The data engineering community is experiencing a collective eye-roll moment. A recent Reddit rant captured a sentiment spreading through technical circles: Databricks’ marketing team has earned their year-end bonus by convincing a new generation that organizing data into Bronze, Silver, and Gold layers is somehow revolutionary. The critique stings because it contains truth, these patterns have been documented for over 30 years. But the full story is more nuanced than either the marketing claims or the backlash suggest.
The Spark That Lit the Fire
The controversy ignited when a veteran data engineer questioned whether modern tooling discussions have replaced actual engineering. The core complaint: teams are obsessing over Databricks configurations while losing sight of fundamental principles. The post pointed out that the number of people using “medallion architecture” terminology has exploded, yet many believe they’re implementing something genuinely new.
This disconnect matters. When organizations think they’re adopting cutting-edge innovation, they may overlook that they’re simply using established patterns with new branding. The result? Confusion, inflated expectations, and sometimes, massively over-engineered solutions for simple problems.
What Medallion Architecture Actually Is (According to Databricks)
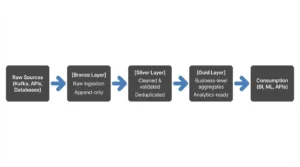
Let’s examine the modern framing. Medallion architecture organizes data lakes into three refinement layers:
- Bronze Layer: Raw Data Ingestion
– Stores data exactly as received from source systems
– Maintains complete audit trails and historical records
– Handles structured, semi-structured, and unstructured formats
– Typical storage: raw JSON, CSV, log files in cloud object storage - Silver Layer: Conformed and Cleaned Data
– Applies data quality rules and standardization
– Deduplicates records and corrects data types
– Enriches data through lookups and joins
– Creates consistent, query-ready datasets
– Typical transformations: filtering nulls, standardizing formats, validating business rules - Gold Layer: Business-Ready Analytics
– Aggregates data for specific business domains
– Optimizes for reporting and machine learning
– Delivers KPIs and curated metrics
– Often stored in columnar formats (Parquet, ORC) with compression
On the surface, this structure appears methodical and modern. Databricks positions it as a “layered approach to enhance data quality, governance, and performance.” The architecture integrates with AWS services like Glue for ETL, Athena for serverless queries, and Lake Formation for governance.
The Historical Reality Check
Here’s where the controversy deepens. These three layers map directly to concepts from the 1990s:
- Bronze = Staging Area (Kimball methodology)
- Silver = Data Warehouse (cleansed, conformed dimension)
- Gold = Data Marts (business-specific aggregations)
Kimball’s Data Warehouse Toolkit, first published in 1996, described these patterns exhaustively. The book’s influence is so pervasive that when a junior engineer recently asked about SCD Type 2 (Slowly Changing Dimensions) on Reddit, the immediate response was simply: “Kimball’s Data Warehouse Toolkit.”
What Databricks calls “medallion architecture” is essentially:
– Raw Data Lake → Cleansed Enterprise Data Warehouse → Departmental Data Marts
The terminology has changed, but the conceptual flow remains identical. Even the Bronze/Silver/Gold metaphor feels like a direct descendant of the “bronze, silver, and gold” service levels that ITIL frameworks have used since the 1980s.
The Case for Actual Innovation
Before dismissing medallion architecture entirely, we must acknowledge what Databricks genuinely contributed. The innovation isn’t in the three-layer concept, it’s in the technical implementation:
- Delta Lake Transaction Layer
Traditional data lakes suffered from the “data swamp” problem: no ACID guarantees, no schema enforcement, and no consistency. Delta Lake added transactions to cloud object storage, making the lakehouse concept viable. This is substantial engineering work, not just marketing. - Unified Batch and Streaming
Databricks collapsed the artificial boundary between batch ETL and streaming pipelines. The same code could process historical data and real-time events, a genuine advancement over separate Lambda architecture tooling. - Cloud-Native Performance
The Photon engine, written in C++, delivered data warehouse performance on open formats. This wasn’t trivial, it required reimagining query execution for cloud object storage characteristics. - Governance Integration
Unity Catalog extended governance beyond tables to include models, features, and files in a single interface. While governance itself isn’t new, the unified approach across the ML lifecycle represented progress.
The Medium article on AWS implementation shows how these pieces fit together: S3 provides unlimited storage, Glue handles transformations, and the medallion layers provide organizational structure. The pattern is old, but the serverless, scalable execution is new.
The Marketing Machine vs. Engineering Reality
The backlash isn’t about denying technical merit, it’s about intellectual honesty. When Databricks presents medallion architecture as a conceptual breakthrough, experienced engineers feel like they’re being sold their own history back to them at a premium.
One Reddit comment captured the business impact: companies pay $10K+ monthly for Databricks tables with 5 million rows, still hitting Spark JVM out-of-memory errors, when PostgreSQL would solve their problems more effectively. The tool becomes a solution in search of a problem.
This dynamic reflects a broader trend in data engineering: platform vendors creating complexity that drives lock-in. The Addepto comparison between Databricks and Snowflake reveals both platforms are converging toward each other’s strengths, but their core philosophies differ dramatically:
- Databricks: Built for engineers who want control and flexibility
- Snowflake: Built for analysts who want simplicity and speed
The medallion architecture debate sits at this intersection. Databricks needed a conceptual framework that felt approachable to business users while remaining powerful for engineers. Rebranding established patterns achieved this, it gave sales teams a story and consultants a methodology.
The Emperor’s New Clothes Moment
The real controversy emerges when we examine the gap between promise and practice. The Learnomate platform comparison highlights how Databricks “introduces the lakehouse paradigm, merging data lake flexibility with data warehouse reliability.” This sounds revolutionary until you realize it’s describing what data warehouses have always done: provide reliable, query-optimized access to curated data.
The difference is in the packaging. Kimball’s methodology required disciplined engineering and organizational buy-in. Databricks’ medallion architecture promises similar outcomes through tooling and architecture. But tools don’t replace principles, if your team doesn’t understand data modeling fundamentals, no amount of Bronze/Silver/Gold partitioning will save you.
The Reddit discussion revealed a harsh truth: only 10-20% of people with “data engineer” titles are doing actual data engineering. The rest are tool operators. When a methodology like medallion architecture becomes popular, it can create an illusion of expertise. Teams can implement the pattern without understanding why it emerged in the first place.
Platform Wars and the Lock-In Risk
The medallion architecture debate can’t be separated from the Databricks vs Snowflake competition. As the Addepto analysis shows, both platforms are racing to capture the AI market, and architectural narratives are weapons in that fight.
Snowflake’s recent embrace of Apache Iceberg and launch of Polaris Catalog are direct responses to Databricks’ Unity Catalog. Both platforms now support open table formats, reducing data lock-in but increasing platform lock-in through governance and workflow integration.
For enterprises, this creates a strategic dilemma. The medallion architecture pattern itself is vendor-neutral, you could implement it with plain S3, Glue, and Athena. But Databricks’ implementation includes proprietary optimizations that create dependency. The pattern is free, the convenient execution is expensive.
What Engineers Should Actually Focus On
The controversy offers a valuable reset opportunity. Instead of debating whether medallion architecture is innovative, engineers should focus on timeless fundamentals:
- Data Modeling Matters More Than Tools
SCD Type 2 implementations, conformed dimensions, and slowly changing hierarchies remain challenging regardless of platform. Master Kimball or Data Vault methodologies first, then apply tools. - Right-Size Your Solution
A PostgreSQL instance with 5 million rows will outperform a Spark cluster for most analytics use cases. Don’t let vendor narratives convince you that every problem requires distributed computing. - Understand the Economics
Databricks’ DBU pricing can be efficient for massive scale but expensive for small data. Snowflake’s credit model offers predictability but includes a convenience tax. Calculate 3-year TCO, not just feature checklists. - Governance Is About Process, Not Just Catalogs
Unity Catalog and Polaris are tools. Real governance requires data contracts, ownership models, and quality SLAs. No tool automates organizational responsibility.
The Verdict: Innovation in Execution, Not Concept
Medallion architecture represents genuine innovation in implementation but not in concept. Databricks successfully adapted 30-year-old patterns for cloud-native, serverless environments and unified them with modern ML workflows. That’s valuable engineering work.
The problem is the marketing narrative that positioned this as conceptual breakthrough rather than evolutionary improvement. By doing so, Databricks created confusion among engineers who should know better and enabled over-engineering among teams that should know simpler.
The backlash serves as necessary correction. It reminds us that engineering principles transcend tooling, and that understanding history prevents us from reinventing wheels at enterprise software prices.
The platforms will continue evolving. Databricks will add more low-code features, Snowflake will deepen its AI capabilities. But the medallion architecture debate will be remembered as a moment when the data engineering community questioned whether it was building the future or just rebranding the past.
Key Takeaways for Technical Leaders
- Question Narratives: When vendors present “new” architectures, map them to historical patterns. Most “innovations” are incremental improvements on proven concepts.
- Focus on Principles: Invest in team education around data modeling fundamentals. Tools change, principles endure. Kimball’s 1996 book remains more valuable than most vendor certifications.
- Calculate True TCO: Include engineering time, training, and migration costs. A $10K/month Databricks bill might be cheaper than a $2K PostgreSQL instance if it prevents a 6-month rewrite, but rarely is.
- Avoid Resume-Driven Development: Don’t adopt complex architectures because they’re trendy. The Reddit engineer who suggested PostgreSQL for 5 million rows wasn’t being contrarian, he was being practical.
- Embrace Hybrid Approaches: Use Databricks for heavy ML training, Snowflake for BI concurrency, and PostgreSQL for operational analytics. The medallion pattern works across all three.
The medallion architecture debate ultimately reveals more about the data engineering community’s maturity than about Databricks’ innovation. We’re learning to distinguish between marketing narratives and technical substance, a skill that will serve us well as the next “revolutionary” pattern emerges.
The question isn’t whether medallion architecture is good or bad, it’s whether your team understands data engineering deeply enough to implement it correctly, regardless of what you call it.