularity: Can you replace components without touching others?
- Observability: Can you understand behavior without reading every log line?
- Deployment: Can you ship changes without downtime?
- Rollback: Can you revert quickly when things go wrong?
This is particularly relevant when considering architectural trade-offs in local vs. cloud deployments. The “right” choice depends entirely on which option makes your architecture more malleable.
AI as Reviewer: The Promise and Peril
The O’Reilly article takes this further by using Claude Code as a synthetic reviewer. The author created a 449-line requirements document and had Claude generate Mermaid diagrams cross-referencing multiple repositories. The AI identified affected flows during incident response and suggested debugging steps.
But there’s a catch: hallucinations. The article notes “significant inaccuracies that I had to spot and correct. (Imagine if I didn’t know they were wrong.)” This is the core problem with AI-assisted validation, it’s only as good as your ability to spot its mistakes.
The workflow is promising though:
- Feed Claude your architecture docs with strict formatting rules
- Ask it to identify gaps in flows or missing event consumers
- Use it during incidents to map production issues to architectural components
- Iterate on the requirements to make the process repeatable
This is where the dangers of unvalidated AI agent architectures become starkly relevant. If you can’t validate your architecture, and you can’t validate your AI’s validation of your architecture, you’re in a recursion of risk.
The Platform Engineering Escape Hatch
The O’Reilly article ends with a compelling vision: platform engineering teams should build frameworks that expose system dependencies as a graph, making reverse engineering unnecessary. Instead of documenting flows manually, the platform should generate them automatically as a side effect of following the “paved path.”
This is the ultimate answer to the original Reddit question. If you can’t get senior review, make validation automatic:
- Event schemas that self-document consumption patterns
- Service meshes that generate dependency graphs
- Infrastructure as Code that enforces limits and fallbacks
- CI pipelines that run chaos tests on every deploy
Companies that do this, especially startups without legacy baggage, can move faster with less risk. The architecture validates itself through usage, not through review meetings.
Practical Validation Without Seniors
So what does this mean for the engineer staring at that whiteboard at 2 AM? Here’s the playbook:
For immediate validation:
– Grab a teammate and whiteboard the flow. Don’t wait for a formal review.
– Set up a minimal load test this week. Use k6 or Artillery to find the breaking point.
– Write the Mermaid diagram. If you can’t draw it, you don’t understand it.
For systematic improvement:
– Build a personal checklist based on ATAM or similar frameworks.
– Start measuring your system’s key metrics today, before you need them.
– Document one end-to-end flow per sprint. Make it a habit.
For long-term survival:
– Push your platform team to auto-generate dependency graphs.
– Treat architecture as living documentation, not a one-time decision.
– Remember: the goal isn’t perfection, it’s changeability.
The senior architect you’re waiting for doesn’t have magical answers. They have checklists, experience, and a bias for testing. You can replicate that today, and your future self (who’s debugging at 3 AM) will thank you.