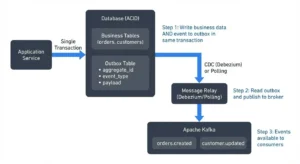
The monorepo versus microservices debate has always been framed as a cage match: centralized versus distributed, simplicity versus scalability, team cohesion versus deployment velocity. But that framing was always a false dichotomy, and the teams building with Nx, Kafka, and CQRS are proving it. They’re creating unified codebases that behave like distributed systems, delivering the best of both worlds while quietly making pure microservices look like an expensive hobby.
The architecture pattern is deceptively simple: use Nx to manage your monorepo’s complexity, Kafka to decouple services at runtime, and CQRS to maintain clear boundaries within your domain logic. The result is a system that deploys from a single Git repository but runs like a fleet of autonomous services. The controversial part? It often scales better than traditional microservices, with none of the operational tax.
The Monorepo That Grew Up
Traditional monorepos failed because they were just big repositories. They had no opinion about how code should interact, no enforced boundaries, and no tooling to prevent the dependency graph from becoming a tangled mess. Nx changes this by treating your codebase as a compute graph where every project is a node and every import is an edge. This isn’t just marketing fluff, the tool actually understands your architecture.
The Nx monorepo boilerplate demonstrates this philosophy perfectly. The repository structure is deliberately partitioned:
apps/contains runnable services likeaction-log-serviceandclient-apipackages/houses shared libraries for domain logic, application layer, and infrastructuretools/manages database migrations, Docker publishing, and CI/CD orchestration
This separation means each app can be built, tested, and deployed independently while sharing common infrastructure. The nx.json configuration enforces boundaries: a frontend developer can’t accidentally import server-side database code because the dependency graph won’t allow it. This is architectural enforcement through tooling, not convention.
The real magic happens in the packages/application layer, where CQRS patterns create natural service boundaries without requiring separate repositories or deployment pipelines.
CQRS as the Brain, Kafka as the Nervous System
Command Query Responsibility Segregation gets a bad reputation for complexity, but that’s because most implementations try to bolt it onto existing systems. In a greenfield Nx monorepo, CQRS becomes the default organizing principle. Every operation is either a command (changes state) or a query (reads state), and the infrastructure makes this explicit.
The boilerplate’s IBus interface is elegantly minimal:
export interface IBus {
commandCreate<T>(command: ICommand): Promise<Result<T>>,
commandUpdate<T>(command: ICommand): Promise<Result<T>>,
query<T>(query: IQuery): Promise<Result<T>>,
}
This abstraction does two critical things. First, it forces developers to think about the nature of their operations upfront. Second, it provides a seam where you can inject different transport mechanisms. During local development, MemoryBus passes messages in-process. In production, Kafka takes over.
The messaging layer demonstrates how this works in practice. Messages are strongly typed, validated, and routed to specific topics:
export interface IMessage<T = MessagePayload> {
key: string,
topic: string,
value: T,
messageType: string,
compression?: CompressionTypes,
}
export const LOG_TOPIC = 'logs',
export const MAIN_TOPIC = 'main',
export const ACTION_LOG_TOPIC = 'action-log';
This design eliminates the ambiguity that plagues event-driven architectures. When you publish a LogMessageEvent, the topic, schema, and validation logic travel together. The event-driven documentation crisis that haunts most Kafka implementations becomes a non-issue because your type system is your documentation.
The CreateActionLogCommand shows how commands flow through the system:
export class CreateActionLogCommand implements ICommand {
constructor(public readonly userId: string, public readonly action: string) {}
}
@CommandHandler(CreateActionLogCommand)
export class CreateActionLogCommandHandler implements ICommandHandler<CreateActionLogCommand> {
constructor(/* inject repositories/services */) {}
async execute(command: CreateActionLogCommand): Promise<Result<void>> {
// Business logic: check user exists, save action log entry
}
}
Notice how the handler is completely transport-agnostic. It doesn’t know whether it’s being called from an HTTP controller, a Kafka consumer, or a test suite. This decoupling is what makes the architecture resilient. You can refactor your deployment topology without touching business logic.
The Deployment Topology Flex
Here’s where the controversy gets spicy. Most teams choose between monoliths (single deployment) and microservices (many deployments). The Nx-Kafka-CQRS pattern says: why choose?
The boilerplate includes three distinct applications: client-api, action-log-service, and a minimal React frontend. Each has its own Dockerfile and can be deployed independently. But they all share the same domain models, validation logic, and infrastructure code. You’re not duplicating effort across repositories, you’re selectively scaling what needs to scale.
The automated versioning system demonstrates this flexibility. When you run nx run action-log-service:publish-docker, the system:
- Bumps the semantic version using conventional commits
- Tags the Git repository with
action-log-service-0.0.8 - Builds and publishes a Docker image with the matching version tag
This gives you microservices-style independent deployability without microservices-style repository sprawl. The client-api might deploy ten times a day while action-log-service deploys weekly, and neither team needs to coordinate beyond maintaining backward compatibility in their Kafka message schemas.
Compare this to the microservices tax that most organizations pay: duplicated CI/CD pipelines, inconsistent tooling, version drift across services, and the operational overhead of monitoring dozens of repositories. The monorepo approach collapses that complexity into a single source of truth.
The Database Question
The boilerplate uses PostgreSQL with MikroORM, but critically, it separates schemas for different concerns. The main application data lives in one schema, action logs live in another. This isn’t just a performance optimization, it’s a domain boundary enforcement mechanism.
You might be tempted to reach for a polyglot persistence strategy, but Postgres already won the scalability wars for good reason. The boilerplate’s approach shows how to get the benefits of separate databases (isolation, independent scaling) while keeping operational simplicity. You can replicate schemas independently, optimize them for different query patterns, and even move them to separate physical instances later, all without changing application code.
The PersistenceModule in the infrastructure layer abstracts this away. Services don’t know or care whether they’re talking to a local schema or a remote database cluster. This is the anti-corruption layer in action: your domain logic remains pure while infrastructure concerns adapt to changing requirements.
The Migration Path Nobody Talks About
The most controversial aspect of this architecture is how it enables incremental adoption. Most monorepo migrations are pitched as big-bang rewrites. The Nx-Kafka-CQRS pattern supports a strangler fig approach where you carve out services one at a time.
Start with your existing monolith in the apps/ directory. Extract shared logic into packages/domain. Implement new features using CQRS patterns. When a bounded context becomes stable enough, give it its own database schema. When load demands, move it to a separate deployment target.
This is where the strangler fig needs an anti-corruption layer becomes critical. The messaging layer acts as that layer, old parts of your monolith can publish events to Kafka, new services can consume them, and neither side needs to understand the other’s internals. You’re not rewriting, you’re gradually replacing while maintaining business continuity.
The Operational Reality Check
Let’s address the elephant in the room: doesn’t this just move complexity from repository management to operations? Yes, but it’s a tradeoff that favors the majority of teams.
With pure microservices, every team needs DevOps expertise, every service needs its own monitoring and logging configuration, and every deployment pipeline is a snowflake. In the Nx monorepo, you centralize operational concerns. The HealthModule uses Terminus to expose standardized health checks across all services. The LogModule centralizes error tracking with Errsole. The ConfigurationModule ensures consistent environment variable handling.
This consistency is the operational equivalent of DRY (Don’t Repeat Yourself). When you fix a security vulnerability in the BullModule queue configuration, you fix it for every service that uses background jobs. When you upgrade the Kafka client library, you upgrade it once. The alternative is playing whack-a-mole across dozens of repositories with slightly different versions and configurations.
The Team Topology Implications
This architecture enables what Team Topologies calls “stream-aligned teams” without requiring each team to be a full-stack DevOps squad. A team can own the action-log-service end-to-end, domain logic, infrastructure, deployment, while still benefiting from shared tooling and centralized platform capabilities.
The cognitive load reduction is substantial. New team members clone one repository, run pnpm install once, and can run the entire system locally with nx run-many --target=serve. They don’t need to understand the entire codebase to be productive, Nx’s dependency graph ensures they only build and test what they touch.
The Performance Story
Nx’s distributed task execution and remote caching mean that builds scale sublinearly with codebase size. When a developer runs tests for the client-api, Nx doesn’t build the entire monorepo, it builds only the dependencies that changed, pulling cached results for everything else. In practice, this means a 50-service monorepo builds as fast as a 5-service one.
The Kafka integration provides runtime scalability. The action-log-service can consume messages from multiple partitions in parallel. The client-api can scale horizontally behind a load balancer. You’re not trading deployment simplicity for runtime performance, you’re getting both.
The Hidden Cost of Freedom
This architecture isn’t without tradeoffs. You need discipline. The messaging layer’s validatePayload method is there for a reason, if you start publishing malformed events, you’ve created a distributed system without contracts. The CQRS pattern works until someone writes direct database queries for performance, breaking the separation of concerns.
The tooling can also become a crutch. Nx’s dependency graph is powerful, but it can’t enforce domain boundaries that exist only in your team’s head. You still need architecture decision records (ADRs) and regular review of cross-boundary imports. The monorepo makes bad decisions easier to implement and harder to detect until they become painful.
The Future Is Already Here
The most controversial claim is this: for most organizations, this pattern will replace pure microservices within five years. The economics are too compelling. You get 80% of the scalability benefits with 20% of the operational overhead. You maintain team autonomy while enforcing architectural consistency. You can start simple and evolve complexity only where it’s justified.
The ARG Software boilerplate isn’t just a starting point, it’s a statement of intent. It says that modern tooling has made the monorepo-vs-microservices debate obsolete. The question isn’t whether to centralize your code or distribute your runtime, it’s how to do both intelligently.
Your monorepo is already a distributed system. You might as well architect it like one.