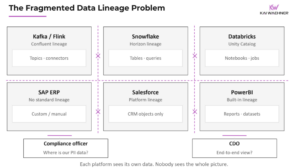
The “works on my machine” problem has evolved. It used to mean your Python script threw an ImportError because you forgot to pin pandas. Now it means your entire Airflow DAG runs perfectly in staging but collapses in production because someone’s R script depends on a system library that exists on the data scientist’s MacBook but not your Alpine container. Apache Airflow’s growing ecosystem complexity and discoverability challenges have turned pipeline maintenance into archaeology, digging through layers of provider packages to figure out why yesterday’s successful run became today’s silent failure.

We’ve tried Docker. We’ve tried uv, renv, poetry, and Conda. Yet dependency drift still accumulates like plaque in an artery, silently, until the heart attack. A new experimental language called T (or tlang) proposes something more radical: what if reproducibility wasn’t opt-in, but mandatory by design? What if you literally couldn’t run a script without wrapping it in a reproducible pipeline block, sandboxed by Nix, with data flowing between R and Python via Apache Arrow IPC?
The proposal is equal parts compelling and confrontational. It asks data engineers to abandon mutable state, embrace functional programming constraints, and learn Nix, a tool with a learning curve steeper than the price of NVIDIA stock. But it might be the only honest solution to polyglot dependency drift.
The Reproducibility Mirage
Current orchestration tools operate on a fiction: that you can achieve reproducibility by being careful. Airflow lets you define Python callables. Docker lets you freeze filesystems. But as one developer noted in discussions around the tool, Docker solves the packaging problem, not the declaration problem, you can freeze a broken environment just as easily as a working one.
“Docker solves the packaging problem, not the declaration problem.”
A key insight from the Datascience community regarding environment management.
The issue is composability. R’s {renv} and Python’s requirements.txt don’t talk to each other. They certainly don’t know about your system-level libgfortran or the specific glibc version your Python wheel was compiled against. Six months later, when you try to reproduce that critical model training run, you’re hunting through GitHub issues trying to figure out which transitive dependency introduced a breaking change.
Industry debates over whether traditional tools like Airflow remain viable often miss this point. It’s not that Airflow can’t schedule tasks, it’s that it can’t guarantee the environment those tasks run in remains coherent across time and machines.
Enter T: The Functional Straightjacket
T’s thesis is brutally simple: reproducibility is mandatory. You cannot run a T script without wrapping it in a pipeline {} block. Every node in that pipeline runs in its own Nix sandbox, built from a deterministic flake. The language itself is strictly functional, no loops, no mutable state, immutable by default. If you want to reassign a variable, you must explicitly use := or rm() the old one first.
This isn’t just pedantic functional programming. It’s architectural enforcement. Consider a typical polyglot pipeline where R handles statistics, Python handles ML, and Bash generates reports. In T, this looks like:
p = pipeline {
-- Native T node loads data
data = node(command = read_csv("data.csv") |> filter($age > 25))
-- rn() defines an R node, pyn() defines Python
model_r = rn(
command = <{ lm(score ~ age, data = data) }>,
serializer = ^pmml,
deserializer = ^csv
)
-- Predict natively in T using the PMML model
predictions = node(
command = data |> mutate($pred = predict(data, model_r)),
deserializer = ^pmml
)
-- Shell node for reporting
report = shn(command = <{
printf 'Model cached at: %s\n' "$T_NODE_model_r/artifact"
}>)
}
build_pipeline(p)The ^pmml and ^csv symbols are first-class serializers from a registry. They handle data interchange contracts at build time, not runtime. If your R node outputs a CSV but your next node expects Arrow IPC, T catches the mismatch before execution.
The Nix Foundation
What makes T different from other DSLs is that Nix is not optional. The environment is a Nix flake, meaning it’s bit-for-bit reproducible. When you run nix shell github:b-rodrigues/tlang, you’re not just installing a binary, you’re entering a hermetic environment where every dependency, down to the C compiler used to build R’s data.table, is pinned.
This leverages Nix’s fixed-point evaluation model, where packages depend on one another through dependency injection. The result is that "dependency drift" becomes a meaningless concept. If the inputs haven’t changed, the output is pulled from cache. If they have, the entire derivation rebuilds deterministically.
For data science, this is revolutionary. It means the R code you wrote six months ago runs with the exact same libcurl, openssl, and gcc versions it was originally built with, regardless of what your laptop’s package manager has upgraded since then. It solves the polyglot problem by making R, Python, and system dependencies speak the same language: Nix expressions.
The Uncomfortable Trade-offs
Of course, mandatory reproducibility comes with mandatory friction. The most immediate is the learning curve. Nix is notoriously difficult to master, and T adds its own constraints on top. The language enforces functional purity in a domain, data science, where mutability is often the path of least resistance. You can’t just df['new_col'] = df['old_col'] * 2 and move on. You must think in pipelines and transformations.
Then there’s the serialization question. T uses PMML (Predictive Model Markup Language) to move models between R/Python and T’s native evaluator. This allows training in R and prediction in T without a runtime dependency, but PMML has documented limitations. Developers who’ve worked with it report floating-point precision errors that propagate through tree-based models, causing predictions to diverge at the Xth decimal place. Others note that PMML’s XML parsing overhead makes it unsuitable for real-time systems, with latencies of 300-500ms compared to Python pickle’s 50-100ms.
Battery Impact
Pros: Bit-for-bit reproducibility, strict type safety, deterministic builds.
The Cost
Cons: High learning curve, slower iteration loops, potential precision loss in models.
These aren’t deal-breakers for batch analytics, but they illustrate a hard truth: reproducibility and performance are often in tension. T prioritizes the former.
There’s also the question of ergonomics. T’s error handling treats errors as values, not exceptions. The |> operator short-circuits on errors, while ?|> forwards them for recovery. This is elegant but alien to most data scientists raised on Python’s try/except or R’s ifelse chains. The REPL provides interactive exploration, but once you commit to a pipeline, you’re committing to functional purity.
When to Embrace the Complexity
So should you rewrite your Airflow DAGs in T? Probably not, yet. The language is at v0.51.2, missing graphics libraries, and lacks Julia support. But the approach signals a shift in how we think about convergence between AI engineering and traditional data engineering roles. As models become infrastructure, reproducibility becomes a infrastructure requirement, not a nice-to-have.
Yes, Use T When…
- You’re doing regulated research requiring legal compliance
- Your team spans R, Python, and Julia
- You need CI/CD caching for intermediate artifacts
- Auditability is more important than velocity
No, Avoid T When…
- Exploratory Data Analysis (EDA) is priority
- You need sub-100ms prediction latency
- Your team isn’t willing to climb the Nix learning curve
- You rely heavily on proprietary closed-source libraries
It doesn’t make sense when:
– You’re doing exploratory data analysis where iteration speed matters more than reproducibility
– Your models need sub-100ms prediction latency (due to PMML overhead)
– Your team isn’t willing to climb the Nix learning curve
The broader lesson isn’t that T will replace Airflow. It’s that alternative ETL tool selection and hidden infrastructure costs are forcing us to reconsider what “orchestration” means. Is it just scheduling? Or is it environmental hermeticism?
The Infrastructure of Truth
T’s real innovation might be philosophical. By making Nix mandatory, it forces data scientists to confront the reality that their computational environment is part of their methodology. You can’t hand-wave away the gcc version or the glibc compatibility layer. You can’t pretend that pip install is a reproducible operation.
This aligns with growing awareness that infrastructure bottlenecks that compound reproducibility issues often stem from treating environment management as an afterthought. Just as network file sync tools reveal that rsync’s single-threaded nature is the real bottleneck, T reveals that Docker’s layer caching is a band-aid over the wound of non-deterministic package resolution.
The question isn’t whether T will become the next Airflow. It’s whether the industry will move toward mandatory reproducibility as a default. We’ve seen this shift in software engineering with NixOS and Guix. Data science, with its polyglot chaos and enterprise storage decisions that cascade into downstream data problems, might be next.
The “works on my machine” era is ending. The question is whether we’re ready for the discipline required to replace it.