The AI industry has spent the last five years in a singular arms race: bigger models, more parameters, larger training clusters. The gospel was simple, scale solves all. But while OpenAI and Anthropic were building cathedral-sized models, a quieter revolution was brewing in the margins. The conviction driving it? LLMs cannot understand the world, and making them bigger won’t fix that fundamental limitation.
This isn’t speculative philosophy. It’s engineering practice. And it’s showing up in systems that “dream” about your codebase while you sleep, generating architectural insights with a fraction of the compute that traditional scaling demands.
The Ghost in the Machine: Z.E.T.A.’s Dream Cycles
The most concrete manifestation of this shift is Z.E.T.A. (Zero-shot Evolving Thought Architecture), a multi-model system that inverts the typical AI development workflow. Instead of waiting for human prompts, it runs autonomous “dream cycles” during idle time, free-associating across your code to generate bug fixes, refactors, and feature ideas.

The architecture is deliberately biological. A 14B model handles reasoning and planning, a 7B model generates code, and a 4B model manages embeddings and memory retrieval. But the magic happens in the HRM (Hierarchical Reasoning Module) and TRM (Temporal Reasoning Memory), which decompose queries and maintain Git-style thought branching with lambda-based temporal decay to prevent rumination.
Here’s what a dream output actually looks like:
code_idea: Buffer Pool Optimization
The process_request function allocates a new buffer on every call.
Consider a thread-local buffer pool:
typedef struct {
char buffer[BUFSIZE];
struct buffer_pool *next;
} buffer_pool_t;
This reduces allocation overhead in hot paths by ~40%.
Dreams are filtered for novelty using a repetition penalty tracker that rejects ideas with novelty scores below 0.3. The system has generated over 128 dreams with a 70% lucid validation rate, meaning the majority produce actionable insights that survive human review.
The GitHub repository shows the system is model-agnostic. You can swap GGUF paths based on your hardware:
| Your GPU | Main Model | Coder Model | Embedding Model |
|---|---|---|---|
| 16GB (5060 Ti, 4080) | Qwen 14B | Qwen Coder 7B | Nomic 4B |
| 24GB (4090) | Qwen 32B | Qwen Coder 14B | Nomic 4B |
| 48GB (A6000, dual 3090) | Qwen 72B | Qwen Coder 32B | Nomic 4B |
| 80GB (A100, H100) | Qwen 72B Q8 | Qwen Coder 32B Q8 | Nomic 4B |
Dream quality scales with model capability, but the key insight is that you don’t need a trillion parameters to generate useful architectural insights. You need the right architecture.
The 1 GPU vs 720 GPUs Lesson
While Z.E.T.A. was being built, DreamerV3 published results in Nature that should have stopped the scaling debate cold. One A100 GPU. 30 million environment steps. 17 days of simulated gameplay. It learned to find diamonds in Minecraft with no tutorials, no human data, no explanations of the rules.
For comparison, OpenAI’s VPT required 720 GPUs and 70,000 hours of human videos for the same task.
Same result. Different philosophy. DreamerV3 simulates internal experience, “dreaming”, during training, while VPT memorizes human demonstrations. The efficiency gap isn’t incremental, it’s architectural. One system generalizes from imagination, the other brute-forces from data.
This is the unspoken truth haunting the AI labs: we’re hitting diminishing returns on scale. The next frontier isn’t more parameters, it’s better memory structures, temporal reasoning, and autonomous knowledge consolidation.
Memory as First-Class Infrastructure
The industry is waking up to this. Cortex Memory, a production-ready framework built in Rust, treats memory as a fundamental primitive rather than an afterthought. It automatically extracts key facts from unstructured text, classifies and deduplicates memories, and optimizes them through periodic consolidation.
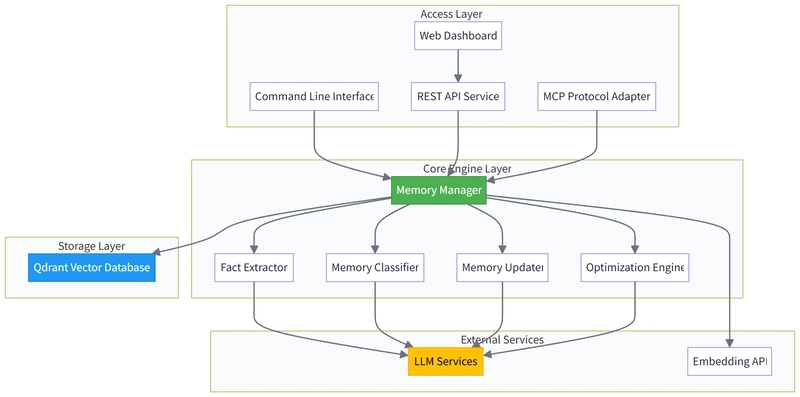
The architecture reveals where the field is heading:
cortex-mem-core → Core memory management engine
cortex-mem-service → REST API service
cortex-mem-cli → Command-line tool
cortex-mem-insights → Web management dashboard
cortex-mem-mcp → MCP adapter
cortex-mem-rig → Agent framework integration
This modular design supports what the survey “Memory in the Age of AI Agents” calls the Forms, Functions, Dynamics framework. Memory isn’t just storage, it’s a cognitive state that agents continuously maintain, update, and abstract through interaction.
Deep Agent CLI implements similar principles for coding assistants. Instead of stateless interactions, it persists knowledge across sessions in markdown files that developers can inspect, version control, and share. When you ask it to research a codebase, it writes comprehensive notes that inform future sessions, creating institutional knowledge that survives individual developers.
The Controversy: Autonomous Code Evolution
Here’s where things get spicy. Z.E.T.A. includes a self-improvement loop that can analyze its own source code and dream about improvements. The cycle is simple: ingest codebase → generate suggestions → implement valid ones → repeat.
The repository claims this README was generated through Z.E.T.A.’s recursive self-improvement loop. Let that sink in: the AI wrote its own documentation by dreaming about its architecture.
This raises questions that make traditional ML engineers uncomfortable:
- What happens when dream cycles generate code that humans don’t understand? Z.E.T.A. creator Todd Hendricks notes they started an “auto patching branch” but sought feedback before turning it loose. The hesitation is telling.
- Who owns the intellectual property when an AI evolves code autonomously? The project is dual-licensed AGPL-3.0/Commercial, but the legal frameworks for this are non-existent.
- How do you debug a system that changes itself while you’re not watching? The lambda-based temporal decay and novelty filters are heuristics, not guarantees.
Google Jules takes a more controlled approach. It operates asynchronously in isolated cloud VMs, analyzing entire repositories and submitting pull requests for human approval. But even here, the workflow is telling: Jules is designed for explicit instructions that can drive unattended batch work. The assumption is that humans want to delegate entire tasks, not micromanage them.
Why Memory-Augmented Systems Win
The efficiency argument is brutally simple. A 14B model with a sophisticated memory graph can outperform a 70B model on architectural reasoning because it accumulates understanding over time. The 70B model starts from scratch on every query, the 14B model builds on weeks of idle-time analysis.
This is the math the scaling lobby doesn’t want to discuss:
- Compute cost: DreamerV3’s 1 GPU vs VPT’s 720 GPUs
- Context window: Memory graphs have no token limit, LLMs hit walls at 128K
- Knowledge persistence: Memory systems learn, stateless models forget
- Specialization: Multi-agent systems with persistent memory become domain experts
Deep Agent CLI demonstrates this in practice. Creating a specialized agent for “deep-agent-expert” allows it to research a codebase, write comprehensive notes, and reference them in future sessions. The agent becomes increasingly effective because it understands not just the immediate task, but the broader architectural context.
A Fork in the Road
The AI community is at an inflection point. Down one path: trillion-parameter models that require nuclear power plants to train. Down the other: smaller, smarter systems that dream, remember, and evolve.
The research is clear. As one analysis put it: “By 2026, as AI agents become deeply embedded in software and business systems, their biggest bottleneck won’t be reasoning, it will be serving them the right context at the right time.”
Z.E.T.A., Cortex Memory, and Deep Agent CLI aren’t just experiments. They’re production-ready systems pointing toward a future where AI isn’t a tool you query, but a persistent collaborator that understands your codebase as a living system.
The question isn’t whether this shift will happen. It’s whether you’ll be building with these architectures or maintaining the cathedral-sized models they make obsolete.
The code is already running. The dreams are already being generated. The only question is: are you reviewing them in the morning, or still waiting for your 720 GPUs to finish training?