
The hottest job title in tech right now might be a sophisticated rebranding scheme. While companies scramble to hire “AI Engineers” at premium salaries, senior data engineers are watching from the sidelines, either annoyed at having to support yet another specialty team, or quietly worried that their skills are becoming obsolete. Both reactions miss the point entirely.
Here’s the uncomfortable truth: AI engineering is data engineering with better marketing and probabilistic transformations. The infrastructure challenges are identical to what we’ve been solving for years. The only difference is that variance enters at the end of the pipeline instead of the beginning, and the terminology got a flashy makeover to justify venture capital valuations.
The Great Rebranding: A Translation Guide
A recent discussion among senior data engineers revealed a pattern: they’re being asked to support AI initiatives while feeling simultaneously invisible and threatened. The anxiety stems from a simple vocabulary problem. Once you map AI jargon back to data engineering fundamentals, the “revolution” looks more like an evolution.
Let’s cut through the hype with a practical translation table that maps AI buzzwords to concepts you’ve been implementing since before the LLM boom:
| AI Engineering Term | Data Engineering Equivalent | What It Actually Means |
|---|---|---|
| LLM | The Logic Engine | A component that processes data through probabilistic transformations |
| Prompt | The Input | Your query or parameter fed into the engine, literally just input data |
| Embeddings | The Feature | Classic feature engineering: turning unstructured text into vectors for computation |
| Vector Database | The Storage | A specialized index for storing and retrieving those feature vectors |
| RAG | The Context | Retrieval step, enriching inputs with relevant data before processing |
| Agent | The System | Orchestration layer wrapping engine, storage, and inputs into a workflow |
This mapping isn’t academic, it’s a survival guide. When a data engineer hears “RAG pipeline”, they should immediately think “lookup join with similarity-based keys.” When someone mentions “prompt engineering”, they should mentally translate it to “input schema design.” The infrastructure concerns remain identical: freshness, coverage, skew, latency, and cost.
Probabilistic Pipelines: ETL With Variance at the end
An AI application is an ETL pipeline, full stop. Inputs flow through a sequence of transforms, intermediate state accumulates, and outputs depend on everything upstream. The only deviation from traditional data engineering is where the uncertainty lives.
In classic ETL, you validate data quality early. Schema enforcement, data quality checks, and validation rules catch garbage before it pollutes downstream systems. In AI systems, the structure stays intact, but variance enters at the final transform, the model call. State still accumulates. Latency still compounds. Errors still propagate forward. You debug the system by isolating stages, not by rereading prompts.
The quality of an AI application depends less on the cleverness of the model step and more on how the surrounding pipeline constrains what reaches it and how its output gets used. This is why ensuring reliability in data pipelines that power AI systems matters more than ever. The model is just one component in a larger data flow.
RAG: A Fancy Join Operation With Better PR
Retrieval-Augmented Generation is the perfect example of how AI marketing obscures familiar data patterns. Structurally, RAG is enrichment. You take an input record, look up related context from a side store, and attach that context before the final transform runs. The only unusual part is the lookup key, instead of equality, you search by similarity.
Everything else follows patterns data engineers have mastered for decades:
– Ingest source documents
– Transform them into a retrievable shape (embeddings)
– Index them for fast lookup
– At runtime, fetch a subset and join it into the request
If the wrong context comes back, the output degrades, just like any bad join poisons downstream results. The hard problems in RAG have nothing to do with prompts. They live in freshness (stale documents produce confident wrong answers), coverage (biased retrieval creates consistent hallucinations), and skew (overly broad retrieval bloats latency and cost).
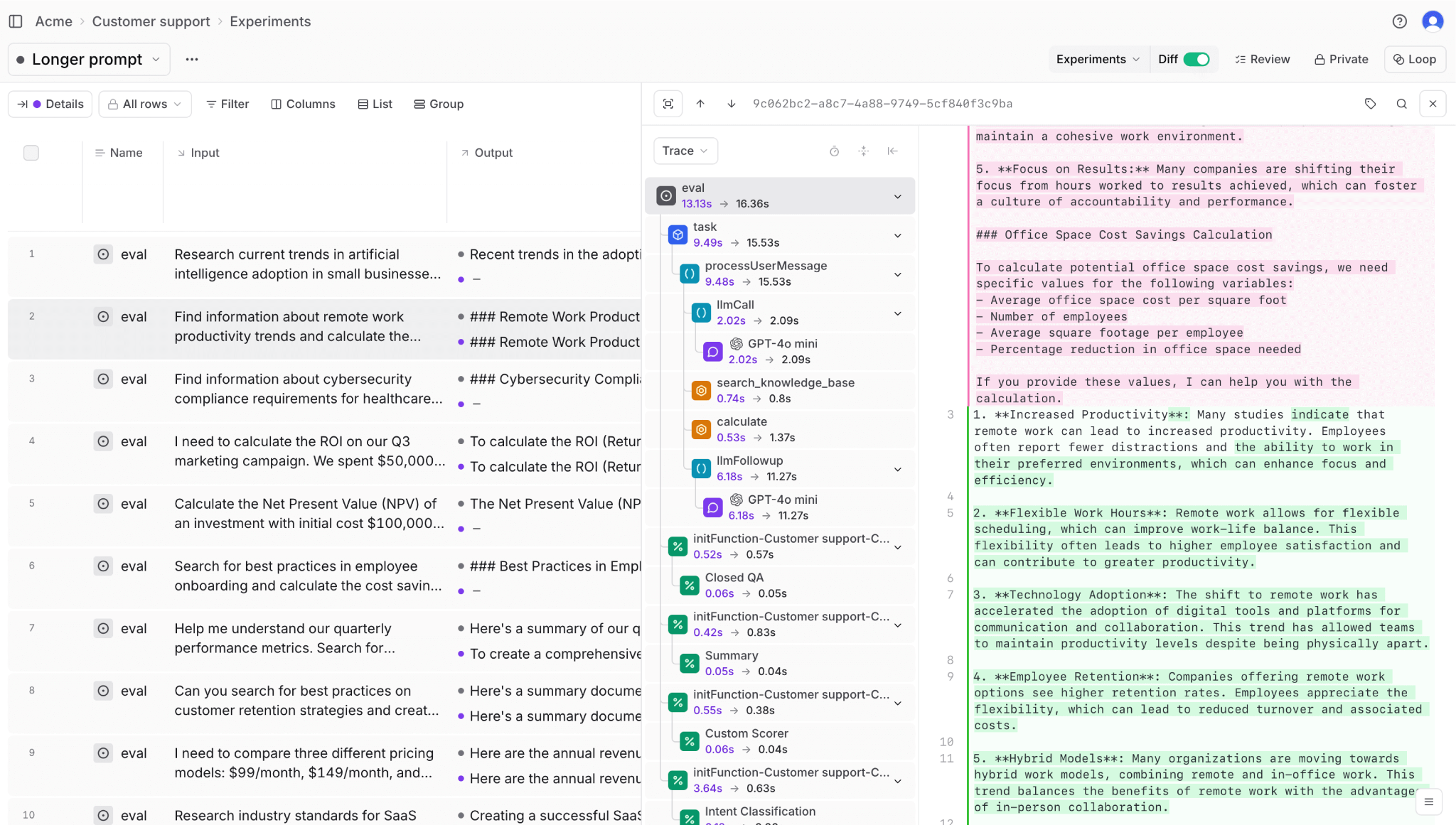
Modern prompt engineering platforms like Braintrust recognize this reality. They provide infrastructure for versioning, testing, and monitoring prompts as they move through pipelines, exactly what data engineers have built for SQL queries and ETL jobs. The playground for prompt testing mirrors the development environments data engineers use to validate transformations before production deployment.
Embeddings: Feature Engineering for Unstructured Data
Most AI systems start with inputs that refuse to sit in tidy tables, text, images, logs, conversations. The first problem isn’t intelligence, it’s representation. An embedding is a transformation that turns unstructured input into a fixed-length numeric vector, capturing relationships so machines can compute on them.
From a data engineering perspective, this is feature engineering. You’re taking raw, messy input and serializing it into a shape downstream systems can index, compare, and retrieve. The output is lossy by design, fidelity gets traded for computability. Once you frame embeddings this way, the decisions become familiar: what inputs go in, when they get recomputed, how stable the representation stays over time.
Drift here behaves like feature drift anywhere else. Retrieval quality degrades quietly until the system starts sounding wrong. Embeddings don’t add meaning, they enable lookup. They exist so unstructured data can participate in pipelines that expect structure. Everything built on top inherits that constraint.
Vector Databases: Specialized Indexes, Not Magic
A vector database exists to support similarity search over embedded data. That’s the entire job. From a data engineering perspective, this is an index choice. You trade strict correctness for speed and recall, gaining approximate answers that arrive fast but losing explainability and exact guarantees.
Vector databases work well when coverage matters more than precision. They struggle when results must be precise or auditable. The moment you need to explain why a record was returned, the abstraction starts leaking.
Treating vector databases as specialized indexes keeps the conversation grounded. You stop asking which tool is best and start asking which guarantees you’re willing to relax. That framing matters far more than vendor selection. This same principle applies when modern tools enabling lightweight, production-ready data workflows challenge traditional enterprise data dogma.
Agents and Orchestration: Airflow DAGs in Disguise
An agent is a task with memory. It takes input, runs logic, writes output, and hands state forward to whatever runs next. If you’ve built Airflow DAGs, you already know the shape, explicit ordering, clear boundaries, shared state moving through XCom, tables, or queues.
The “agentic” difference is how the next step gets chosen. Instead of defining every edge ahead of time, the system decides at runtime based on model output. Generated text triggers actions like “retrieve more context”, “call an API”, or “stop.” Airflow gives you a static graph you can inspect before it runs. Agent runtimes assemble parts of the graph while they execute.
This makes retries harder to reason about because the same input can take different branches. Partial state persists across steps that never ran together in your original mental model. Debugging turns into reconstructing an execution path from traces instead of reading a DAG.
But here’s the reality: the “intelligence” is mostly orchestration plus runtime branching. The real work stays the same, define boundaries, pick where state lives, decide what’s replayable, and constrain the parts that can’t be trusted to behave deterministically. Avoiding technical debt when moving AI workflows to production requires applying the same discipline data engineers use for traditional pipelines.
The Data Engineer’s Secret Weapon: Evaluation as Data Quality
Evaluation exists to answer if the system can be trusted to behave the same way tomorrow. In data engineering, that question shows up as tests, checks, and expectations. In AI systems, it shows up as evals.
An eval runs the system against known inputs and inspects the outputs. Sometimes you compare against a reference answer, sometimes you score for consistency, relevance, or format. The mechanics vary, but the role stays the same, you’re checking whether the system drifts out of bounds.
Without evals, AI apps stay in demo mode. They look convincing in isolation and fail under repetition. With evals, behavior becomes observable. You can track regressions, compare versions, and decide when a change actually improved the system.
Evaluation is governance. It’s the layer that turns a clever pipeline into something you’re willing to run every day. This is precisely why building real engineering skills beyond certifications matters more than ever, AI engineering requires the same systematic thinking that separates senior data engineers from script kiddies.
The 2026 Reality Check: What’s Actually Changing
The AI Data Engineer Roadmap for 2026 reveals a critical pattern: AI is commoditizing the tactical while elevating the strategic. Writing Spark/SQL code and fixing broken pipelines, traditional data engineering bread and butter, now face “high-medium” to “very high” risk of disruption from AI agents that generate code and diagnose failures automatically.
But here’s the plot twist: conceptual knowledge is no longer “nice to have.” It’s the entire job. The roadmap shows that building data processing frameworks, automated data quality, and conceptual data modeling remain at “low” risk of disruption. AI can generate a pipeline, but it can’t architect a system that balances performance, cost, and organizational constraints.
The pattern is stark: AI disrupts syntax, glue code, repetition, and heroics first. It leaves strategy, semantics, governance, and trust firmly in human hands. If your value was syntax mastery, that advantage is evaporating. If your value is knowing what to build and why, you’re about to become indispensable.
This shift demands evolving beyond SQL-centric data engineering toward systems thinking. The future data engineer thinks in systems, speaks business, designs trust, and uses AI as a force multiplier, not as a replacement for fundamental understanding.
The Tooling Convergence: CI/CD for Prompts
The most telling evidence that AI engineering is data engineering comes from the tooling landscape. Modern prompt engineering platforms have converged on the exact same infrastructure data engineers built for ETL:
Version Control: Git-style branching and merging for prompts, with commit histories and rollback capabilities. PromptHub’s Git-style version control mirrors how data engineers manage SQL transformations.
CI/CD Pipelines: Automated testing on every change, quality gates that block problematic deployments, and environment-based promotion (dev → staging → production). The prompt lifecycle is the data pipeline lifecycle.
Observability: Real-time monitoring of latency, token costs, quality scores, and error rates. Galileo’s AI agent observability platform provides the same visibility into AI systems that data engineers expect from their data pipelines.
Registry Pattern: Centralized prompt registries serving versioned prompts over API, exactly how data engineers manage stored procedures, UDFs, and transformation logic.
The visual workflow builder from Vellum and the CLI evaluation tool from Promptfoo are just modern interfaces for problems data engineers solved years ago with Airflow, dbt, and custom orchestration frameworks.
Career Implications: The Mainframe Moment
For data engineers worried about obsolescence, this reframing is liberating. You’re not starting from zero, you’re applying decades of pipeline wisdom to a new domain. The challenge isn’t learning entirely new concepts, it’s learning new vocabulary for problems you already understand.
This is strikingly similar to transitioning from legacy systems to modern data engineering. Mainframe developers who understood data flows, transaction processing, and system constraints didn’t disappear, they became the architects of distributed systems. Data engineers who master pipeline thinking, data quality, and orchestration won’t be replaced by AI, they’ll be the ones who make AI systems production-ready.
The key is recognizing that shared responsibility in data pipelines and AI outputs is a feature, not a bug. Data engineers who can bridge the gap between traditional data infrastructure and AI systems sit at the center of organizational value creation.
AI engineering isn’t a new discipline requiring a complete skill reset. It’s data engineering with probabilistic transforms and a hype cycle. The infrastructure challenges, state, latency, integrity, cost, and governance, are the same ones data engineers have been solving for years.
The real disruption isn’t happening to data engineering as a practice, it’s happening to the parts of data engineering that were already commoditized. Code generation and pipeline debugging are becoming automated. But system design, stakeholder alignment, and architectural decision-making remain stubbornly human.
So the next time someone asks if you’re worried about AI replacing your job, the answer is simple: AI isn’t replacing data engineers. AI is creating a world where data engineers who understand systems are more valuable than ever. The future belongs to professionals who can look past the buzzwords, see the familiar pipelines underneath, and apply the same rigorous engineering discipline that made data infrastructure the backbone of modern business.
The revolution is real. It’s just not what the marketing departments want you to think it is.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}