
N8N’s RAM Addiction: Why Your ‘Free’ ETL Tool is Eating Your Server Alive
When a French CTO posted on Reddit last week about his N8N-powered nightmare, 16GB of RAM, an AMD EPYC processor, and still struggling to process a few million rows, the data engineering community’s response was telling. Half the comments said “just use Python and cron”, the other half suggested tools that would make his resource problems worse. The real answer? Your ETL tool is probably the wrong tool for your actual problem.
The post hit a nerve because it exposes a dirty secret in the open-source data world: we’ve been sold a scalability fantasy that bankrupts small businesses before they ever hit scale. Let’s dissect what the benchmarks actually tell us about N8N, Apache Hop, and what you should actually be using when your VM budget is real but your data volumes aren’t “enterprise” yet.
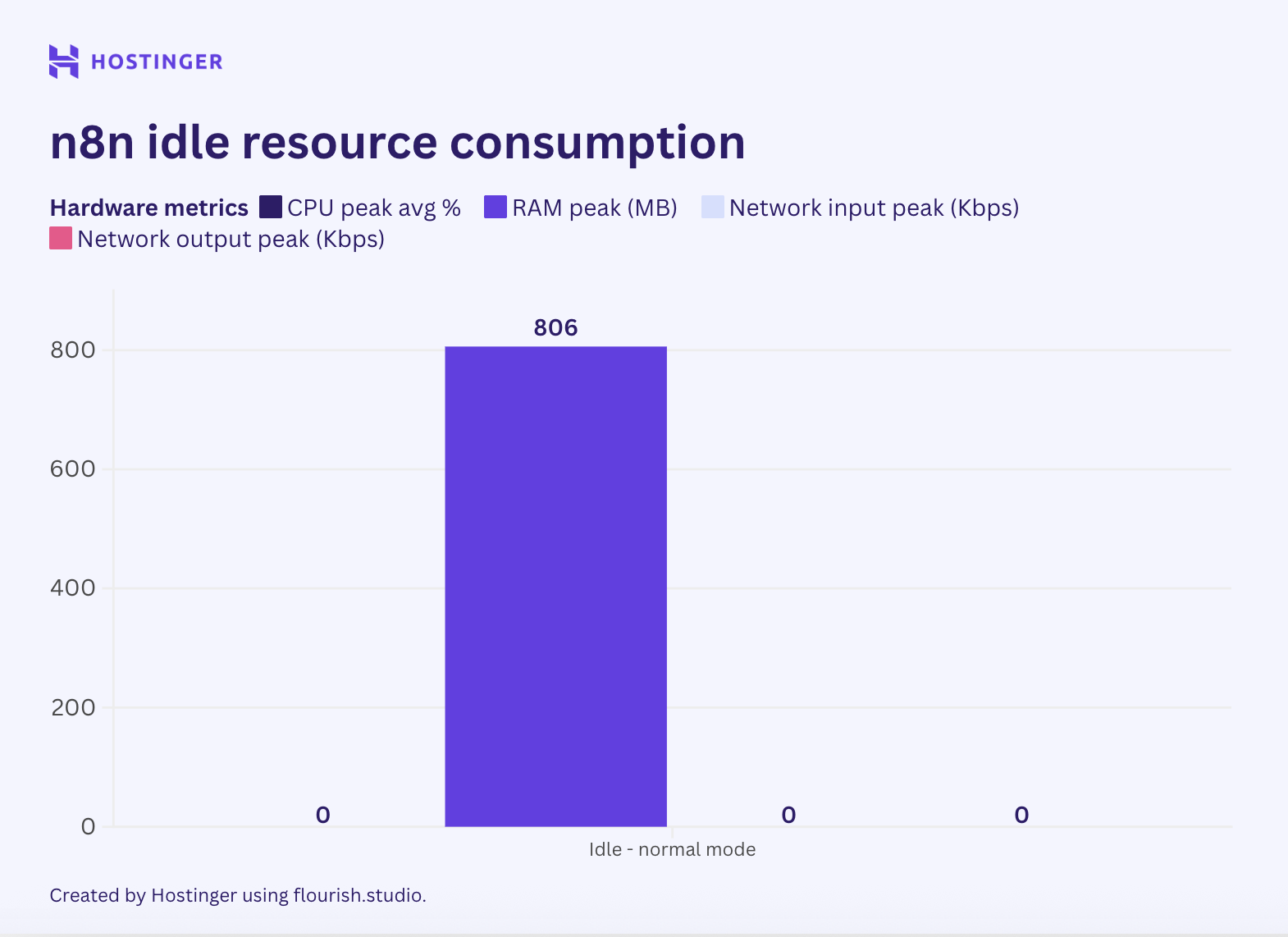
The 860MB Idle Problem: N8N’s Resource Hunger Exposed
The most damning data comes from Hostinger’s recent benchmark of N8N’s real-world resource consumption. At idle, with zero workflows running, N8N consumes 860MB of RAM. That’s not a typo. Nearly a gigabyte of memory just to exist.
For context, that’s more than a PostgreSQL instance running with a 100-connection pool. It’s more than a Redis cluster with active persistence. It’s more than most of your actual data processing tools will ever need. And that’s before you process a single byte of JSON or touch one XLSX file.
The benchmark gets worse. When you start adding nodes, even simple internal code nodes, RAM usage scales unpredictably. One code node adds 9MB. Add a second identical node? Only 5MB more. This non-linear scaling pattern means you can’t accurately predict your resource needs as you add complexity. For a small business trying to budget VM costs, this is financial Russian roulette.
External nodes (like your HTTP requests to fetch data) are even more brutal. They consume up to 10x the network I/O of internal nodes and spike RAM usage in ways that make capacity planning impossible. The French CTO’s use case, processing JSON and XLSX files daily, would trigger these external node penalties constantly.
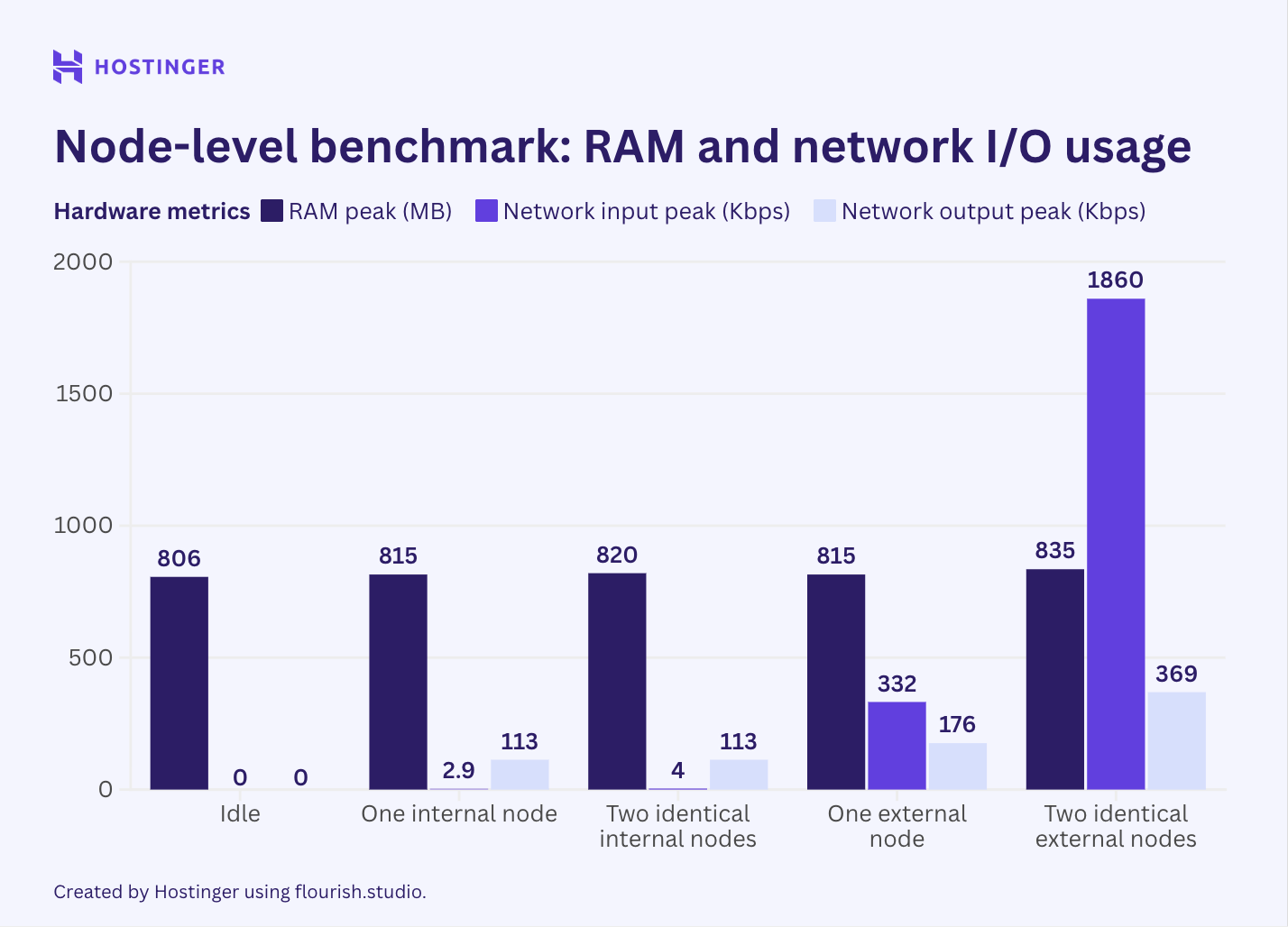
The kicker? N8N’s queue mode, the supposed solution for resource constraints, doubles baseline RAM usage while barely improving peak performance. You’re paying a 100% memory tax for a feature that doesn’t solve your core problem.
Apache Hop: The “Enterprise” Alternative That’s Not Actually Lighter
When the Reddit thread mentioned Apache Hop as a potential alternative, experienced engineers should have winced. Hop is a fork of the Pentaho Data Integration (Kettle) project, a tool built for literal enterprise data warehouses, not a 16GB VM processing daily files.
Hop’s architecture assumes you have:
– Dedicated ETL servers with 32GB+ RAM
– Enterprise databases as transformation engines
– Data volumes measured in billions of rows, not millions
– A team to maintain complex job orchestration
For a small business with one CTO and a VM, Hop is like using a freight truck for grocery shopping. Yes, it can carry more groceries. No, that doesn’t make it the right choice.
The real problem isn’t N8N vs. Hop. It’s that both tools come from ecosystems where resource abundance is assumed. They’re designed for scenarios where throwing more hardware at the problem is cheaper than optimizing the software. That’s the exact opposite of a small business’s reality.
The Python + Cron Reality Check
The most upvoted comment in the Reddit thread cut through the noise: “Just use normal python and crontab.” And it’s right, but not for the reason you think.
Python scripts aren’t inherently more efficient. A poorly written pandas script will happily consume all 16GB of RAM and ask for more. The difference is predictability and control. When you write Python, you see exactly where memory gets allocated. You can profile line-by-line. You can chunk data explicitly. You can choose libraries optimized for your use case.
Consider DuckDB, the in-process analytical database that multiple commenters recommended. It processes data 10-100x faster than pandas for analytical workloads, runs in-process with minimal overhead, and has a Python API that’s trivial to integrate:
import duckdb
import pandas as pd
# Process a million rows without breaking a sweat
con = duckdb.connect()
con.execute("""CREATE TABLE sales AS
SELECT * FROM read_json_auto('sales_*.json')""")
# Complex transformations that would choke N8N
result = con.execute("""SELECT
customer_id,
SUM(amount) as total_spent,
AVG(amount) as avg_order,
COUNT(DISTINCT date) as purchase_frequency
FROM sales
GROUP BY customer_id
HAVING total_spent > 1000""").df()
# Write directly to PostgreSQL
con.execute("COPY result TO 'postgres://user:pass@host/db'")This entire pipeline uses less than 200MB of RAM for millions of rows. Try that with N8N’s Loop Over Items node, which holds all processed results in memory until the loop finishes, frequently crashing on datasets over 1,000 items.
The Scalability Trap You’re Probably Building
The French CTO’s follow-up question revealed the real anxiety: “What if I need 40 different methods for clients and tens of millions of rows?” This is the scalability trap, the premature optimization that leads small businesses to adopt “enterprise” tools they don’t need.
Here’s the uncomfortable truth: 40 Python scripts with shared utility functions are more maintainable than 40 visual workflows. The visual abstraction that makes N8N appealing for simple automations becomes a liability at scale. You can’t version control workflows effectively. You can’t write unit tests for nodes. You can’t refactor with IDE tooling.
The Reddit commenter who said “40 python scripts if you are smart and write reusable function files / classes is not that many scripts” is absolutely correct. Modern Python tooling, poetry for dependency management, pytest for testing, pre-commit for code quality, makes this approach production-ready without the overhead of a “platform.”
And if you do hit tens of millions of rows? You’ll have outgrown N8N and Apache Hop anyway. You’ll be looking at open source data storage and lakehouse frameworks for scalable data transformation like Iceberg or Delta Lake, or managed services that can actually handle scale. The tool you need at 10 million rows is not the tool you need at 1 million.
Real Alternatives That Respect Your Resources
1. DuckDB + Python + Cron
- RAM usage: 50-200MB for typical workloads
- Learning curve: Moderate (SQL + Python)
- Scalability: Handles billions of rows with proper chunking
- Cost: $0 + your time
2. Airbyte + Airflow (Self-Hosted)
One Reddit user reported success with a small team: “We self host airbyte and also airflow… Airbyte does not give any issue whatsoever wrt hosting. We create connections declaratively using terraform and orchestrate them with airflow.”
The key difference? Airbyte’s connectors are separate Docker containers, so idle overhead is minimal. You only pay the resource cost when actively syncing data.
3. PipelineWise
An open-source ETL tool designed specifically for efficient data replication. It’s lightweight, uses Singer.io taps/targets, and has predictable resource usage. Unlike N8N, it’s built for batch data movement, not event-driven automation.
4. Meltano
GitLab’s open-source data integration platform. It’s essentially a wrapper around Singer taps/targets with proper project structure, version control, and extensibility. The resource footprint is minimal because it’s just orchestrating other tools.
The Open Source Sustainability Question
The deeper issue here is long-term sustainability and stewardship risks in critical open source projects. N8N is venture-backed. Apache Hop is a community fork of a commercial product. When you build your business on these tools, you’re betting on their continued development and support.
The risks of open source data transformation tools being acquired or de-prioritized are real. Just look at dbt Labs merging with Fivetran, what happens to the open-source core when commercial interests shift? The French CTO’s concern about scalability is valid, but the bigger risk is building on a platform that won’t exist in its current form in five years.
This is where boring, stable tools like Python and SQL shine. They’re not getting acquired. They’re not pivoting to AI features to please investors. They just work, and they’ll keep working.
Data Sovereignty: The Real Reason to Self-Host
The French CTO mentioned security as a primary concern. This is where motivations for organizations to adopt open source solutions for data sovereignty and independence become relevant. When the International Criminal Court defected from Microsoft to open-source tools, it wasn’t about cost, it was about geopolitical independence.
For a small business, data sovereignty might mean:
– Not being locked into a vendor’s pricing changes
– Keeping customer data in your jurisdiction
– Maintaining operations if a cloud service goes down
But sovereignty requires tools you can actually run on modest hardware. N8N’s 860MB idle footprint means you’re one Docker update away from swapping. Python scripts using DuckDB can run on a Raspberry Pi if needed.
The Performance Lie: What “Scalable” Actually Means
N8N’s documentation claims it can handle “unlimited workflows.” The benchmark tells a different story. When processing arrays larger than 1,000 items, the platform frequently crashes with memory overload errors. The “Split in Batches” node helps, but it’s a band-aid on an architectural limitation.
Compare this to DuckDB, which processes billions of rows using vectorized execution and streaming aggregation. Or to Airbyte, which uses incremental syncs to minimize resource usage. These tools are designed for data volume from day one.
The risks of adopting open source tools with inadequate testing and community support are evident here. N8N is excellent for API integrations and simple automations, but its loop functionality was clearly designed for small datasets. The community is full of developers hitting these limits and being told to “just use batching”, which misses the point: the tool’s architecture doesn’t match the use case.
When to Actually Use N8N or Apache Hop
Let’s be fair. These tools have their place:
Use N8N when:
– You’re integrating SaaS APIs (not processing files)
– Workflow count is under 20
– Data volume is under 10,000 records per run
– You need webhook triggers and event-driven flows
Use Apache Hop when:
– You have a dedicated ETL server with 32GB+ RAM
– You’re building data warehouse pipelines
– You need visual debugging for complex transformations
– Your team includes non-developers who can maintain visual workflows
Use neither when:
– You’re processing files daily to a database
– RAM budget is under 4GB
– You need predictable resource usage
– You want to version control your logic
The Bottom Line: Build for Your Actual Scale
The French CTO’s question reveals a common anxiety: what if we grow? But growth is not binary. You don’t jump from 1 million rows to 1 billion overnight. You evolve, and your tools should evolve with you.
Start with Python + DuckDB + Cron. It’s boring. It’s stable. It uses 200MB of RAM. When you hit real scale, say, 100 million rows, you’ll have the revenue to hire data engineers who can evaluate successful open-weight AI models that demonstrate the value of truly open, usable tooling or build proper data infrastructure.
Until then, every dollar you spend on VM resources is a dollar you can’t spend on growth. Every hour you spend debugging N8N’s memory usage is an hour you’re not building features your customers actually pay for.
The most scalable solution is the one you can afford to run today. Everything else is just vendor marketing dressed up as architecture advice.
What are you actually running for ETL? Have you hit N8N’s memory wall? Did you go from Python scripts to a “real” tool and regret it? Drop your war stories in the comments, especially if you’ve found a genuinely lightweight alternative that the benchmarks missed.


{kind=link}