Jamba2 Mini: AI21’s Radical Bet That Enterprise AI Doesn’t Need Reasoning
AI21 Labs just dropped Jamba2 Mini, a 52-billion parameter model that they insist on calling “mini.” The naming alone is enough to raise eyebrows, this thing has more parameters than GPT-3, but the real controversy runs deeper. While the rest of the industry chases reasoning models that “think” through problems with synthetic tokens, AI21 is making a contrarian bet: most enterprise AI doesn’t need to reason at all. It just needs to be reliable.

The “Mini” Model That Isn’t
Let’s address the elephant in the room: Jamba2 Mini’s naming is deliberately provocative. With 12 billion active parameters (52 billion total in its MoE architecture), it’s “mini” only compared to the behemoths like Jamba Large 1.7’s 399 billion parameters. But in production environments, this is still a substantial model, one that requires serious infrastructure.
The Reddit community immediately called this out. One commenter noted the absurdity: “52b named ‘mini’ lol.” But there’s method to the madness. AI21 is positioning Jamba2 Mini as the lean alternative to reasoning models, optimized for what enterprises actually do: retrieve information from massive documents and follow instructions precisely.
The SSM-Transformer Hybrid: Memory Efficiency as a Feature
Jamba2 Mini’s core technical innovation is its SSM-Transformer architecture, combining State Space Models with attention mechanisms. This isn’t just academic novelty, it’s a direct response to the memory wall that kills most long-context deployments.
According to recent benchmarking research, SSMs achieve 12.46× better memory efficiency than pure Transformers at 4,096 tokens, with the gap widening exponentially. The crossover point where SSMs become strictly more efficient occurs at just 220 tokens for memory and 370 tokens for inference time. For enterprise workflows processing technical manuals or legal contracts, this is a game-changer.
The architecture allows Jamba2 Mini to maintain its 256K context window without choking on its own memory footprint. In practical terms, this means the model can process an entire technical manual, a year’s worth of financial reports, or a complex legal contract in a single pass, without the computational overhead that makes similar context windows prohibitively expensive in pure Transformer models.
Enterprise Reliability: The Benchmarks That Actually Matter
AI21 focused on two metrics that map directly to production pain points: instruction-following and grounding. The model leads on IFBench, IFEval, Collie, and FACTS benchmarks, tests designed to measure whether a model does what you tell it and stays faithful to provided context.
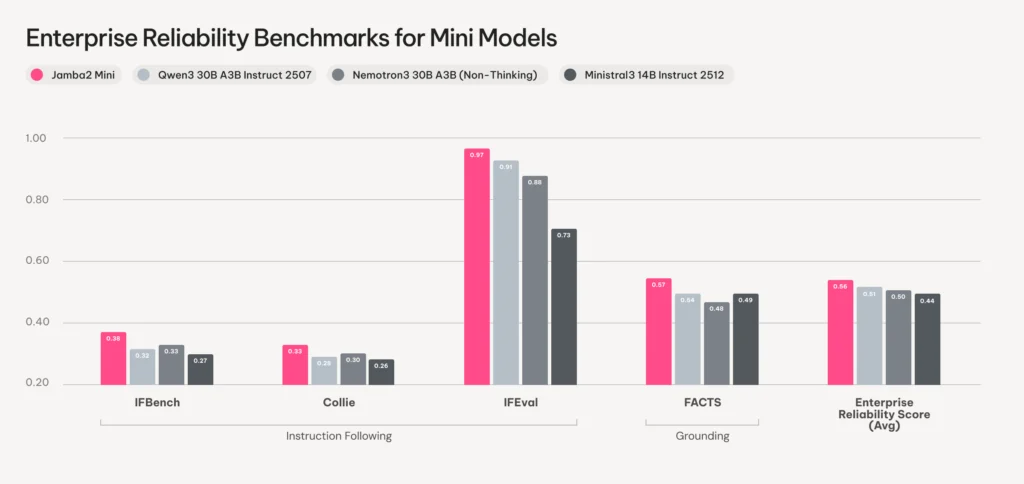
In blind human evaluations on 100 real-world enterprise prompts, Jamba2 Mini achieved statistically significant wins over Ministral3 14B on output quality and factuality. The evaluation protocol was rigorous: side-by-side comparisons with counterbalanced ordering, rated by content evaluation experts on factuality, style, constraint-adherence, instruction-following, and helpfulness.
This isn’t about beating benchmarks for bragging rights. It’s about solving the problem that 54% of enterprises cite as their number one AI risk: accuracy, according to McKinsey’s 2025 AI survey. When you’re building a customer service agent that references policy documents or a legal assistant that must cite specific contract clauses, “probably right” isn’t good enough.
The Anti-Reasoning Stance: Efficiency Over Synthetic Thought
Here’s where AI21 gets genuinely controversial. Their blog post explicitly positions Jamba2 Mini against reasoning models, arguing that “not every enterprise workflow requires the high cost and high latency of reasoning models.” In a world where o1-style reasoning is considered the cutting edge, this is heresy.
The argument is simple: most enterprise tasks are retrieval and synthesis, not problem-solving. An HR policy assistant doesn’t need to “think” about whether parental leave applies, it needs to find the relevant policy section and quote it accurately. A financial analyst doesn’t need synthetic reasoning to extract quarterly metrics from a 10-K filing.
Jamba2 Mini’s reliability-to-throughput ratio is the metric AI21 wants you to care about. The model maintains high performance at 100K+ token contexts while keeping memory usage lean enough for scalable deployments. In production agent stacks where consistent, grounded outputs are critical, this trade-off makes sense.
The Fine Print: Training and Lineage
Before you rip out your reasoning models, consider the caveats. Jamba2 Mini wasn’t trained from scratch, it builds on Jamba 1.5 pre-training weights. As one Reddit commenter pointed out, this makes the “Jamba2” naming potentially misleading: “They probably should have called it Jamba 1.8 if architecture and pre-trained base model is exactly the same.”
The post-training pipeline involved:
– Mid-training on 500B curated tokens with increased math, code, and long-document representation
– A state passing phase to optimize Mamba layers for context length generalization
– Cold start SFT followed by DPO optimization
– Multiple on-policy RL phases progressing from short-context to longer contexts
This is solid, contemporary LLM training, but it’s not a from-scratch breakthrough. The model inherits both the strengths and limitations of its Jamba 1.5 foundation.
The 3B Edge Model: Running on iPhones
Alongside Mini, AI21 released Jamba2 3B, an ultra-compact model that runs efficiently on consumer devices. This isn’t just a shrunken version, it’s designed for on-device deployments where reliability still matters but compute is severely constrained.
The model runs on iPhones, Androids, Macs, and PCs while maintaining the same 256K context window and enterprise-grade reliability metrics. For edge AI applications that need to process long documents locally (privacy-sensitive healthcare data, offline legal review), this fills a genuine gap.
Deployment Reality Check
For practitioners ready to experiment, here are the essentials:
vLLM serving (requires v0.12.0+):
vllm serve "ai21labs/AI21-Jamba2-Mini" \
--mamba-ssm-cache-dtype float32 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--enable-prefix-caching \
--quantization experts_int8Transformers integration:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"ai21labs/AI21-Jamba2-Mini",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("ai21labs/AI21-Jamba2-Mini")The Apache 2.0 license means full commercial use without the legal gymnastics required by some open-weight models. For enterprises already navigating AI risk, this matters.
The Skeptic’s View: Reddit’s Take
The LocalLLaMA community’s reaction was mixed. One top comment noted: “Previous Jamba models were terrible. They were an architectural novelty but their performance was abysmal. Curious to see if they’ve improved.”
This skepticism is healthy. The first-generation Jamba models underwhelmed, and architectural novelty doesn’t guarantee practical utility. The fact that Jamba2 builds on the same pre-training as Jamba 1.5 raises legitimate questions about whether this is incremental improvement or genuine advancement.
Another commenter pointed out the naming confusion: “It shares pre-training weights with Jamba 1.5, as per their own documentation. Pre-training from scratch is becoming less and less common.”
The trend toward fine-tuning existing models rather than training from scratch is real, and controversial. It makes AI development more accessible but raises questions about fundamental innovation.
What This Means for Enterprise AI Strategy
Jamba2 Mini represents a fork in the road for enterprise AI. The dominant narrative says you need massive reasoning models for complex tasks. AI21’s bet is that most enterprise value comes from reliable information retrieval at scale.
The evidence supports both sides. For creative problem-solving and genuine reasoning, o1-style models excel. But for the 80% of enterprise AI use cases, document analysis, policy enforcement, knowledge base QA, Jamba2 Mini’s approach may be more cost-effective and predictable.
The 256K context window isn’t just a spec sheet number. It enables workflows that are currently impossible: analyzing complete legal contracts without chunking, processing entire code repositories in one pass, or building agents that maintain context across hour-long interactions.
The Bottom Line: A Model That Knows Its Lane
Jamba2 Mini isn’t trying to be everything. It’s designed for a specific job: precise, grounded question answering in production agent stacks. The SSM-Transformer architecture delivers memory efficiency that makes long-context deployment practical, while the focus on instruction-following and grounding addresses real enterprise pain points.
The controversy isn’t whether Jamba2 Mini is good, it’s whether AI21’s anti-reasoning stance is prescient or limiting. As one team member noted on Reddit: “Mamba in general is no longer a novelty.” The architecture has matured, but the question remains: is efficiency without reasoning the right trade-off for most enterprises?
For now, Jamba2 Mini offers a compelling alternative for teams tired of reasoning model costs and latency. Whether it can deliver on AI21’s vision of enterprise AI without synthetic thought depends on your use case, and your appetite for betting against the reasoning model hype train.
What do you think? Is AI21 right that most enterprise AI doesn’t need reasoning, or is this a pragmatic solution that sacrifices too much capability for efficiency?