Kimi Just Made Residual Connections Obsolete: The 10-Year Assumption That Crumbled Overnight
For a decade, residual connections have been the unshakeable bedrock of deep learning. Since He et al. solved the vanishing gradient problem in 2015, every major transformer, from GPT-2 to GPT-5, from BERT to the latest Kimi parameter-heavy releases, has relied on the same mechanism: each layer adds its output to a running sum with fixed unit weights. It worked well enough that nobody questioned it. Until now.
Moonshot AI’s research team just published a paper that effectively declares residual connections obsolete. Their new Attention Residuals (AttnRes) architecture replaces the dumb accumulation of layer outputs with a selective, learned attention mechanism over network depth. The results are stark: Block AttnRes matches the performance of standard models trained with 1.25× more compute, while cutting inference latency overhead to under 2%. In a field where architectural innovations usually trade efficiency for complexity, this is a genuine paradigm shift.
The PreNorm Dilution Problem Nobody Talked About
The standard residual connection seems elegant in its simplicity, too elegant, perhaps. In PreNorm architectures, each layer receives the exact same uniformly-weighted sum of all previous layer outputs. As one researcher put it, imagine a cocktail party where every new arrival shouts at the same volume as everyone else, by the tenth person, the noise is deafening and the early insights are buried.
This phenomenon, known as PreNorm dilution, creates three structural failures that worsen as models scale:
- No Selective Access: Attention layers and feed-forward networks receive identical aggregated states, even though they need different mixtures of earlier information.
- Irreversible Loss: Once information blends into the residual stream, later layers cannot selectively recover specific earlier representations.
- Output Growth: Deeper layers must produce increasingly larger outputs just to remain influential inside the ever-growing accumulated state, destabilizing training.
The AI industry has essentially been building taller skyscrapers on foundations that compress their lowest floors. While alternative hybrid architectures like Mamba-2 have attempted to bypass the transformer entirely, most labs simply accepted PreNorm dilution as a cost of doing business.
Attention Over Depth: How AttnRes Actually Works
Attention Residuals applies the same insight that revolutionized sequence modeling, replacing fixed recurrence with learned attention, but applies it to the depth dimension rather than the token sequence.
Instead of adding layer outputs with equal weight, each layer in AttnRes computes a weighted combination of all previous layer outputs using softmax attention. Each layer possesses a learned pseudo-query vector (initialized to zero to ensure stable training starts) that attends over RMS-normalized previous layer outputs. This allows Layer 47 to selectively emphasize crucial insights from Layer 2 while suppressing noise from Layer 15.
Technical Mechanism
- Keys and Values: Derived from the token embedding and previous layer outputs after RMSNorm (preventing large-magnitude outputs from dominating)
- Query: A layer-specific learned vector $w_l \in \mathbb{R}^d$, not input-conditioned
- Computation: Standard softmax attention over depth positions rather than sequence positions
The result is that standard residual connections become a special case, AttnRes with uniform attention weights. By learning these weights, the network transforms depth-wise aggregation from a compressed recurrence into an explicit retrieval mechanism.
Block AttnRes: Engineering for Scale
Full AttnRes requires $O(L^2d)$ arithmetic and $O(Ld)$ memory per token, manageable for small models but prohibitive when training 48-billion-parameter Mixture-of-Experts systems across pipeline-parallel GPUs. The memory and communication overhead of storing all previous layer outputs and transmitting them across pipeline stages would crush training efficiency.
Moonshot’s solution is Block AttnRes, an elegant engineering compromise that reduces complexity from $O(Ld)$ to $O(Nd)$ where $N$ is the number of blocks (typically around 8). Instead of attending over every individual layer, the model partitions layers into blocks, sums outputs within each block into a single representation, and applies cross-block attention only over these summaries.
The implementation details reveal serious systems thinking:
- Cross-Stage Caching: Eliminates redundant transfers under pipeline parallelism
- Two-Phase Inference: Amortizes cross-block attention computation costs
- Zero Initialization: All pseudo-query vectors start at zero, making initial attention uniform and avoiding early training instability
The overhead is remarkably minimal: less than 4% additional training cost under pipeline parallelism and under 2% inference latency increase on typical workloads. For context, many “revolutionary” architectural tweaks introduce 20-30% overhead that kills production viability.
The Empirical Evidence
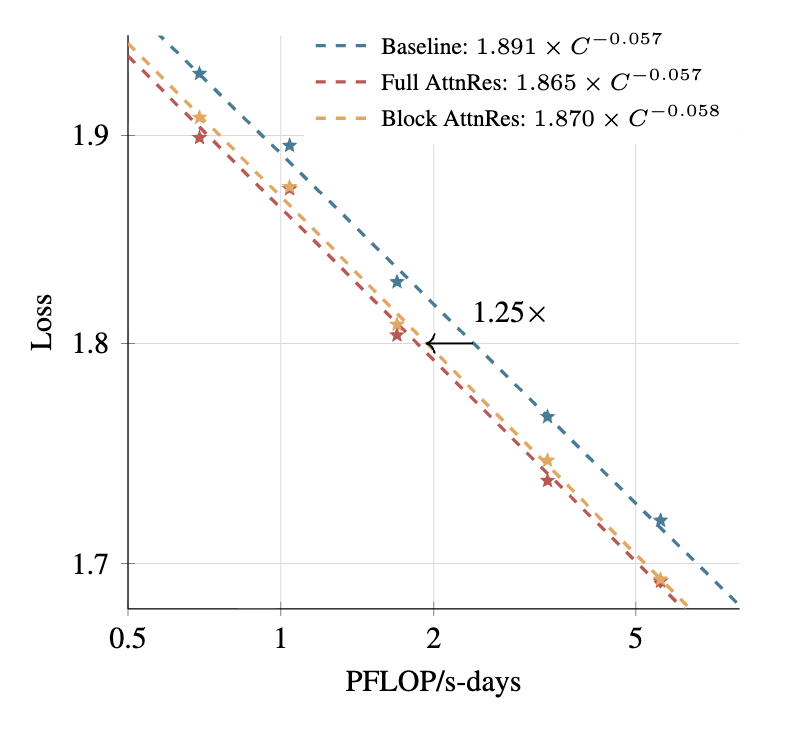
Moonshot integrated Block AttnRes into Kimi Linear, a 48B-parameter (3B activated) MoE architecture trained on 1.4T tokens. The scaling law experiments tell a clear story:
| Architecture | Scaling Law | Compute Efficiency |
|---|---|---|
| Baseline PreNorm | $L = 1.891 \times C^{-0.057}$ | 1.0× baseline |
| Block AttnRes | $L = 1.870 \times C^{-0.058}$ | ~1.25× equivalent |
| Full AttnRes | $L = 1.865 \times C^{-0.057}$ | ~1.3× equivalent |
Block AttnRes achieves the same validation loss as the baseline architecture trained with 25% more compute. This isn’t a marginal gain, it’s the difference between a $10M training run and a $12.5M run for identical capability.
Downstream benchmarks confirm the architectural superiority, particularly in multi-step reasoning where selective retrieval matters most:
Minerva Math: 53.5 → 57.1 (+3.6 points)
HumanEval: 59.1 → 62.2 (+3.1 points)
MMLU: 73.5 → 74.6 (+1.1 points)
The training dynamics reveal why: AttnRes mitigates PreNorm dilution by keeping output magnitudes bounded across depth and distributing gradient norms uniformly. Later layers can precisely retrieve early representations rather than shouting over accumulated noise.
The Broader Context: mHC, DenseNet, and Open Source Anxiety
This isn’t the first attempt to rethink residual connections. DeepSeek’s Manifold Constrained Hyperconnections (mHC), published around New Year 2026, also modifies the residual path using learnable projection matrices. The community has noted that while mHC offers theoretical elegance, AttnRes appears more practical for large-scale deployment.
Interestingly, developers have pointed out parallels to DenseNet (2016), which applied similar dense connectivity to CNNs using concatenation rather than attention. The concept that layers should selectively access earlier representations rather than receiving a “dumb running sum” has been floating around for years, but the transformer era’s “if it ain’t broke” attitude delayed experimentation.
The release has sparked predictable anxiety in open-source circles. Independent researchers have noted that they had similar ideas in development, one mentioned a “subformer” concept using “layer subscription” terminology, only to be beaten to publication by well-funded labs. The sentiment reflects a growing tension: architectural breakthroughs increasingly require compute resources that only Moonshot, DeepSeek, and a handful of other labs can access, even when the underlying ideas are conceptually simple.
Why This Actually Matters for Production
If you’re deploying models for complex coding or mathematical reasoning, standard architectures are actively bottlenecking your results. The industry shift toward active parameter efficiency and sparse activation strategies has already shown that brute-force scaling hits diminishing returns. AttnRes offers a different path: better wiring instead of bigger buildings.
The implications extend to practical local hardware implementations. If AttnRes can deliver frontier performance with 25% less compute, the threshold for running capable models on consumer hardware drops accordingly. Combined with the broader Kimi ecosystem capabilities, this suggests Moonshot is optimizing for efficiency gains that compound across their entire model stack.
Critically, this challenges the assumption that transformer architectures are “solved.” For years, innovation focused on training data, context length, and specialized small models versus large architectures. By attacking the fundamental layer aggregation mechanism, Moonshot has opened a new frontier in architecture design.
The Verdict
Attention Residuals isn’t just an incremental improvement, it’s a fundamental rewiring of how information travels through neural networks. By treating depth as a sequence dimension and applying learned attention rather than fixed accumulation, Moonshot has eliminated the PreNorm dilution that has plagued deep transformers for a decade.
The 2% inference overhead makes this immediately deployable, unlike many research curiosities that die in the gap between paper and production. If the scaling laws hold at trillion-parameter scales, we may look back at March 2026 as the moment the industry finally moved beyond residual connections.
The code and paper are available on GitHub, though reproducing these results will require the kind of compute budget that makes Kimi’s $500K “open source” releases look economical. For practitioners, the immediate takeaway is clear: the next generation of models won’t just be bigger, they’ll be architecturally smarter, with layers that actually remember why they exist rather than shouting into the void.