The AI industry’s fixation on parameter counts has become a kind of religious doctrine. Bigger models, bigger clusters, bigger budgets, the orthodoxy rarely questioned whether this arms race actually served developers building real products. Now, a 1-billion-parameter model from a small Australian startup has fired a shot straight into that dogma. Maincoder-1B scores 76.22% on HumanEval, outperforming models nearly twice its size and forcing an uncomfortable question: what if we’ve been optimizing for the wrong metric?
The Benchmark That Matters
HumanEval isn’t just another leaderboard trophy. It’s a functional correctness benchmark, 164 hand-crafted programming problems where models must generate code that actually passes unit tests. No fluff, no vibes-based evaluation, just working code. The fact that Maincoder-1B hits 76.22% here is significant because it demonstrates genuine reasoning capability, not just memorization of StackOverflow patterns.
The performance gap becomes stark when you examine the comparison table from Maincode’s own evaluation:
| Model | HumanEval | HumanEval+ | MBPP+ |
|---|---|---|---|
| Maincoder-1B | 0.7622 | 0.7256 | 0.7090 |
| deepseek-coder-1.3b-instruct | 0.5610 | 0.5305 | 0.6217 |
| SmolLM3-3B | 0.5366 | 0.5000 | 0.6799 |
| Qwen2.5-Coder-1.5B-Instruct | 0.4634 | 0.4451 | 0.6561 |
The 1B-parameter model doesn’t just edge out the competition, it dominates. The closest rival, DeepSeek’s 1.3B model, trails by over 20 percentage points. Even models with 3B parameters can’t touch these numbers. This isn’t incremental improvement, it’s a categorical leap that suggests parameter count has been serving as a crutch for suboptimal training methodologies.
What Makes It Tick
Maincoder-1B’s architecture reveals a deliberate focus on depth over width. With 32 layers at only 1536 hidden dimensions, the model employs a high depth-to-width ratio that prioritizes representational capacity through sequential processing rather than parallel width. The technical specifications read like a checklist of modern transformer optimizations:
- Rotary Position Embeddings with theta=1,000,000 for extended relative positioning
- Grouped Query Attention (4:1 query-to-KV ratio) reducing memory overhead
- QK Normalization stabilizing attention computation
- SwiGLU MLP layers for improved activation patterns
But the real secret sauce is the MCPO algorithm, a specialized reinforcement learning policy optimization method applied during fine-tuning. While most small models rely on basic supervised fine-tuning, Maincode used reinforcement learning to push the model toward correct code generation through trial and error. The reproducibility script shows they ran evaluations on AMD MI355X GPUs using EleutherAI’s framework, suggesting serious computational investment despite the modest final parameter count.
docker run --rm -it \
--device=/dev/kfd --device=/dev/dri --group-add=video \
--ipc=host --security-opt seccomp=unconfined \
-v $(pwd):/workspace -w /workspace \
-e HF_TOKEN \
-e PYTHONHASHSEED=0 \
-e TORCH_DETERMINISTIC=1 \
-e ROCBLAS_ATOMICS_MODE="0" \
-e MIOPEN_FIND_MODE="1" \
-e CUBLAS_WORKSPACE_CONFIG=":4096:8" \
-e HF_ALLOW_CODE_EVAL="1" \
rocm/pytorch:rocm7.1.1_ubuntu24.04_py3.12_pytorch_release_2.9.1 \
bash -c 'pip install "lm_eval[hf]" && \
accelerate launch -m lm_eval \
--model hf --model_args "pretrained=Maincode/Maincoder-1B,trust_remote_code=True,dtype=float32" \
--tasks humaneval,humaneval_plus,mbpp_plus,mmlu,gsm8k \
--device cuda:0 --batch_size 32 --seed 42 \
--confirm_run_unsafe_code'This level of engineering rigor suggests Maincode didn’t just train a small model, they trained a smart small model, optimizing every decision for the target deployment environment.
The Community’s Split Reaction
Developer forums show a fascinating split. On one side, veterans who remember when GPT-2 powered the first magical autocomplete experiences see immediate utility. The sentiment echoes early Tab9 users from 2019 who watched one-to-two-line completions feel like pure sorcery. For developers without GPU access or working in privacy-sensitive environments, a model that runs locally at 1B parameters represents genuine accessibility.
The skepticism, however, lands hard on the 2048-token context window. Critics on Reddit argue this limitation confines the model to “toy problems” and prevents meaningful analysis of large codebases. One commenter noted that popular IDE extensions like Continue.dev won’t even function properly below 4K context, while another dismissed the constraint as a “joke” for serious coding tasks.
This criticism isn’t wrong, but it misses the point. Maincoder-1B isn’t trying to replace Claude 3.5 Sonnet for complex system design. It’s built for scenarios where latency and cost dominate: autocomplete suggestions, small function generation, test case creation, and search-based program synthesis where you need hundreds of cheap generations to explore a solution space. The model’s own documentation explicitly states it’s “best at small, self-contained tasks”, a refreshingly honest admission in an industry addicted to overpromising.
Where Small Models Actually Win
The real controversy isn’t whether Maincoder-1B can write your entire microservices architecture, it can’t. The controversy is that we’ve built an entire ecosystem assuming massive models are necessary for any useful coding assistance. Maincode’s release note articulates four scenarios where small models dominate:
- Interactive tools requiring sub-100ms response times
- Local/offline coding on laptops or constrained hardware
- Batch transformations where you process thousands of files cost-effectively
- Search-based synthesis generating hundreds of candidates for verification loops
Consider a continuous integration pipeline that automatically generates test cases for every function in a repository. Running GPT-4 for this would bankrupt most startups. A 1B model that achieves 70%+ correctness at near-zero marginal cost? That’s a business model enabler.
The model’s Apache 2.0 license further amplifies its impact. Unlike gated models requiring API keys and sending your code to external servers, Maincoder-1B can be embedded directly into developer tools, fine-tuned on proprietary codebases, and deployed without license anxiety. This isn’t just a technical achievement, it’s a strategic weapon for companies wanting AI-assisted development without vendor lock-in.
The Coming Efficiency Wars
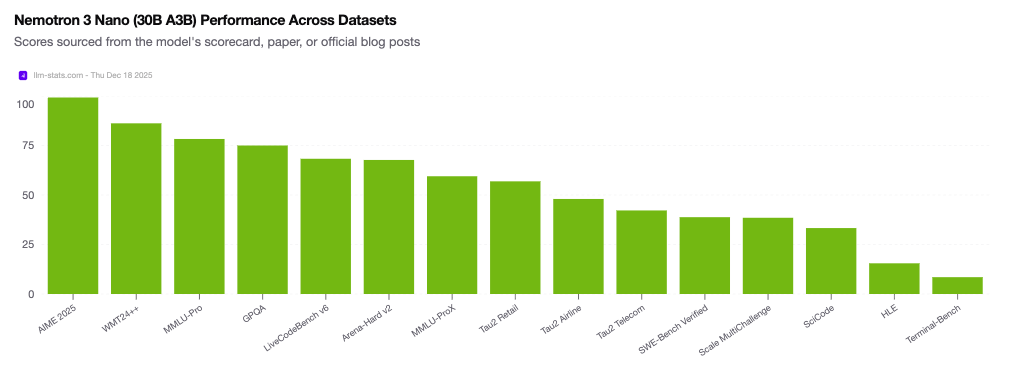
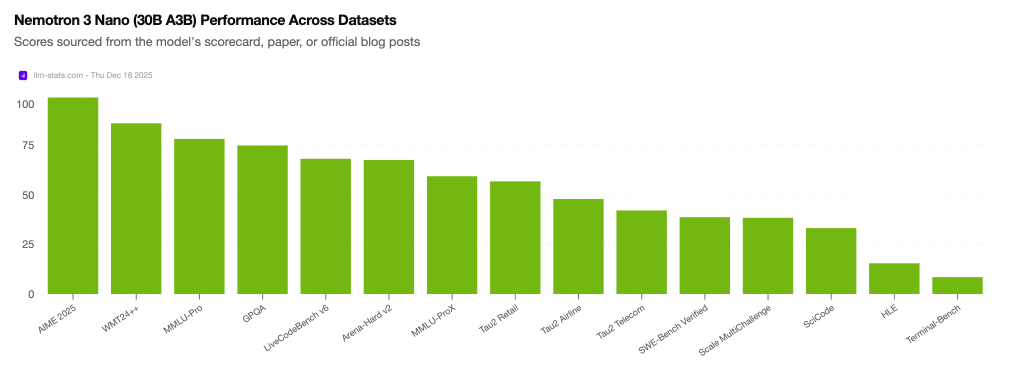
Maincoder-1B arrives at an inflection point. NVIDIA’s recent Nemotron 3 Nano launch, another efficiency-focused model, shows industry giants are also reading the tea leaves. The Nemotron release emphasizes “controllability” and “cost predictability”, marketing speak for “we know you can’t afford to run massive models at scale.”
The performance comparison table reveals an inconvenient truth: we’ve been leaving massive efficiency gains on the table. When a 1B model can outperform 3B competitors by 40+ percentage points, it suggests that training methodology, data quality, and post-training optimization matter far more than raw capacity. The scaling laws aren’t broken, they were just misinterpreted as permission to be lazy about everything else.
This creates a new competitive axis. Startups that master efficient training can punch far above their weight class, delivering specialized models that outperform generalist behemoths on specific tasks. The moat isn’t compute access anymore, it’s algorithmic ingenuity and domain-specific data curation.
The Hard Tradeoffs
Let’s be blunt about limitations. The 2K context window means Maincoder-1B can’t:
– Analyze multi-file dependencies
– Refactor across large codebases
– Understand complex project structures
– Maintain coherence over long interactions
The model also lacks safety tuning, explicitly warning users about potential for biased or unsafe outputs. This is a research tool, not a production copilot ready for unsupervised deployment.
But these constraints are features, not bugs, for the target use case. They’re the price of admission for a model that runs on a laptop CPU at reasonable speed. The question isn’t whether Maincoder-1B replaces GPT-4, it’s whether we’ve been overpaying for capabilities we rarely use.
The Reckoning
Maincoder-1B’s 76% HumanEval score should trigger a strategic recalculation across the AI landscape. For years, the default answer to “how do we improve performance?” was “add more parameters.” That path leads to concentration of power among a few well-funded labs, environmental concerns over massive compute, and products that are too slow and expensive for many real applications.
The insurrection represented by efficient small models suggests a different future: specialized, deployable, and democratic. One where a team of five engineers can train a state-of-the-art model for their niche. Where latency-sensitive applications aren’t locked out of AI benefits. Where the barrier to entry isn’t a billion-dollar compute budget but architectural creativity.
The scaling cult won’t collapse overnight. There will always be problems that demand massive models. But Maincoder-1B proves that for a huge class of practical coding tasks, we’ve been massively overspec’d. The companies that thrive in the next phase won’t be the ones with the biggest clusters, they’ll be the ones that deliver the right capabilities at the right cost, right where developers need them.
The parameter arms race isn’t over. It’s just no longer the only game in town.