

Your LLM is going to lie to you. Not occasionally. Not as a rare edge case. It will fabricate statistics, invent API parameters, and confirm successful operations that never happened, all with the confident tone of a poker player bluffing with a pair of twos.
The sooner you accept that large language models are fundamentally forgery engines, sophisticated imitation machines optimized for plausibility over truth, the sooner you can stop building brittle AI integrations and start architecting systems that treat hallucinations as a feature of the terrain, not a bug to be patched.
The Inevitability of Confabulation
Recent research from OpenAI and Georgia Tech establishes what many practitioners already suspect: hallucinations aren’t an implementation flaw but a mathematical certainty. The analysis shows that LLMs hallucinate because their training objectives explicitly reward guessing over admitting uncertainty. When faced with a prompt like “What is Adam Tauman Kalai’s birthday?” and instructed to respond only if known, state-of-the-art models will confidently output “03-07”, “15-06”, or “01-01”, all wrong, rather than the safer “I don’t know.”.
This isn’t a failure of scale or data quality. It’s structural. The comprehensive survey on LLM hallucinations categorizes these failures across the entire development pipeline, from data curation (outdated knowledge, long-tail entities) to architecture (softmax bottlenecks, exposure bias) to inference (sampling randomness). The taxonomy distinguishes between intrinsic hallucinations (contradicting the source) and extrinsic hallucinations (unverifiable fabrications), but both stem from the same root: these models are autocomplete systems on steroids, not knowledge bases with provenance.
When agents execute tasks rather than just chat, the stakes escalate dramatically. A chatbot giving incorrect trivia is annoying, an agent hallucinating API parameters or confirming phantom database writes is catastrophic. The research identifies five specific failure modes in agent tool-calling: function selection errors, appropriateness errors, parameter errors, completeness errors, and tool bypass behavior (where the agent generates outputs instead of calling validation tools).
From Prompt Engineering to Architectural Defense
The industry has spent too long trying to prompt-engineer its way out of fundamental uncertainty. “Be careful” and “double-check your work” are suggestions, not constraints. Real resilience requires moving guardrails from the prompt layer to the architecture layer.
Graph-RAG: Structure Over Similarity
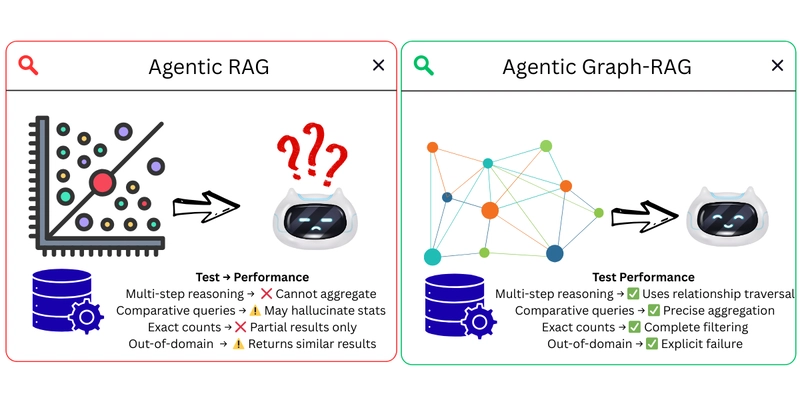
Traditional Retrieval-Augmented Generation (RAG) is a statistical Band-Aid. It retrieves text chunks based on vector similarity, then asks the LLM to synthesize an answer. The problem? Vector search retrieves similar documents, not relevant data, and certainly not structured facts that can be computed upon.
When asked to count swimming pools across 300 hotel documents, a standard RAG system fails because it’s averaging text chunks rather than querying a database. Graph-RAG, by contrast, uses knowledge graphs with explicit entity relationships. Instead of retrieving “similar” documents, the LLM writes Cypher queries against a structured graph:
# Graph-RAG executes precise calculations
MATCH (h:Hotel)-[:OFFERS_AMENITY]->(a:Amenity {name: 'Pool'})
RETURN count(h) # Returns exactly 133, not "approximately 8.7"
The knowledge graph provides verifiable structure, aggregations are computed by the database, relationships are explicit, and missing data returns empty results rather than fabrications. This isn’t just better RAG, it’s a fundamentally different trust model where the LLM is a query generator, not a fact arbiter.
Semantic Tool Selection: Reducing Choice Overload
One underappreciated source of agent failure is simply having too many tools. Research on internal representations in agent tool selection shows that hallucinations increase with tool count due to “choice overload” in the context window.
When an agent has access to 31 similar tools, traditional implementations send all descriptions to the LLM on every call (~4,500 tokens), creating a buffet of confusion where the model regularly selects inappropriate functions or hallucinates parameters.
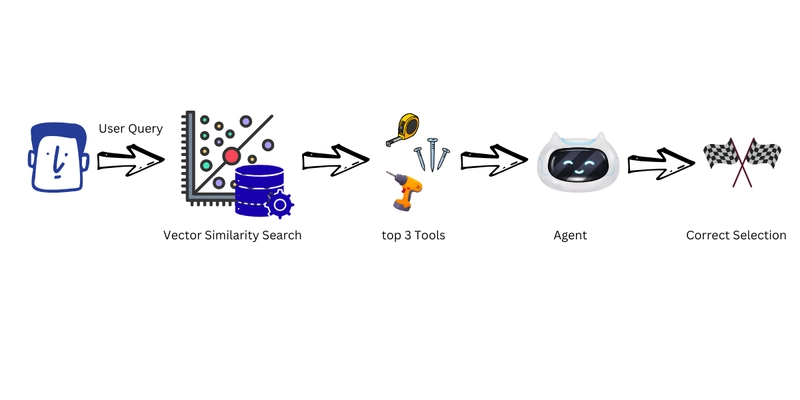
Semantic tool selection filters tools before the agent sees them using vector similarity against the user query. In testing on 29 travel queries, filtering 31 tools down to 3 relevant candidates reduced errors by 86.4% and cut token costs by 89%. The implementation is straightforward:
from sentence_transformers import SentenceTransformer
import faiss
# Build index once
model = SentenceTransformer('all-MiniLM-L6-v2')
tool_embeddings = model.encode([tool.description for tool in ALL_TOOLS])
index = faiss.IndexFlatL2(384)
index.add(tool_embeddings)
# Filter per query
query_embedding = model.encode([query])
distances, indices = index.search(query_embedding, k=3)
relevant_tools = [ALL_TOOLS[i] for i in indices[0]]
This pattern, pre-filtering context rather than overwhelming the LLM, extends beyond tools to any large API surface or documentation set.
Neurosymbolic Guardrails: Hard Constraints for Soft Models
Prompts are suggestions. Code is law. The most effective hallucination mitigation strategies combine neural flexibility with symbolic rigidity.
Neurosymbolic guardrails intercept tool calls at the framework level before execution. Using hooks in frameworks like Strands Agents, you can enforce business rules that the LLM cannot bypass:
from strands import Agent, tool
from strands.hooks import HookProvider, HookRegistry, BeforeToolCallEvent
# Define symbolic rules
BOOKING_RULES = [
Rule(
name="max_guests",
condition=lambda ctx: ctx.get("guests", 1) <= 10,
message="Maximum 10 guests per booking"
),
]
class NeurosymbolicHook(HookProvider):
def validate(self, event: BeforeToolCallEvent) -> None:
ctx = {"guests": event.tool_use["input"].get("guests", 1)}
passed, violations = validate(BOOKING_RULES, ctx)
if not passed:
event.cancel_tool = f"BLOCKED: {', '.join(violations)}"
# The LLM cannot override this cancellation
agent = Agent(tools=[book_hotel], hooks=[NeurosymbolicHook()])
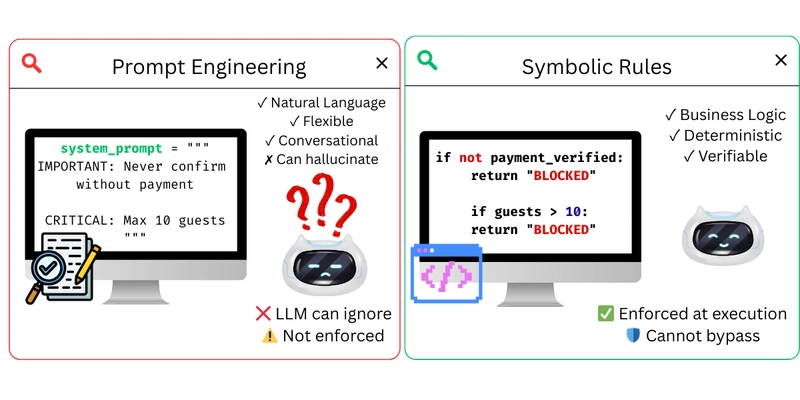
This approach recognizes that LLMs are terrible at arithmetic, boundary checking, and logical consistency, exactly the things symbolic systems excel at. By validating parameters before execution, you prevent the agent from booking 15 guests when the limit is 10, regardless of how confidently it asserts the booking succeeded.
Multi-Agent Validation: Cross-Examination as Architecture
Single agents hallucinate without detection because there’s no mechanism to catch errors before they reach users. Multi-agent architectures use specialized agents to validate each other through structured debate.
The pattern is simple but effective: an Executor agent performs the task, then hands off to a Validator agent that checks for hallucinations, followed by a Critic agent that provides final approval. Research shows this cross-validation catches errors that single agents miss, particularly in claiming success when operations actually failed.
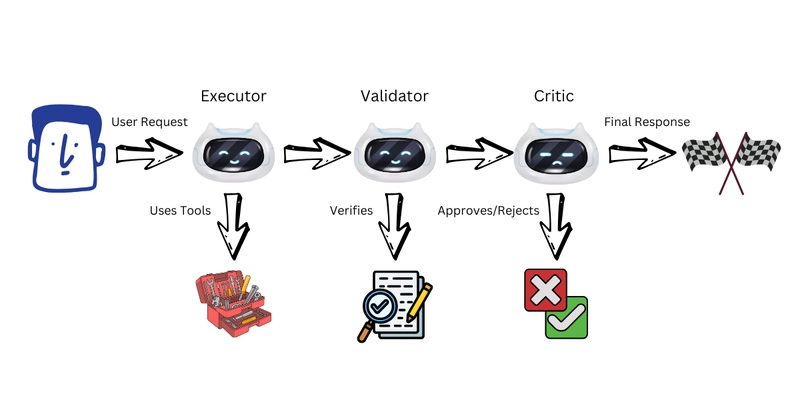
The key insight isn’t just having multiple agents, it’s ensuring they have different objectives. When the Validator is explicitly tasked with finding hallucinations (and rewarded for catching them), you create an adversarial dynamic that surfaces errors before they propagate to users.
The Evaluation Trap: Why Benchmarks Reward Lying
Perhaps the most insidious reinforcement of hallucinations comes from how we evaluate models. Analysis of major benchmarks reveals that binary grading (correct/incorrect) explicitly penalizes uncertainty. Under standard 0-1 scoring, a model that says “I don’t know” gets zero points, while a confident guess that happens to be correct gets full credit.
This creates an “epidemic of penalizing uncertain responses” where models are optimized to be good test-takers rather than honest reporters. When assessing structural weaknesses in AI applications, we often find that the system is behaving exactly as the training incentives dictated: maximizing accuracy by never admitting ignorance.
The fix isn’t more hallucination-specific evaluations, it’s modifying existing benchmarks to include explicit confidence targets. By appending instructions like “Answer only if you are >75% confident, since mistakes are penalized 3 points while correct answers receive 1”, you align the optimization target with truthfulness rather than bluffing.
Designing for Failure Modes
Resilient AI architecture requires accepting that your components will fail in specific, predictable ways. When handling failures in concurrent calls to external services, we don’t assume the network is reliable, we implement circuit breakers and fallback strategies. LLMs deserve the same skepticism.
- Ground Truth Verification: For data-driven tasks, never trust the LLM’s aggregation. Use Graph-RAG to generate database queries, then verify results against actual data.
- Semantic Pre-filtering: Reduce context noise by embedding-based filtering before the LLM sees any input.
- Symbolic Validation: Enforce business rules at the framework level, not the prompt level.
- Adversarial Validation: Use secondary agents to challenge primary agent outputs before user delivery.
- Explicit Uncertainty: Design UIs that surface confidence scores and allow users to request human review for low-certainty operations.
When debugging unexpected behavior in distributed workflows, the hardest bugs are those where components technically “succeeded” but produced nonsense. LLM integrations are particularly prone to this, an agent might return a 200 OK status with entirely fabricated data.
Conclusion: The Post-Hallucination Architecture
The next generation of AI systems won’t be distinguished by how few hallucinations they produce, but by how gracefully they handle the inevitable ones. Like maintaining consistency during component outages, resilience in LLM systems requires designing for the failure mode as a first-class concern.
The “L” in LLM might stand for lying, but in system architecture, it should stand for layered, layers of verification, layers of constraints, and layers of fallbacks that ensure when your model inevitably confabulates, the fabrication never reaches your database, your customers, or your production environment.
Stop trying to fix the LLM. Start architecting around it.



