None of that matches what senior engineers using the model are actually reporting.
A distinguished engineer at a hyperscaler, someone who builds the infrastructure that hosts these models, recently went on record with a damning assessment: after extensive testing, they couldn’t tell Fable 5 apart from Opus 4.6, 4.7, or 4.8 in a blind test. The “revolutionary” new model mostly felt like more of the same.
Here’s the uncomfortable truth about where frontier AI actually stands for software engineering.
The Blind Test Nobody Wants to Talk About
“I’ve been having a go at it. Thus far, I wouldn’t be able to tell if you did a blind test which model I was using”, the engineer wrote on Reddit. “If you had put Opus 4.6, 4.7, 4.8 and Fable in my Claude Code setup, based on the work I do and how I work, I wouldn’t be able to tell which is which.”
This isn’t a random developer complaining. This is a distinguished engineer at one of the largest cloud providers on earth, working directly in the AI space. When someone at that level says the emperor has no clothes, it’s worth listening.
The reasoning is straightforward and cuts to the heart of how professional software engineering actually works:
Professional engineers don’t one-shot entire projects.
They work in small, iterative chunks. They test each abstraction before moving to the next. They need to understand every component inside and out. And this workflow means that models have already plateaued in value for the actual day-to-day work of engineering.
Why Benchmarks Don’t Translate to Real Engineering
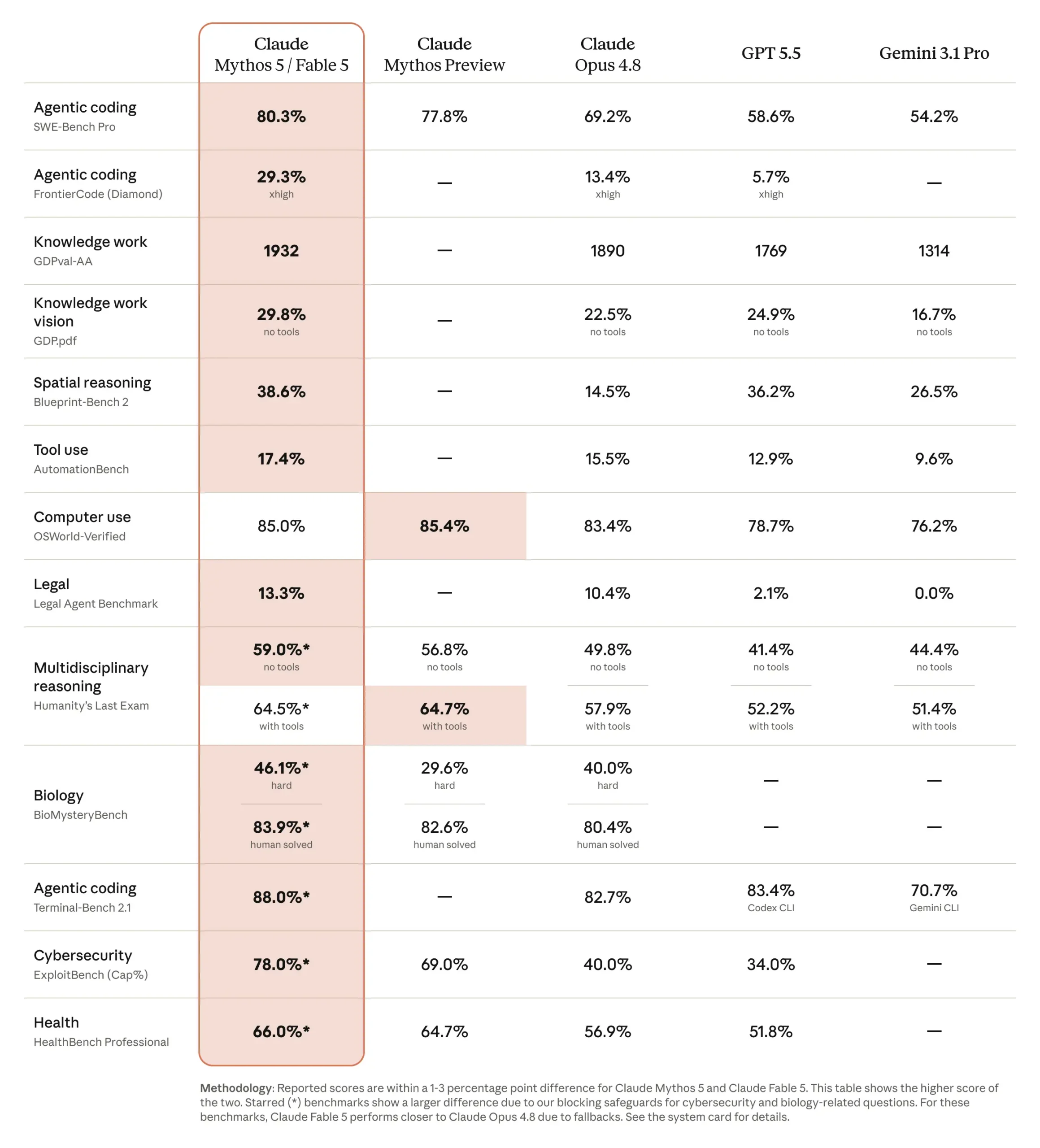
The gap between benchmark performance and real-world utility has never been wider. Fable 5 crushes FrontierCode Diamond at 29.3%, but that number is still failing nearly three-quarters of the time on hard coding tasks. Stripe’s impressive “months compressed into days” story? It’s a code migration, not novel engineering.
Here’s what the benchmarks actually mean in practice:
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 | Real-World Significance |
|---|---|---|---|---|
| SWE-bench Verified | 95% | 88.6% | , | Solves known, pre-screened bugs |
| SWE-bench Pro | 80.3% | 69.2% | 58.6% | Multi-file changes in maintained repos |
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% | Real OSS patches, autonomous |
| Code-summary honesty | 4.6% dishonest | 3.7% | , | Reliability of self-reports |
The problem is that even at 80% on SWE-bench Pro, the model is failing 20% of the time on well-defined, isolated tasks. And the hardest benchmark, FrontierCode Diamond, which most closely resembles real production work, shows Fable 5 still failing 70% of the time.
The engineer’s anecdotal evidence tracks with this: “Fable got the AWS ALB/ECS draining behavior completely wrong, and confidently so. The only reason I was able to catch it is that I was already familiar with how those two pieces work together.”
This is the fundamental issue. Every improvement in raw capability is offset by the fact that you still have to verify everything the model produces.
The Information Compression Problem
One of the most insightful comments from the thread came from the same engineer, explaining why bigger models don’t translate to bigger wins for iterative work:
“The way I look at it is that information has a compression limit… When engineering a large system, we break it down into smaller components. The goal with LLM usage is to get the components to be small enough where the prompt can, with high probability, be expanded into that component based on my expectations. Otherwise, the information in the prompt isn’t high enough to expand outward to a whole system.”
This is a crucial insight. There’s a fundamental limit to how much you can compress a full system specification into a prompt. If the prompt doesn’t contain enough information to perfectly specify the desired output, the model will hallucinate (infer missing context) and produce something wrong.
The more capable model doesn’t solve this problem. It just gets more creative about its hallucinations.
The “Copied from the Internet” Ceiling
There’s another structural limitation at play. As the engineer noted, “models have had access to the Internet’s wide suite of information such as API docs, best practices, etc for a while, which added ‘intelligence’ of a certain flavor to the models outputs.”
We’ve effectively exhausted the public training data that’s useful for general software engineering. The low-hanging fruit, common patterns, documented APIs, standard implementations, have already been absorbed. Further improvements would require genuinely novel reasoning about edge cases, undocumented behaviors, and system interactions that aren’t captured in any training corpus.
This is why Fable 5 still confidently hallucinates about ALB/ECS draining behavior. The documentation might describe the happy path, but the model’s training data didn’t adequately cover the edge case.
The Economic Reality Check
If you needed another reason to question the frontier model narrative, look at the pricing. Claude Fable 5 costs $10/$50 per million tokens, double Opus 4.8’s $5/$25. And there’s an even more revealing detail in Anthropic’s rollout plan:
June 9, 22: Included on Pro/Max/Team at no extra cost
June 23: Pulled from plans, switches to usage credits
Later: Restored as standard “when capacity allows”
Translation: Frontier models are so expensive to serve that they can’t even bundle them into subscriptions. As one Reddit commenter put it, the subsidies were “just a Ponzi scheme.”
This creates a brutal math problem. If Fable 5 costs twice as much per token but delivers marginal improvements for iterative work, the ROI calculus quickly falls apart. You’re paying a premium for benchmark wins that don’t translate to your actual workflow.
The broader economic reality driving questions about reinvesting into model improvements suggests the current funding model for frontier AI may be unsustainable. If the models aren’t delivering proportional value increases, something has to give.
Where the Value Actually Lives
None of this means LLMs are useless for software engineering. The engineer was explicit: “I can almost do this today with local Gemma 4 models.”
The value is in the iterative, conversational workflow, not in one-shotting entire systems. The best use case for these models remains the same as it was six months ago: generating small, well-defined code chunks under close human supervision.
This is also where the cost-benefit analysis actually works. Running a local model on a 128GB MacBook Pro might provide 90% of the value of Claude for software engineering. The engineer predicted exactly this: “by this time next year, I believe there will be local models you can run on a 128GB MacBook Pro that will provide 90% of the value Claude adds to my software engineering work today.”
As practical limitations of current models get addressed through protocol improvements, the bottleneck shifts from raw model capability to workflow integration. The models that win won’t be the ones with the highest benchmark scores, they’ll be the ones that fit best into how engineers actually work.
The Plateau Is Real, And That’s Okay
The industry narrative has been relentless: each new model is exponentially better than the last. The benchmarks prove it! But benchmarks are tests that models can train for. Real engineering is a fundamentally different game.
The distinguished engineer’s conclusion is worth sitting with: “We’re hitting an asymptotic limit here. I’m not getting more value from every model release anymore, and the way I work isn’t changing.”
This doesn’t mean AI is dead for software engineering. It means the low-hanging fruit has been picked. The remaining gains will come from better integration, better workflows, and better understanding of when and how to use these tools, not from another order-of-magnitude scaling of compute.
The massive compute required by frontier models simply doesn’t justify the marginal gains for professional engineers working iteratively. The foundational model behavior that drives these improvements has structural limits that no amount of training data can overcome.
The best engineers will continue to use AI as a powerful junior assistant, not as an autonomous senior engineer. And that’s fine. The question is whether the market can sustain the current level of investment in frontier models when the returns for practical engineering work are plateauing so clearly.