The layered architecture diagram looks so clean on paper. You’ve seen it: staging on the left, integration in the middle, BI tools on the right, with a neat little arrow declaring “Business Logic Goes Here” pointing squarely at the integration layer. It’s the architectural equivalent of a motivational poster, aspirational, tidy, and completely detached from the chaos of production systems.
After a decade watching data teams wrestle with this question, I’ve come to a conclusion that will make purists uncomfortable: your business logic is already scattered, and trying to enforce a single layer is like herding cats with a specification document.
The Seductive Lie of “One Layer to Rule Them All”
The integration layer evangelists have a compelling story. Centralize your business logic in dbt models, they say. Version control everything. Make your BI layer dumb, just a presentation shell. The logic lives in one place, governed, tested, and blessedly consistent.
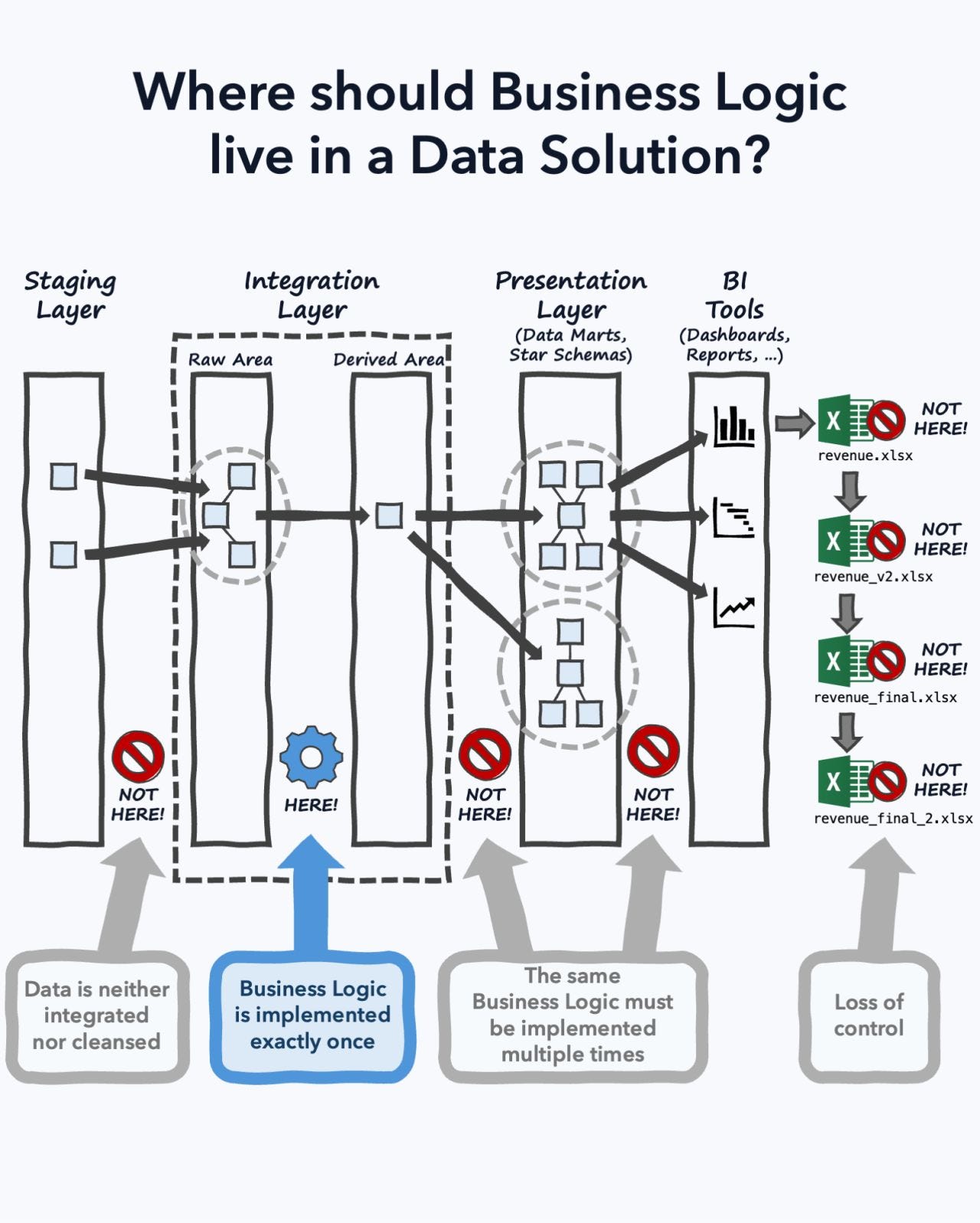
This diagram, popularized by Reinhard Mense’s LinkedIn post, triggered a collective “big brain moment” across data Twitter. Finally, clarity! But here’s what the diagram doesn’t show: the finance team’s special revenue definition that differs from GAAP reporting, the row-level security filters that vary by user role, or the DAX measures that power users insist on writing themselves because “the centralized model doesn’t account for our edge cases.”
The reality? Business logic is less a monolith and more a creeping vine, finding cracks in your architecture and sprawling wherever conditions are favorable.
What Exactly Is Business Logic, Anyway?
Before we argue about where it lives, let’s define what “it” even is. The Data Management Body of Knowledge (DAMA-DMBOK) doesn’t formally define “business logic”, it uses “business rules” instead, describing them as declarative constraints defined by the business and implemented via integration, quality, and governance practices. Helpful? Not particularly.
A more practical definition emerges from the trenches: business logic is whatever transforms raw data into something that won’t get you yelled at in a quarterly business review. This includes:
- Calculations and aggregations (the obvious stuff)
- Data quality and cleansing procedures
- Definitions (what counts as “active user” vs “churned”)
- Local definitions (Sales’ revenue vs Finance’s revenue vs Product’s revenue)
- Filters and row-level security
- User-interaction-based logic that changes based on who’s asking
This list isn’t academic, it’s a direct inventory from data teams who’ve discovered that “business logic” is whatever the business decides it is, semantics be damned.
The Three-Body Problem: Where Logic Actually Ends Up
Let’s examine the three primary gravitational fields pulling at your business logic:
1. The Database Layer: “Just Use Constraints and Stored Procedures”
Database purists argue that business logic belongs as close to the data as possible. Use CHECK constraints, EXCLUDE constraints, and well-designed schemas to enforce rules at the source. The logic outlives application code, they say, and using database constraints to enforce business rules ensures data integrity no matter what touches it.
The problem: Modern data warehouses aren’t just PostgreSQL instances anymore. You’re dealing with Snowflake, BigQuery, Databricks, and a half-dozen other engines with wildly different constraint support. Plus, versioning stored procedures is a nightmare, and testing them is about as fun as debugging a production incident at 2 AM. The moment you need to support multiple database engines, you’ve created a portability nightmare.
2. The Application Layer: “Keep the Database Dumb”
The traditional software architecture stance: business logic belongs in the application tier, where you have proper version control, testing frameworks, and deployment pipelines. The database is just a persistence layer.
The problem: In modern data architectures, “the application” is a dozen different things: your ETL jobs, dbt models, BI tools, Jupyter notebooks, and that one executive’s Excel file that somehow became mission-critical. When five different tools are calculating “customer lifetime value” differently, you don’t have a single source of truth, you have a source of endless debate.
3. The Transformation Layer: The dbt Evangelist’s Dream
This is where the modern data stack has placed its bets. dbt’s entire value proposition is that you define business logic in version-controlled SQL models. The dbt documentation explicitly states that users should focus on writing models that reflect core business logic, with reusable transformations that prevent analytic errors.
The recommended structure is telling:
models/
├── staging/
│ ├── jaffle_shop/
│ └── stripe/
├── intermediate/
│ └── finance/
└── marts/
├── finance/
└── marketing/
This hierarchy encodes a philosophy: move from source-conformed data to business-conformed data. The staging layer cleans and standardizes, intermediate models handle complex transformations, and marts deliver business-defined entities ready for consumption.
The problem: Even dbt’s own best practices acknowledge the spillover. Their documentation warns against splitting staging by business group (no marketing/ vs finance/ subfolders) to maintain a single source of truth. Yet the mart layer explicitly groups by department. The contradiction is the point: different business units need different views of the same concept.
The Cost of Architectural Purity
Here’s where the debate gets expensive. MotherDuck’s analysis of traditional cloud warehouses reveals a brutal reality: idle compute charges create a 300x markup on actual usage. A dashboard running ten 2-second queries gets billed for ten minutes because of 60-second minimums. This isn’t a rounding error, it’s architectural taxation.
Teams trying to force all logic into the transformation layer often create monstrous dbt DAGs that take hours to run. Every tweak to a business rule requires rebuilding downstream models. The “single source of truth” becomes a single point of failure. One company’s attempt to centralize everything resulted in an 8-hour pipeline that engineers were terrified to touch.
The alternative? A lean stack using open storage (Parquet on S3) and serverless compute (DuckDB/MotherDuck) delivers 70-90% cost reductions and sub-second query responses. But here’s the kicker: this architecture works because it acknowledges that not all business logic belongs in the transformation layer. The hybrid execution model lets you process data where it lives, local for development, cloud for production, acknowledging that context matters.
The “As Soon As Possible, But No Earlier” Principle
The most honest answer to “where should business logic live?” comes from Leszek Michalak’s Substack post: as soon as possible, but no earlier than required by the business case.
This isn’t a dodge, it’s a survival strategy. Let’s break down what this means in practice:
Put It in the Integration Layer When:
- The logic is stable and universally accepted (e.g., “an order must have a customer_id”)
- It prevents data quality issues downstream
- It reduces duplication across multiple consumers
- You need version control and testing
Example: Calculating total_order_value from line items belongs in dbt. Every dashboard, API, and analyst needs this number the same way.
Put It in the Mart Layer When:
- Different departments have legitimate, irreconcilable definitions
- The logic is specific to a business unit’s context
- Performance requires pre-computation
Example: revenue for Sales (bookings) vs Finance (recognized revenue) vs Product (active user revenue). These aren’t bugs, they’re features of how different teams operate.
Put It in the BI Layer When:
- Users need exploratory flexibility
- Calculations depend on user interactions or parameters
- The logic is ad-hoc and experimental
Example: A power user building a cohort analysis with custom date ranges and segmentations. Forcing this into dbt creates a bureaucratic nightmare of pull requests for one-off analyses.
The Governance Nightmare You Cannot Avoid
Here’s where architectural decisions become organizational politics. When business logic lives in multiple layers, who owns it? The data team? The analytics engineers? The BI developers? The finance analysts who wrote that gnarly DAX measure?
The dbt documentation’s warning against finance_orders and marketing_orders models is correct in spirit but impossible in practice. When finance needs to report revenue to the government differently than how marketing measures campaign ROI, you have two choices:
- Create separate marts with clear naming (
tax_revenuevscampaign_revenue) - Let the logic leak into BI tools and pray
Option 1 is better, but it requires governance discipline. You need:
– Clear ownership: Who decides when a new mart is justified?
– Testing at every layer: Not just in dbt, but in your BI tool’s measures
– Documentation: Why does this logic live here and not there?
– Monitoring: Architectural health metrics that detect when logic is duplicating
Without this “business logic sprawling everywhere”, with leadership unwilling to invest in cleanup because “it works, sort of.”
The Modern Stack Forces Your Hand
The rise of tools like DuckDB and Polars isn’t just about performance, it’s about acknowledging that data architectures are distributed systems whether we like it or not. Modern data engineering tools run locally, in the cloud, and everywhere in between. Trying to pretend there’s “one true layer” is like managing a monorepo as if it’s a monolith, technically possible but practically painful.
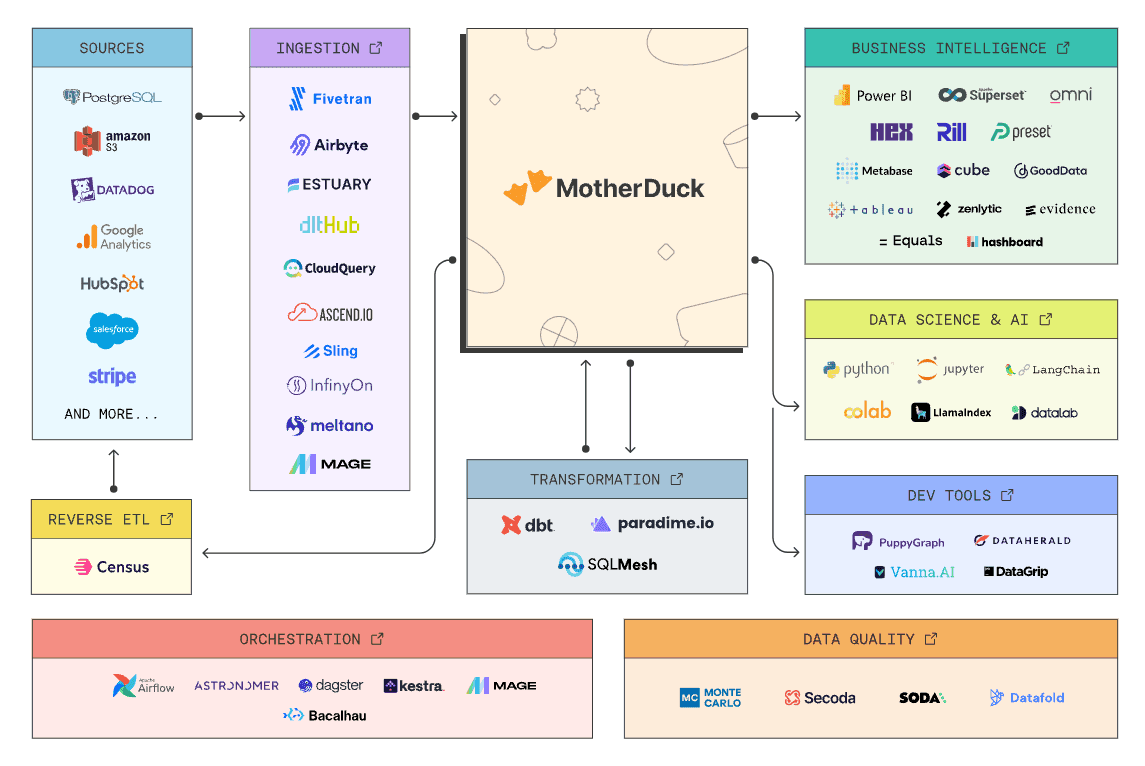
This isn’t a clean pipeline, it’s a ecosystem. Ingestion tools handle API quirks, dbt models business concepts, the warehouse executes queries, and BI tools add interactive logic. Each layer adds value because each layer has different constraints.
Practical Rules for the Real World
- Default to the transformation layer: Start with dbt. It’s version-controlled, testable, and the best place for shared logic.
- Document your exceptions: When logic must live elsewhere, write down why. “Finance revenue calculation lives in the finance mart because it uses tax rules that don’t apply to other departments.”
- Test at the boundary: If BI tools contain business logic, test the output against dbt models. A simple nightly job that compares “revenue in dbt” vs “revenue in BI” catches drift.
- Embrace semantic layers carefully: dbt’s Semantic Layer promises to centralize metric definitions, but it works best when your marts are normalized. If you’re heavily denormalized (and most teams are), you might be fighting the tool.
- Monitor for duplication: Use architectural health metrics to detect when the same calculation appears in multiple layers. A sudden spike in “revenue” definitions is a smell.
- Protect your core: Use CI/CD to fail the build when business logic changes lack tests or documentation. Architectural erosion happens one untested PR at a time.
The debate over where business logic should reside has no clean answer because it’s the wrong question. Business logic isn’t a monolith to be placed, it’s a living system that evolves with your organization. The data warehouse that treats the transformation layer as a fortress will find logic sieging the gates, tunneling under the walls, and occasionally being smuggled in via Excel.
The teams that succeed aren’t the ones with the purest architecture. They’re the ones who acknowledge the mess and govern it anyway. They have clear rules for when to break the rules. They test exhaustively. They document religiously. And they accept that “single source of truth” is a continuum, not a boolean.
Your business logic is already compromised. The question is whether you’re managing the compromise or pretending it doesn’t exist.



