Checkpointing: The Silent Killer of Distributed Systems
If your distributed system processes messages without checkpointing, you’re not building a resilient architecture, you’re building a time bomb. The moment a consumer crashes, rebalances, or hiccups, you’ll either reprocess hours of data or silently lose messages. Neither option looks good in a post-mortem.
Checkpointing is the boring, unsexy plumbing that separates toy event processors from production-grade systems. Yet most engineers treat it as an afterthought, slapping on a naive “store the offset” solution that crumbles under concurrent consumers, duplicate deliveries, or partial failures. The reality is far messier.
The Super Frog Problem: Why Checkpoints Exist
The event-driven.io article nails the analogy: old-school platform games like Super Frog gave players checkpoint codes after each level. Die at level 27? Punch in the code and resume exactly where you left off. No replaying from level 1.
Message processing needs the same mechanism. When a consumer dies mid-batch, you don’t want to reprocess the entire day’s events. You want to resume from the last safely processed position. But here’s where it gets spicy: “safely processed” doesn’t mean “last message handled.” It means “last message whose side effects were durably committed.”
Without checkpointing, you’re stuck with two terrible options:
- At-least-once delivery: Reprocess everything after a crash, hoping your handlers are idempotent (spoiler: they’re probably not)
- Cross your fingers: Start from the newest message and pray you didn’t miss anything business-critical
Neither scales. Both will wake you up at 3 AM.
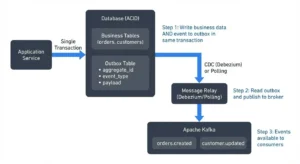
The PostgreSQL Outbox Pattern: Your Checkpointing Foundation
The research shows a robust pattern using PostgreSQL’s transactional guarantees. First, you need an outbox table that stores messages with global ordering:
CREATE TABLE outbox(
position BIGINT GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
transaction_id xid8 NOT NULL,
message_id TEXT NOT NULL,
message_type TEXT NOT NULL,
data JSONB NOT NULL,
scheduled TIMESTAMP WITH TIME ZONE NOT NULL default (now())
);
The key insight is storing both position and transaction_id. This gives you a global ordering guarantee even across concurrent transactions. When polling, you use this gnarly query:
SELECT
position, message_id, message_type, data
FROM
outbox
WHERE
(
(transaction_id = last_processed_transaction_id
AND position > last_processed_position)
OR
(transaction_id > last_processed_transaction_id)
)
AND transaction_id < pg_snapshot_xmin(pg_current_snapshot())
ORDER BY
transaction_id ASC,
position ASC
LIMIT 100;
This query ensures you never skip in-flight transactions and always process messages in the exact order they were written. It’s the foundation for deterministic recovery.
Storing Checkpoints: Not Just an Upsert
Now for the checkpoint table itself:
CREATE TABLE processor_checkpoints
(
processor_id TEXT PRIMARY KEY,
last_processed_position INTEGER NULL,
last_processed_transaction_id xid8 NOT NULL
);
Simple, right? Just update the position after each batch. Wrong.
The naive approach fails spectacularly when:
– Concurrent consumers compete for the same partition
– Duplicate deliveries happen due to network retries
– Partial failures leave your checkpoint inconsistent with your actual progress
You need atomic compare-and-swap semantics. The research provides a stored procedure that’ll make you question your life choices:
CREATE OR REPLACE FUNCTION store_processor_checkpoint(
p_processor_id TEXT,
p_position BIGINT,
p_expected_position BIGINT,
p_transaction_id xid8
) RETURNS INT AS $$
DECLARE
current_position BIGINT;
BEGIN
IF p_expected_position IS NOT NULL THEN
UPDATE processor_checkpoints
SET
last_processed_position = p_position,
last_processed_transaction_id = p_transaction_id
WHERE processor_id = p_processor_id AND last_processed_position = p_expected_position;
IF FOUND THEN
RETURN 1;
END IF;
SELECT last_processed_position INTO current_position
FROM processor_checkpoints
WHERE processor_id = p_processor_id;
IF current_position = p_position THEN
RETURN 0;
ELSIF current_position > p_expected_position THEN
RETURN 2;
ELSE
RETURN 3;
END IF;
END IF;
BEGIN
INSERT INTO processor_checkpoints (processor_id, last_processed_position, last_processed_transaction_id)
VALUES (p_processor_id, p_position, p_transaction_id);
RETURN 1;
EXCEPTION WHEN unique_violation THEN
SELECT last_processed_position INTO current_position
FROM processor_checkpoints
WHERE processor_id = p_processor_id;
IF current_position = p_position THEN
RETURN 0;
ELSIF current_position > p_expected_position THEN
RETURN 2;
ELSE
RETURN 3;
END IF;
END;
END;
$$ LANGUAGE plpgsql;
This beast returns different codes:
– 1: Success
– 0: Idempotent success (already at this position)
– 2: Conflict (another processor is ahead)
– 3: Mismatch (stale expected position)
The p_expected_position parameter is your compare-and-swap token. Pass the last checkpoint you read, and the procedure ensures atomic progression.
Batch Processing: Where Theory Meets Production
Here’s the TypeScript implementation that ties it together:
async function handleBatch(
messageBatch: RecordedMessage[],
context: ProcessorContext
): Promise<BatchHandlingResult> {
const checkpoint = messageBatch[messageBatch.length - 1].metadata.checkpoint;
return context.pool.withTransaction(async (transaction) => {
// Process all messages first
for (const message of messageBatch) {
await context.onMessage(message),
}
// Attempt to advance checkpoint
const result = await storeProcessorCheckpoint(transaction.execute, {
processorId: context.processorId,
newCheckpoint: checkpoint,
lastProcessedCheckpoint: context.lastProcessedCheckpoint,
});
if(result.success) {
await transaction.commit();
} else {
await transaction.rollback();
}
return result;
});
}
The critical pattern: process first, checkpoint last, within the same transaction as your side effects. If the checkpoint store fails, your entire transaction rolls back. No partial commits, no data loss, no inconsistency.
You can optimize by checking the checkpoint before processing, but the core principle remains: your checkpoint advancement must be atomic with your business logic’s persistence.
Azure Event Hubs: Cloud-Native Checkpointing
Not everyone runs PostgreSQL. Azure Event Hubs provides managed checkpointing via Azure Blob Storage:
checkpoint_store = BlobCheckpointStore.from_connection_string(
conn_str=STORAGE_CONNECTION_STR,
container_name=CHECKPOINT_CONTAINER
)
client = EventHubConsumerClient.from_connection_string(
conn_str=EVENTHUB_CONNECTION_STR,
consumer_group=CONSUMER_GROUP,
checkpoint_store=checkpoint_store
)
async def on_event(partition_context, event):
# Process event...
await partition_context.update_checkpoint(event)

The SDK handles checkpoint storage automatically, but the semantics are identical: after processing, persist the offset. The key difference is partition ownership. Event Hubs uses consumer groups where each partition is owned by exactly one consumer at a time.
The research shows a flawed manual assignment approach versus the correct auto-load-balanced version:
# WRONG: Manual partition assignment
# If Consumer-A dies, Partition-0 stops processing
# RIGHT: Let Event Hubs manage partition ownership
client.receive(
on_event=on_event,
on_partition_initialize=on_partition_initialize,
on_partition_close=on_partition_close,
on_error=on_error
)
The auto-balanced consumer receives lifecycle callbacks when partitions are claimed or released. This is essential for clean shutdowns and rebalancing.
The Tradeoffs: When Checkpointing Works (And When It Doesn’t)
1. Requires Global Ordering
This pattern only works if your message source provides a global order. PostgreSQL outbox, Kafka, Event Store DB? Yes. RabbitMQ, SQS, Google Pub/Sub? No. Without global ordering, you can’t detect gaps or guarantee idempotency at the checkpoint level.
2. Transactional Storage
The beauty of the PostgreSQL approach is that checkpoint storage lives in the same database as your business data, enabling atomic commits. If you’re writing to S3, calling external APIs, or using a separate database, you lose atomicity. Hello, dual-writes problem.
3. Long-Running Transactions
Batching improves throughput but risks long-lived transactions. In PostgreSQL, this can block vacuuming and bloat your database. The transaction ID logic in the outbox query helps, but it’s not magic. Keep batches small or use logical replication.
4. At-Least-Once Is Inevitable
Even with perfect checkpointing, failures between processing and checkpointing guarantee at-least-once delivery. The research suggests a “two-step verification” using Redis or a database for idempotency keys. This adds complexity but prevents duplicate processing when checkpointing fails.
The Controversial Take: Checkpointing Is Not Enough
Here’s where I deviate from the happy path. Most articles stop at “implement checkpointing and you’re safe.” Wrong.
Checkpointing only solves consumer recovery. It doesn’t solve:
- Producer idempotency: Did that event get published exactly once?
- End-to-end exactly-once semantics: Requires transactional producers and consumers
- Clock skew: In distributed systems, “last processed” is ambiguous
- Byzantine failures: What if your checkpoint store lies?
The Azure Event Hubs article admits this: “EventHub guarantees processing of all events, but does not guarantee only one-time processing.” The solution? A second layer of idempotency in your business logic. Checkpointing gets you 80% of the way, but that last 20% will murder your SLAs.
Production Checklist: Don’t Skip These
- Monitor checkpoint lag: Alert if consumer position falls behind production by >X seconds
- Test partition rebalancing: Kill consumers during load tests. Does recovery work?
- Validate idempotency: Run duplicate batches intentionally. Do your handlers survive?
- Measure transaction duration: Keep p99 under 1 second or face operational pain
- Version your checkpoints: Schema migrations will happen. Plan for it.
Final Word: Use the Damn Library
The event-driven.io article ends with a plea: “I hope that’s not something that you’d like to maintain on your own. There are mature tools to deal with such stuff, like Emmett.”
This isn’t laziness, it’s wisdom. Hand-rolling checkpointing logic is a rite of passage, but maintaining it across 50 microservices is a career-limiting decision. Use Emmett, use Kafka Streams, use Azure Event Hubs SDK. They’ve already solved the edge cases you haven’t thought of yet.
Checkpointing is the silent killer because it works until it doesn’t. And when it fails, it fails catastrophically. Don’t be the engineer explaining to the CEO why the system reprocessed six months of financial transactions. Implement it correctly, monitor it obsessively, and delegate to battle-tested libraries whenever possible.
Your future self, debugging at 2 AM, will thank you.