A team recently hit Kafka’s default message size limit and did what most teams do: they bumped the cap. Then they bumped it again. When DevOps finally pushed back, they implemented chunking logic in their legacy system to split massive JSON files before publishing. It worked, technically, but left them with custom batching code compromising a previously stable system and a nagging feeling they’d built a Rube Goldberg machine.
What they missed was that Kafka’s message limit wasn’t a bug to fix. It was architectural feedback they were actively ignoring.
The Infrastructure Is Talking, You’re Just Not Listening
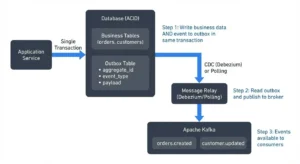
The pattern is depressingly common. A legacy system reads data from an integration database, builds a monolithic JSON payload, and fires it into a Kafka topic. Downstream services consume these bloated messages, extract what they need, and pass the remainder along. It’s a digital game of hot potato where everyone touches data they don’t need.
When messages balloon past Kafka’s 1MB default, the first instinct is infrastructural denial: “Increase the limit.” This is the architectural equivalent of treating a fever by breaking the thermometer. The measurement isn’t the problem, the underlying condition is.
The real issue? You’re treating Kafka like a file transfer protocol, not an event backbone. Messages aren’t meant to be data warehouses on wheels, they’re notifications that something happened. As one engineer bluntly put it in a discussion on this topic: “Don’t treat messages in your system as data storage (it is convenient though) but more like notifications.”
The 1.4KB Reality Check
Here’s a number that should sober you up: 1.4 kilobytes. That’s the network frame size for efficient message passing in real-time systems. When you exceed this, your messages fragment across multiple frames, introducing latency as systems wait for all the pieces to arrive. Your “just a few megabytes” message isn’t just big, it’s a performance anchor.
The team that implemented chunking discovered this the hard way. Their solution created a new problem: now they had to manage message sequencing, reassembly logic, and partial failure scenarios. What started as a simple data flow became a distributed systems problem they never signed up for.
The Claim-Check Pattern: Architecture’s Gift to Your Future Self
The proper solution, the one that makes architects nod approvingly, is the Claim-Check pattern. Instead of stuffing entire payloads into messages, you:
- Store the large data in external storage (S3, database, blob store)
- Publish a lightweight message containing only a reference pointer
- Let consumers fetch the payload only when they actually need it
This isn’t just about staying under Kafka’s limit. It’s about decoupling data from events, which is the whole point of event-driven architecture. Your messages become nimble, consumers become selective, and your system gains the superpower of independent scaling.
The beauty of this pattern is that it forces you to ask: “What does each service actually need?” Most downstream consumers don’t need the entire payload, they need a few fields to route the work and maybe a pointer to fetch details later. Claim-Check makes this explicit rather than accidental.
When Your AI Assistant Has the Same Problem
This isn’t just a Kafka problem, it’s a systems thinking problem. The same anti-pattern appeared recently in Claude Code’s GitHub issues, where users hit “context limit reached” errors despite showing only 25% token usage. The culprit? Single message size limits from base64-encoded screenshots embedded in MCP responses.
The parallel is striking: instead of streaming or referencing large data, the system was stuffing it into message payloads. The infrastructure pushed back, and users felt the pain. The proposed solution mirrors Claim-Check: configure imageResponses: 'omit' and fetch images separately when needed.
This is what infrastructure consequences of scaling inefficient data flows looks like in practice, whether you’re shoving screenshots into LLM context or JSON files into Kafka.
The Organizational Smell Behind the Technical Smell
Here’s the spicy part: increasing Kafka limits is often a political move, not a technical one. When a team can override infrastructure guardrails instead of redesigning their approach, it reveals organizational dysfunction.
DevOps pushing back wasn’t being difficult, they were protecting the system. Every increased limit has downstream consequences:
– Broker memory pressure: Larger messages consume more heap, increasing GC pauses
– Consumer complexity: Services now need more memory, more timeout tuning, more failure handling
– Replication lag: Bigger messages take longer to replicate across clusters
– Storage inefficiency: Compaction becomes less effective, retention policies get weird
The Performance Cliff You’re Ignoring
That 1.4KB number isn’t theoretical. In high-throughput scenarios, message size directly impacts:
– Network efficiency: TCP windowing works best with consistent, small packets
– Serialization overhead: Larger messages mean more CPU spent in serde
– Consumer lag: A slow consumer falls further behind when processing huge messages
– Replay pain: Reprocessing terabytes of historical data becomes a multi-day nightmare
One engineer noted that keeping messages small and event-focused “made things a lot simpler.” This is the understatement of the year. Small messages mean:
– Faster deployments (less memory tuning)
– Simpler monitoring (predictable throughput)
– Easier testing (manageable fixture data)
– Happier on-call rotations (fewer OOM kills at 3 AM)
Designing for the System You Want, Not the One You Have
The Reddit story’s ending is instructive. The team discovered that “simply looking into existing system design patterns could have saved us a lot of time.” This is the tragedy of modern software development, we’re so busy shipping that we don’t pause to ask: “Has someone else solved this?”
The efficiency gains from thoughtful model and system design don’t just apply to AI models. They apply to how we architect data flows. A 30B parameter model outperforming a 70B one is the same principle as a reference-based architecture outperforming a payload-heavy one: smart design beats brute force.
The Implementation Path Forward
- Audit your payloads: Log message sizes across topics. Identify the outliers.
- Analyze consumer usage: Trace what each service actually extracts from messages.
- Implement Claim-Check: For messages over ~10KB, store payloads externally.
- Version your events: Use schema evolution to migrate consumers gradually.
- Set governance: Document max message sizes as architectural principles, not just configs.
The migration doesn’t have to be big bang. Start with your largest topic, implement Claim-Check for new message types, and migrate consumers incrementally. Your future self will thank you when you’re not debugging chunking logic in a legacy system at 2 AM.
The Bigger Picture: Local-First Efficiency
This Kafka anti-pattern is part of a broader trend: the assumption that bandwidth, storage, and memory are infinite. They’re not, and local-first, efficient system design as an alternative to bloated architectures is gaining traction precisely because it challenges this assumption.
In event-driven systems, “local-first” means keeping messages local to the services that need them, not broadcasting the universe to everyone. It’s about being selective, not greedy. The on-device, high-efficiency AI deployment patterns that run 66M-parameter models at 167x real-time on laptops share this philosophy: efficiency is a feature, not a constraint.
Final Thought: Listen to Your Infrastructure
Kafka’s message size limit is one of the few architectural guardrails that can’t be completely ignored. When you hit it, you have two choices: treat it as a configuration problem or treat it as design feedback.
Choose wisely. Your infrastructure is trying to tell you something important: you’re not building an event-driven system, you’re building a distributed monolith with extra steps.
The teams that thrive are the ones that listen.