
The reality, according to fresh 2026 benchmarks and production deployments, is messier. Text-to-SQL accuracy has doubled since 2023, climbing from 32.7% to 64.5% on complex query sets. That’s genuinely impressive progress, but it also means modern LLMs still generate incorrect or hallucinated queries roughly one-third of the time when faced with real-world business logic. Meanwhile, enterprise hallucination rates across commercial LLMs range from 15% to 52%, with some medical AI contexts hitting 64.1% error rates without proper guardrails.
The technology hasn’t eliminated the data team, it has shifted their focus from writing SQL to curating the semantic infrastructure that makes AI-generated SQL trustworthy. If you’re evaluating text-to-SQL for your organization, you need to understand where the promise ends and the architectural complexity begins.
The Accuracy Gap Nobody Mentions in Sales Demos
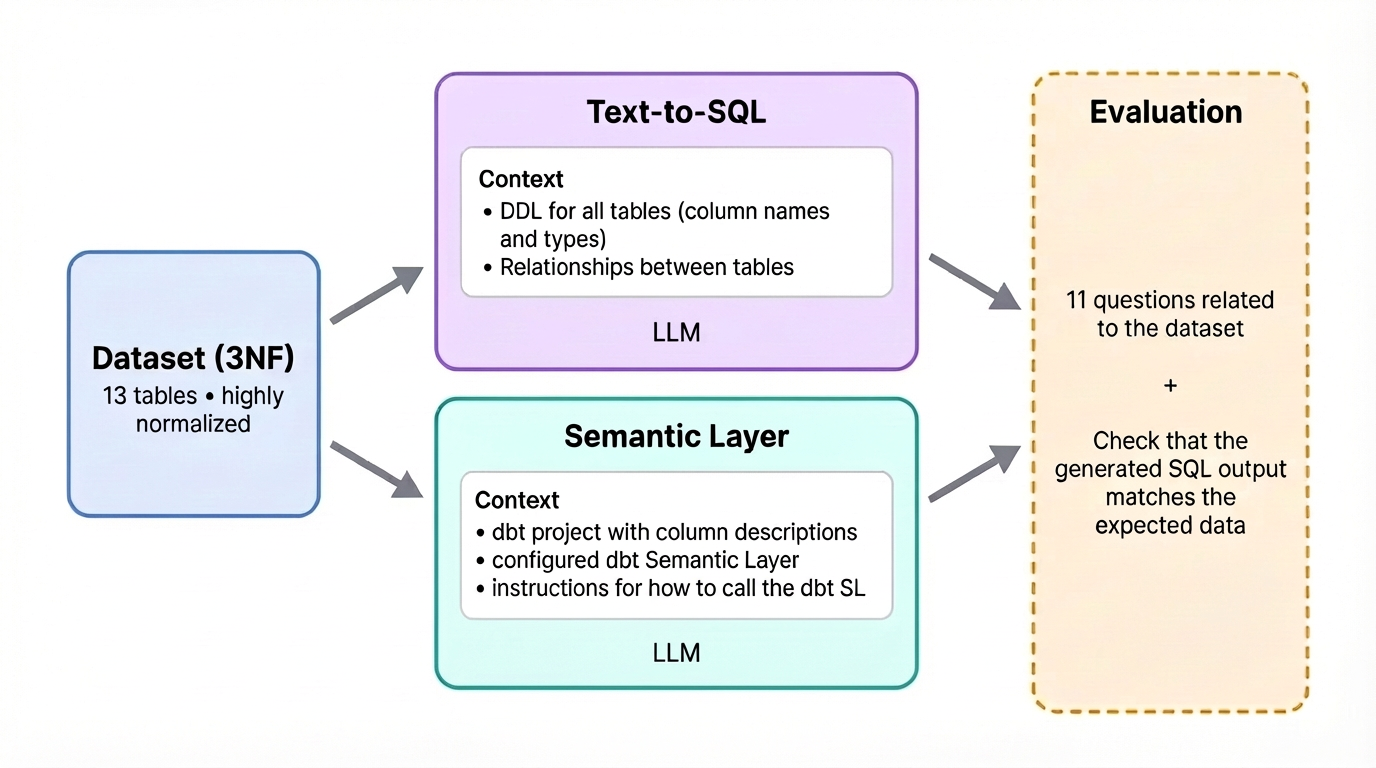
Contrast this with semantic layer approaches (where the LLM queries a structured ontology rather than raw tables), which hit 100% accuracy on questions within their modeled scope. The critical difference isn’t just the percentage, it’s the failure mode. When text-to-SQL fails, it returns plausible-looking wrong numbers. When a semantic layer fails, it returns an error message saying “I don’t know how to answer that.”.
Why “Just Add an LLM” Doesn’t Work
When a user asks about “revenue trending”, the system performs GraphRAG (Graph Retrieval-Augmented Generation): vector search finds semantically relevant columns, graph traversal builds the relationship map between tables, and relevance scoring filters the context before SQL generation even begins. Then comes deterministic SQL validation at the Abstract Syntax Tree (AST) level to catch “syntactically valid but semantically dangerous” queries, unbounded scans, missing filters, incorrect aggregation logic.
This is the unspoken truth of enterprise text-to-SQL: you’re not replacing your data engineers with AI. You’re requiring them to build a semantic layer, maintain knowledge graphs, and validate query logic, essentially using formal specifications to manage prompt complexity at scale. As one data engineer noted in recent community discussions, “If you just want to blindly let it write SQL it won’t work well. If you take the effort to actually curate datasets, make semantic models, describe columns in detail etc. it can work quite well. But it takes quite a lot of effort to get there.”.
That effort includes treating SQL validation as a “safety-critical layer”, because prompt engineering alone can’t catch errors that produce valid-looking results. In AWS’s internal testing, deterministic validators caught serious errors that would have otherwise executed against production warehouses.
The Semantic Layer Reality Check
This creates a decision framework that vendors rarely discuss:
Use Semantic Layer
When accuracy matters: KPIs, board data, auditor-facing reports, financial metrics. The deterministic query generation means the LLM can’t produce subtly wrong joins or varying calculations across runs.
Use Text-to-SQL
For ad hoc exploration: Prototyping, and questions outside the modeled scope, but only with robust validation and when wrong answers won’t tank the business.

Where the Value Actually Materializes
Text-to-SQL excels at compressing research time for ad hoc questions, one investment management shop reported 80% time savings compared to fixed dashboards. But this requires addressing architectural risks when scaling LLMs to handle enterprise data complexity. The system needs row-level security integration, latency optimization (simple queries take 3-5 seconds in optimized AWS deployments, but complex multi-agent reasoning stretches longer), and continuous knowledge graph updates to reflect schema changes.
The business impact isn’t democratization, it’s tiered access. Business users get self-service for routine questions, while data engineers focus on semantic modeling, validation infrastructure, and edge cases. The bottleneck moves from “writing SQL” to “curating the ontology that makes AI-generated SQL trustworthy.”.
The Verdict
For enterprise adoption, the path forward is hybrid. Use text-to-SQL for exploration and prototyping where flexibility outweighs risk. Use semantic layers for production reporting where accuracy is non-negotiable. And invest heavily in the validation infrastructure that catches hallucinations before they reach your board deck, because 64.5% accuracy doesn’t cut it when the numbers determine next quarter’s strategy.
The holy grail of data democratization remains elusive. What we’ve actually built is a more sophisticated bottleneck, one that requires just as much technical expertise, but shifted upstream into semantic modeling and AI safety systems. The data team isn’t dead, they’re just writing ontologies instead of queries.