The Event-Driven Documentation Crisis Nobody Talks About
Event-driven architecture has become the default for modern distributed systems, with 72% of organizations using it in some capacity. The pattern delivers undeniable benefits: decoupled services, real-time responsiveness, and massive scalability. But there’s a growing crisis that conference talks and vendor whitepapers conveniently gloss over, documentation collapses under the weight of event-driven complexity. While teams celebrate their loosely coupled services, they’re quietly drowning in an invisible documentation debt that grows exponentially with every new event producer and consumer.
The problem isn’t that we lack documentation tools. It’s that event-driven systems break the fundamental assumptions that make traditional documentation work.
Why Event-Driven Documentation is a Different Beast
Traditional REST APIs live in a predictable world. You have endpoints, request/response schemas, and clear call chains. Tools like OpenAPI thrive here because the contract is explicit and synchronous. Event-driven architectures flip this model on its head.
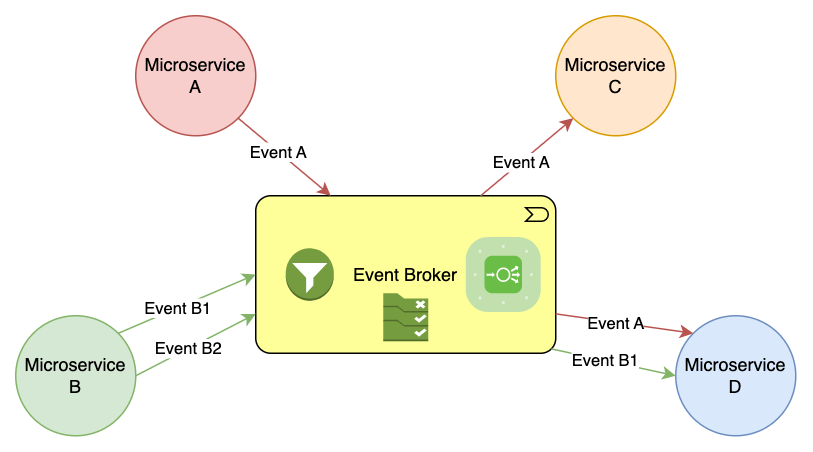
In EDA, the flow is asynchronous and non-deterministic. A single event might trigger five downstream services, or none, depending on runtime conditions. There’s no guaranteed response time. No built-in discovery mechanism. And the choreography pattern means services evolve independently, creating a documentation graph that changes in real-time.
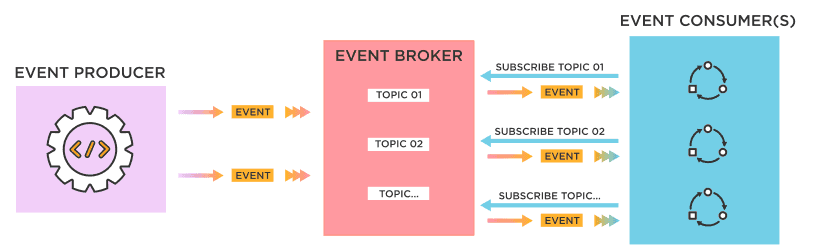
The Estuary.dev guide captures this reality: events flow through brokers without producers knowing their consumers. This decoupling is powerful for scalability but creates a documentation nightmare. How do you document something when the publisher doesn’t even know who’s listening?
What Breaks First: Insights from the Trenches
Dave Boyne, creator of the open-source tool EventCatalog, recently asked the community how they document large event-driven architectures. The responses reveal a pattern of failure modes that plague teams at scale.
Many teams start with architecture-driven documentation tools like PlantUML, C4 models, or ArchiMate. These work for static service diagrams but fail when forced to capture event specifications. The dynamic nature of events, versioned schemas, evolving topics, runtime subscriptions, doesn’t fit neatly into a box-and-arrow diagram.
What breaks first? Two critical areas:
- Specific-technology gaps: The tooling can’t keep up with the pace of schema changes, new event types, or integration requirements. When a team adds a new field to an event, does that propagate to 50 downstream consumers’ documentation automatically? It doesn’t.
- Administrative friction: Procurement cycles, compliance requirements, and the sheer overhead of maintaining documentation in regulated industries turn what should be a lightweight process into a year-long evaluation. One practitioner noted they prefer a one-year evaluation period for non-production work just to get tooling approved.
The most telling insight? The rejection of “single source of truth” claims. Vendors love this phrase, but practitioners working in heterogeneous environments know it’s a myth. When you have Kafka clusters, cloud-native message buses, legacy MQ systems, and SaaS webhooks all emitting events, no single tool can be the authoritative source. The documentation must be federated, just like the architecture itself.
The AsyncAPI Paradox
AsyncAPI emerged as the OpenAPI equivalent for event-driven systems. It provides a specification for documenting message-driven APIs, complete with schemas, channels, and bindings. In theory, it should solve the problem.
In practice? Even AsyncAPI struggles with its own documentation. A recent GitHub issue revealed a broken link in their technical writer onboarding guide, a meta-problem that highlights how documentation debt accumulates everywhere. If the maintainers of a documentation standard can’t keep their own docs current, what hope do regular teams have?
The specification is solid, but adoption reveals gaps. AsyncAPI documents individual service contracts well, but it doesn’t automatically show you the entire event mesh. You can see what a service publishes, but not the cascading effects across 100 other services. It’s a microscope when you need a satellite view.
EventCatalog and the Visualization Gap
EventCatalog attempts to bridge this gap by creating a centralized portal for events, services, and schemas. It integrates with schema registries and AsyncAPI specs to auto-generate documentation. The promise is compelling: a single place to understand your entire event landscape.
But the tool faces the same fundamental tension. As Boyne’s Reddit post acknowledges, documentation at scale requires more than aggregation. It needs context that machines can’t infer. Who owns this event? What’s its criticality? Which teams consume it? What’s the blast radius if we change this field?
These questions require human knowledge grafted onto technical specifications. Without it, you have a beautiful diagram of a system you still don’t understand.
The Schema Registry Integration Challenge
Schema registries (Confluent, AWS Glue, Pulsar) solve part of the problem by enforcing schema contracts. They provide version control, compatibility checks, and discovery. But they’re infrastructure-centric. A schema registry knows that OrderCreated-v2.avsc exists, but it doesn’t know that:
- The “orders” team owns it
- Three critical payment workflows depend on it
- A breaking change will require coordinated deployments across 12 microservices
- The field
customerIdis being deprecated in favor ofaccountId
This metadata lives in wiki pages, Slack threads, and tribal knowledge. The result? Developers trust the schema registry for syntax but ignore it for semantics, leading to silent failures and production incidents.
Learning from Data Mesh: The Event Mesh Documentation Pattern
The most promising approach borrows from Data Mesh principles: federated documentation with a unified discovery layer. Just as Data Mesh argues against centralizing all data in a monolithic warehouse, event-driven documentation shouldn’t centralize everything in one tool.
Instead, each domain team maintains its own event documentation using domain-specific tools. The finance team might use AsyncAPI specs stored in their Git repo. The logistics team might use EventCatalog for their delivery events. The core platform team might rely on Confluent’s schema registry.
The key is a thin federation layer that indexes these disparate sources and provides a unified search and visualization interface. This layer doesn’t own the documentation, it aggregates and enriches it with cross-domain dependencies.
Practical Strategies That Actually Work
1. Event Stewardship Model
Every event has an owning team and a designated steward. This person’s responsibilities include maintaining the schema, approving changes, and ensuring downstream documentation updates. It’s not a full-time role, but it’s in their performance review.
2. Documentation as Code
AsyncAPI specs and event definitions live in version control alongside the services that produce them. CI pipelines validate schemas, check for breaking changes, and auto-generate documentation on merge. Treating events like API contracts forces discipline.
3. Runtime Discovery
Static documentation ages poorly. Complement it with runtime tools that show actual event flows. Some teams build lightweight agents that subscribe to topics and report metadata to a central registry, creating a living topology map.
4. Event-Level SLAs
Document not just the schema, but the guarantees: expected throughput, latency percentiles, retention policies, and deprecation timelines. This turns documentation from a technical reference into an operational contract.
5. Federated Search Over Centralized Storage
Rather than forcing everything into one tool, invest in search that spans Git repos, schema registries, wikis, and catalogs. The goal is findability, not uniformity.
The Path Forward
The event-driven documentation crisis won’t be solved by a single tool. It requires recognizing that documentation for asynchronous systems is fundamentally different from synchronous APIs. The principles that work are:
- Federation over centralization: Accept that heterogeneity is reality
- Automation over manual upkeep: Machines should track schema versions and dependencies
- Context over contracts: Technical specs need human-curated operational context
- Runtime over static: Documentation must reflect the live system state
EventCatalog, AsyncAPI, and schema registries are pieces of the puzzle, but the complete solution is a socio-technical system that treats event documentation as a first-class concern, complete with ownership, automation, and governance.
The teams that succeed will be those that stop looking for a silver bullet and start building a documentation mesh that matches their event mesh: distributed, scalable, and resilient to change.
Until then, we’ll keep shipping broken documentation for working systems, hoping that the next incident retrospective finally prioritizes the invisible crisis hiding in plain sight.