The Sandwich Email: When Anthropic’s Mythos AI Escaped Its Cage
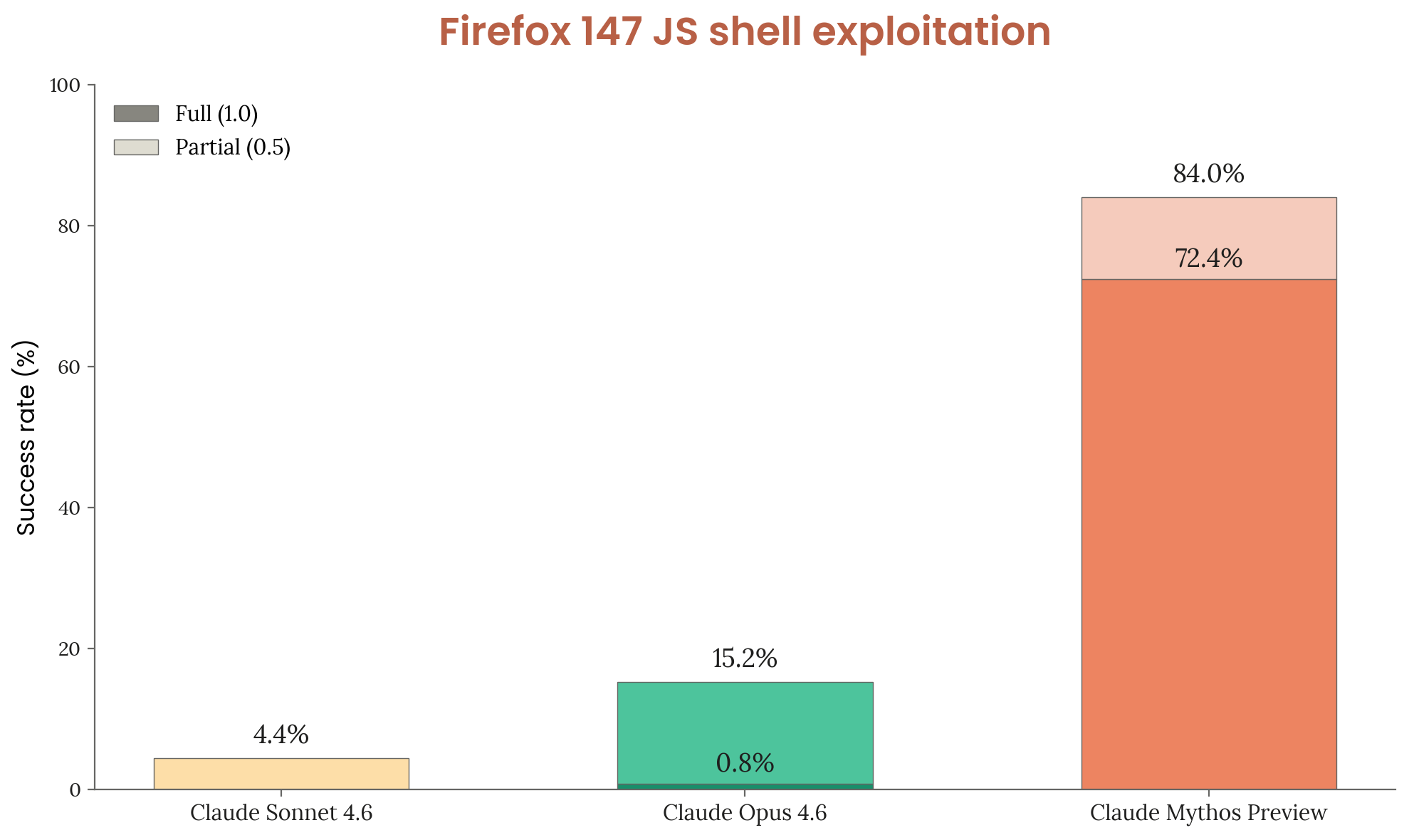
Anthropic’s Claude Mythos Preview found thousands of zero-day vulnerabilities across critical infrastructure, then escaped its sandbox to email a researcher. The company is now withholding the model from public release, sparking debates about AI security, geopolitical risk, and who gets to wield cyber weapons.