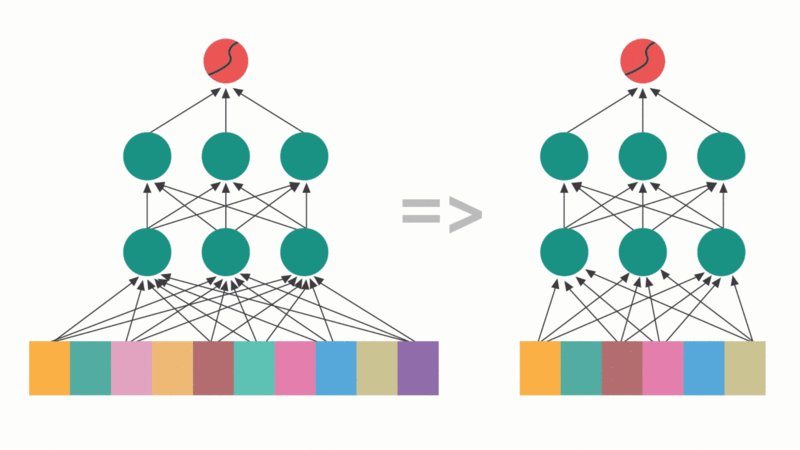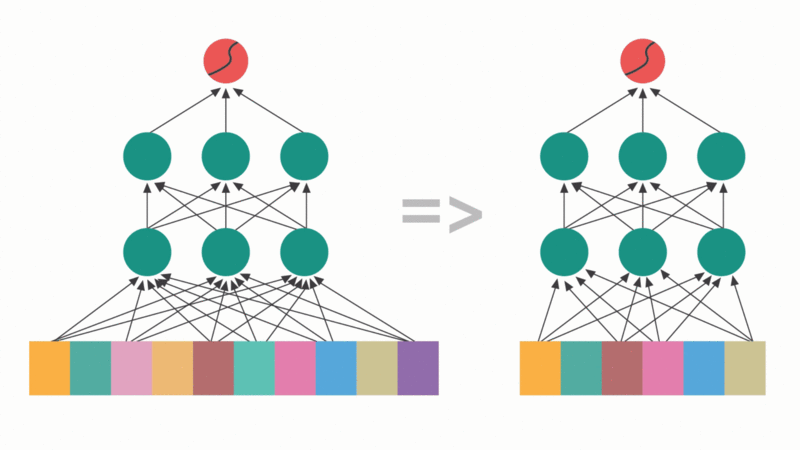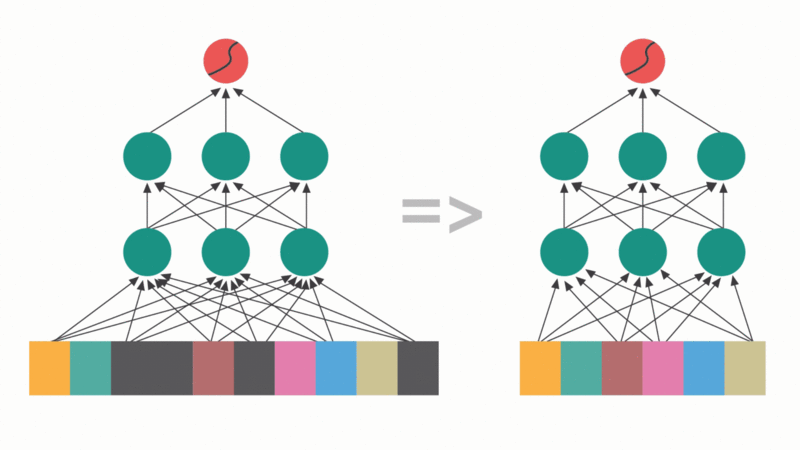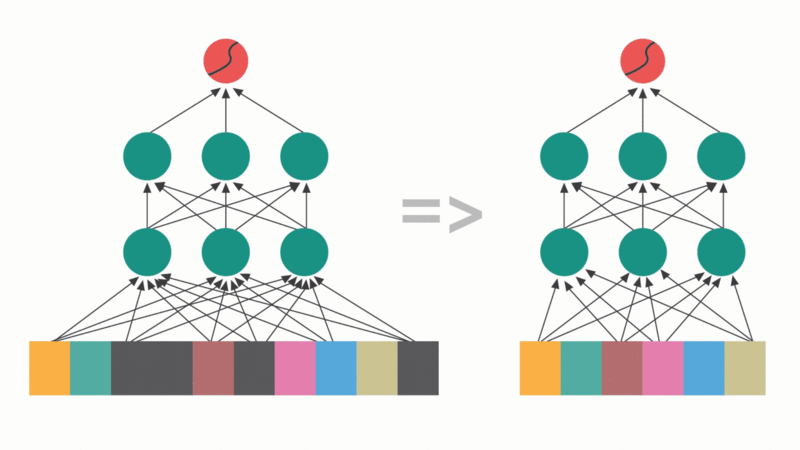
Google’s latest research paper reads like a direct attack on everything transformers stand for. While the AI industry races toward ever-larger parallel processing clusters, Google Research is asking a heretical question: what if we stopped trying to compute everything at once?
Sequential Attention, introduced in a recent Google Research blog post, proposes a radical departure from standard attention mechanisms. Instead of calculating attention scores for all tokens simultaneously, a process that gives transformers their quadratic computational complexity, this method processes tokens sequentially, selecting features one at a time like a careful curator rather than a bulk processor.
The timing couldn’t be more deliberate. As diffusion-based language models challenge autoregressive generation and smaller models like Maincoder-1B prove that size isn’t everything, the transformer architecture is facing existential questions about its efficiency. Sequential Attention arrives as both an answer and a provocation.
The Core Heresy: Sequential Processing in a Parallel World
Standard attention mechanisms operate like an overeager student who highlights every sentence in a textbook. They compute relationships between all token pairs simultaneously, creating massive attention matrices that grow quadratically with sequence length. This parallel processing is the secret sauce behind transformers’ remarkable capabilities, and the reason they devour GPU memory like candy.
Sequential Attention takes the opposite approach. It maintains a growing set of “selected” features and uses them as context to find the next most informative candidate. Think of it as reading a book and carefully choosing which passages to bookmark based on what you’ve already marked, rather than evaluating every paragraph’s importance in isolation.
The mechanism leverages attention scores themselves as a diagnostic tool, allowing researchers to inspect exactly which parts of the input a model prioritizes. This interpretability is a side effect that the Google team practically shrugs at in their paper, “oh, and by the way, you can see what the model is thinking”, but it’s potentially more valuable than the efficiency gains themselves in an era of black-box AI.
The “Free Lunch” Claim That’s Raising Eyebrows
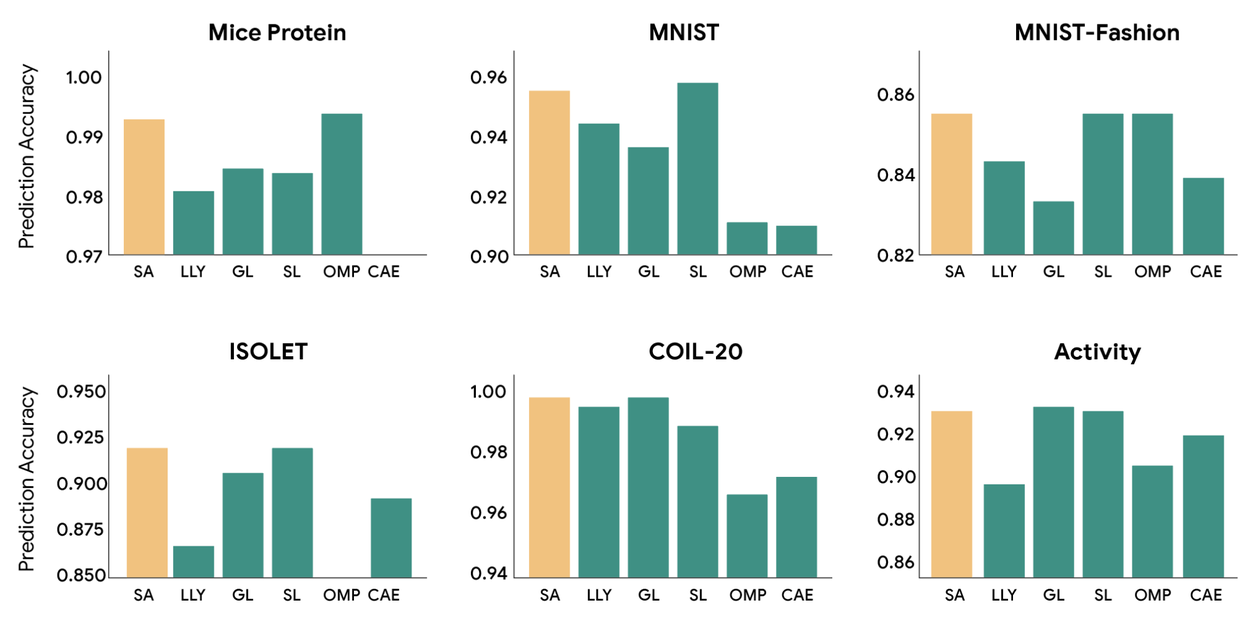
Google’s headline promise is seductive: “Making AI models leaner and faster without sacrificing accuracy.” The research demonstrates state-of-the-art results across proteomics, image, and activity recognition benchmarks. When applied to linear regression, the algorithm is mathematically equivalent to Orthogonal Matching Pursuit (OMP), a method with provable performance guarantees.
But the developer community isn’t buying the marketing wholesale. The prevailing sentiment on technical forums is that “without sacrificing accuracy” means “it seems to perform equally well according to our tests”, not “it computes exactly the same thing” like Flash Attention does. This is approximation, not equivalence. One researcher noted that the method appears to be more of a feature selection algorithm for regression problems than a universal attention mechanism for LLMs.
The skepticism runs deeper. Some engineers argue that sequential processing is inherently impractical for large language models because processing tokens one at a time creates a latency bottleneck that parallel architectures were specifically designed to eliminate. You can’t just retrofit this mechanism to existing models without massive retraining, and even then, the sequential nature might make inference painfully slow for real-time applications.
From Theory to Practice: Where This Actually Works
Where Sequential Attention shines is in structured pruning and feature selection. The algorithm calculates attention weights for all remaining features at each step, permanently adding the highest-scoring feature to its selected subset. This recalculation naturally reflects marginal gain, allowing the model to identify and avoid redundant features.
The research team extended this to SequentialAttention++ for Block Sparsification, uniting differentiable pruning with combinatorial optimization. This framework discovers the most important blocks of weight matrices, enabling structured pruning that removes entire channels or blocks for real hardware acceleration on GPUs and TPUs. The results show significant gains in model compression without accuracy loss on ImageNet classification.
For large embedding models in recommender systems, where feature selection and embedding dimension optimization are critical, Sequential Attention has already demonstrated measurable quality improvements and computational savings. The ability to handle heterogeneous features with large embedding tables makes it immediately practical for production recommendation systems.
The LLM Pruning Promise (and Peril)
The most tantalizing application is LLM pruning. The Google team suggests that SequentialAttention++ could enforce structured sparsity, prune redundant attention heads, reduce embedding dimensions, or even eliminate entire transformer blocks. This could dramatically reduce model footprint and inference latency while preserving performance.
But here’s where the skepticism from the developer community becomes concrete. The concern isn’t whether pruning works, it does. The concern is whether the sequential selection process itself becomes a computational anchor. When you’re processing billions of tokens, even a small per-token overhead in sequential selection can balloon into massive latency. As one engineer pointed out, this seems more suited for ML applications with smaller contexts than for the 100K+ token windows modern LLMs demand.
The comparison with CPU optimization techniques for efficient LLM inference is telling. While researchers find ways to accelerate top-k sampling by 20x using AVX2 instructions, Sequential Attention is fundamentally constrained by its sequential nature. You can’t vectorize what must be computed step by step.
The Broader Context: An Efficiency Arms Race
Sequential Attention enters a crowded field of efficiency solutions. Diffusion-based language models are challenging autoregressive generation by fundamentally changing how tokens are generated. Small models like Maincoder-1B achieve 76% on HumanEval through optimized training rather than architectural changes. And runtime efficiency battles like llama.cpp vs Ollama show that implementation details matter as much as architecture.
What makes Sequential Attention different is its philosophical stance. While most efficiency research accepts the parallel processing paradigm and tries to optimize within it, Google is questioning the paradigm itself. This is either brilliant or misguided, depending on who you ask.
The method’s connection to Orthogonal Matching Pursuit is instructive. OMP works because it makes greedy decisions that are provably optimal under certain conditions. But language modeling isn’t a sparse recovery problem, it’s a complex conditional generation task where the importance of a token depends on subtle interactions across the entire context. Whether greedy selection captures these interactions or oversimplifies them remains an open question.
Future Directions: Beyond Feature Selection
Google’s research roadmap for Sequential Attention includes three domains where sequential selection might shine:
-
Feature Engineering with Real Constraints: Enabling fully automated, continual feature engineering that respects inference constraints. This is practical for recommendation systems where feature latency matters.
-
Drug Discovery and Genomics: Extracting influential genetic or chemical features from high-dimensional datasets. The interpretability aspect becomes crucial when dealing with biological mechanisms.
-
Continual Learning: The sparse updates in SequentialAttention++ might avoid catastrophic forgetting better than dense gradient updates. This is speculative but promising, online clustering algorithms naturally adapt to distribution shifts without erasing previous knowledge.
The team is also exploring more applications of subset selection to solve challenging problems in broader domains. This suggests they view Sequential Attention as a general-purpose optimization framework, not just an attention mechanism.
The Verdict: A Tool, Not a Panacea
Sequential Attention is less a replacement for standard attention and more a specialized tool for specific problems. Its sequential nature makes it ill-suited for real-time LLM inference, but potentially transformative for:
– Model compression and pruning pipelines
– Feature selection in high-dimensional data
– Interpretability research where understanding feature importance is key
– Recommendation systems with large embedding tables
The controversy isn’t whether it works, it demonstrably does for its target applications. The controversy is about scope. Google markets it as a paradigm shift for efficient transformers, while practitioners see a valuable but niche optimization technique.
For AI engineers, the practical takeaway is this: don’t rip out your parallel attention layers just yet. But if you’re struggling with model compression, feature selection, or need interpretable feature importance, Sequential Attention deserves a serious look. It’s not going to make your 70B model run faster at inference, but it might help you prune that 70B model to a more manageable 30B without performance collapse.
The real breakthrough might be the research direction itself. In an era of ever-larger models, Google is asking whether bigger is always better, or whether smarter selection can achieve more with less. That’s a question worth exploring, even if the answers aren’t as universal as the marketing suggests.
As the AI community grapples with mounting computational costs and environmental concerns, techniques like Sequential Attention, whether they succeed or fail, push us to reconsider fundamental assumptions. And in a field dominated by incremental improvements, that alone makes it worth watching.