ByteDance’s Lance is a 3 billion active parameter unified multimodal model that handles image and video understanding, generation, and editing inside a single framework. Trained entirely from scratch on a budget of just 128 A100 GPUs, it matches or exceeds the performance of 7 billion parameter rivals across multiple benchmarks. Released under Apache 2.0, Lance arrives with a technical caveat, the full model weights push 40GB VRAM requirements, but also with a clear message: the multimodal arms race isn’t just for companies with nuclear-reactor training budgets.
The 128-GPU Rebellion Against Scale Obsession
While the rest of the industry treats multimodal AI like a parameter arms race, 20B here, 30B there, and closed APIs everywhere, ByteDance dropped Lance with a training budget of no more than 128 A100 GPUs. That’s not a typo. One hundred twenty-eight.
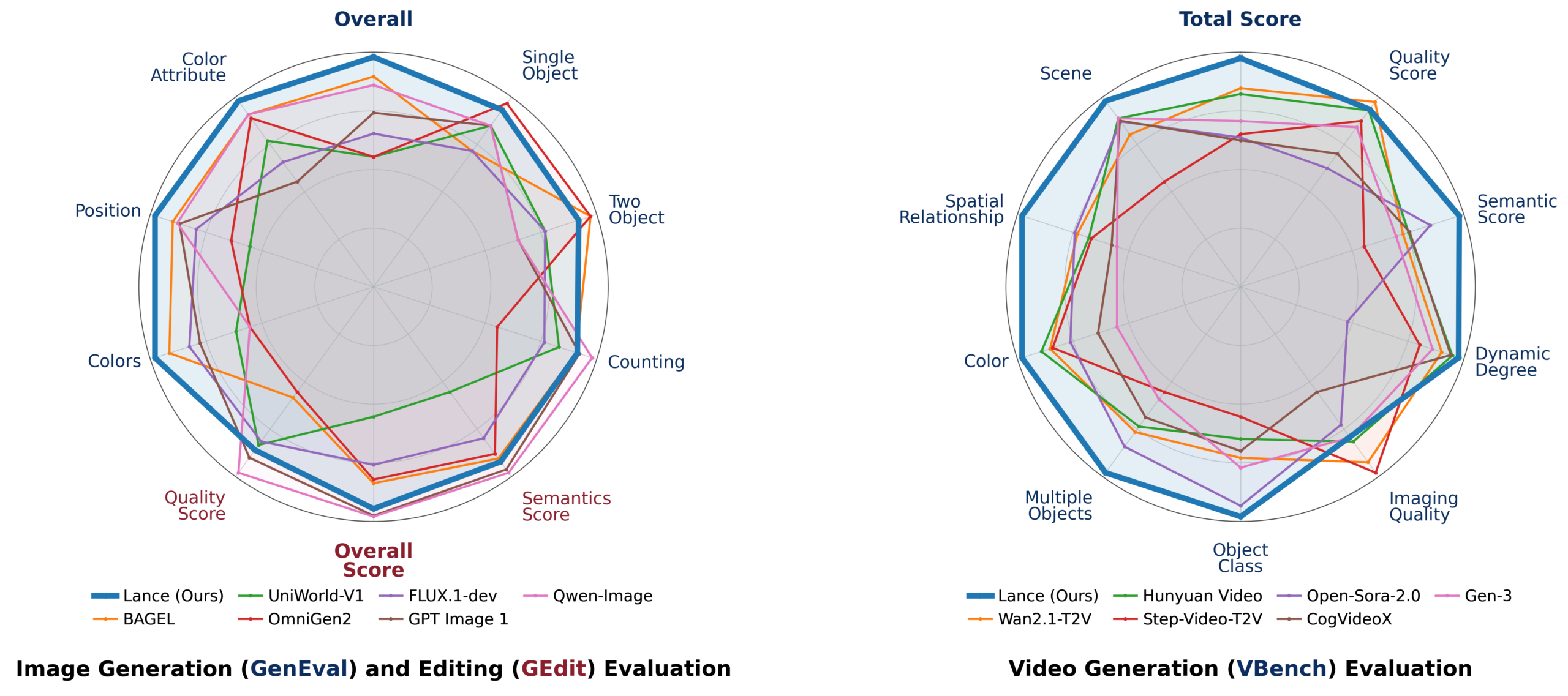
To put that in perspective, many foundational video models are trained on clusters that make your AWS bill weep. Lance didn’t just scrape by, either. On the VBench video generation benchmark, Lance scores 85.11, edging out TUNA-1.5B (84.06), Show-o2 (81.34), and even the 14B Wan2.1-T2V (83.69). In the GenEval image generation suite, Lance ties the 7B TUNA model at 0.90 overall while beating it on color accuracy (0.97 vs. 0.91) and object counting (0.84 vs. 0.81).
If you’re keeping score at home, that’s a 3B active-parameter model hanging with and sometimes surpassing 7B competitors. The Hugging Face model card lays out the evidence plainly, and the benchmark overview tells the story at a glance:
The “3B Active” Fine Print That Actually Matters
Headlines calling Lance a “3B model” are technically wrong in the way that matters for your GPU. The safetensors files for Lance_3B and Lance_3B_Video weigh in at roughly 24.7GB and 28.4GB respectively in bf16. Community analysis of the weights suggests the full parameter count sits closer to 12 billion for image generation and 14 billion for video, with a roughly 670-million-parameter vision encoder layered on top. “3B active” refers to the parameters activated during forward passes, not the total memory footprint.
This distinction has already sparked debate among developers eyeing local inference. ByteDance’s official stance is unambiguous: you need at least 40GB of VRAM to run the thing. For context, that’s an A100 or H100, or maybe a rented H200 if you’re feeling fancy. The conversation around compute and GPU requirements for running advanced AI models locally just got another complicated entry.
That said, quantization efforts are already circulating in developer forums. If the weights can be pushed to fp8, q8, or even q4, the local inference picture changes dramatically. But out of the box? Don’t expect to fire this up on a consumer GPU without some serious offloading gymnastics.
What “Trained From Scratch” Actually Means
Lance isn’t a fine-tuned Qwen2.5-VL with a flashy marketing wrapper, though it does reuse parts of that architecture. According to the paper on arxiv and the official GitHub repository, the team built Lance with a staged multi-task recipe, separating semantic understanding and visual generation through dedicated experts while keeping a shared interleaved sequence for text, image, and video context.
The architecture combines semantic ViT tokens for understanding, clean and noisy VAE latents for generation, generalized 3D causal attention, and MaPE to reduce positional interference among heterogeneous visual tokens. In less buzzword-heavy terms: Lance handles comprehension and creation inside the same model family without forcing everything through a single overloaded pathway.
Acknowledgements in the repo also tip the hat to BAGEL and WAN 2.2, and the vLLM-omni community is already dissecting integration challenges. One early analysis confirmed that Lance uses WAN 2.2’s VAE directly but replaces the diffusion backbone with a Qwen2 LLM approach, packing text tokens, ViT tokens, and VAE latents into one unified causal sequence using flex_attention and block masking rather than WAN-style self-attention.
Benchmarks That Hurt Bigger Models
Let’s stop talking about vibe checks and look at the tables. On DPG-Bench, designed to stress complex prompt following across global composition, entity accuracy, attribute binding, and relation grounding, Lance posts an overall score of 84.67. That’s within striking distance of TUNA-7B’s 86.76, and Lance actually wins on relation grounding with a 93.38 score that tops TUNA-7B (91.87) and even approaches Qwen-Image’s 20B mass (94.31).
On GEdit-Bench, which evaluates instruction-guided edits like background swaps, color changes, and subject replacement, Lance delivers a 7.30 average, the best among listed unified models, and competitive with GPT Image 1’s 7.49 and Qwen-Image-Edit 20B’s 8.01.
| Task | Lance (3B) | Best Unified Competitor |
|---|---|---|
| GenEval Overall | 0.90 | 0.90 (TUNA 7B) |
| DPG-Bench Overall | 84.67 | 86.76 (TUNA 7B) |
| GEdit-Bench Avg | 7.30 | 6.88 (InternVL-U w/ CoT 1.7B) |
| VBench Total | 85.11 | 84.06 (TUNA 1.5B) |
| MVBench Avg | 62.0 | 67.0 (Qwen2.5-VL 3B) |
The MVBench result is Lance’s most visible bruise: its 62.0 average trails Qwen2.5-VL-3B’s 67.0, suggesting that while Lance is a capable jack-of-all-trades, pure understanding tasks still favor specialized backbones. But against other unified 7B models like Show-o2 (55.7), Lance holds its ground. Efficient multimodal architectures challenging the big-model paradigm are proving that density often beats scale, and Lance is the latest evidence.
Glimpses of Generation Capability
Lance handles six distinct task modes through a unified CLI: text-to-image (t2i), text-to-video (t2v), image editing (image_edit), video editing (video_edit), image understanding (x2t_image), and video understanding (x2t_video). The repository includes ready-to-run scripts for each.
For text-to-video generation at 480p across 121 frames:
bash inference_lance.sh \
--TASK_NAME t2v \
--MODEL_PATH downloads/Lance_3B_Video \
--RESOLUTION video_480p \
--NUM_FRAMES 121 \
--VIDEO_HEIGHT 480 \
--VIDEO_WIDTH 848 \
--SAVE_PATH_GEN results/t2v_121f
For image generation at 768×768:
bash inference_lance.sh \
--TASK_NAME t2i \
--MODEL_PATH downloads/Lance_3B \
--RESOLUTION image_768res \
--VIDEO_HEIGHT 768 \
--VIDEO_WIDTH 768 \
--SAVE_PATH_GEN results/t2i
Generation parameters follow a flow-matching schedule with a default timestep shift of 3.5, 30 denoising steps, and a CFG text scale of 4.0. You can push steps to 50 for marginal quality gains if your patience (and GPU hours) allow.
| Parameter | Default | Purpose |
|---|---|---|
VALIDATION_NUM_TIMESTEPS |
30 | Denoising steps |
VALIDATION_TIMESTEP_SHIFT |
3.5 | Flow matching schedule shift |
CFG_TEXT_SCALE |
4.0 | Classifier-Free Guidance scale |
NUM_FRAMES |
50 | Video length (max 121) |
RESOLUTION |
video_480p |
Spatial preset |
The text-to-image outputs cover photorealistic, stylized, and compositional prompts. Image editing handles instruction-guided modifications, local replacements, style transfers, and layout-preserving transformations, without requiring inpainting masks or ControlNet scaffolding.

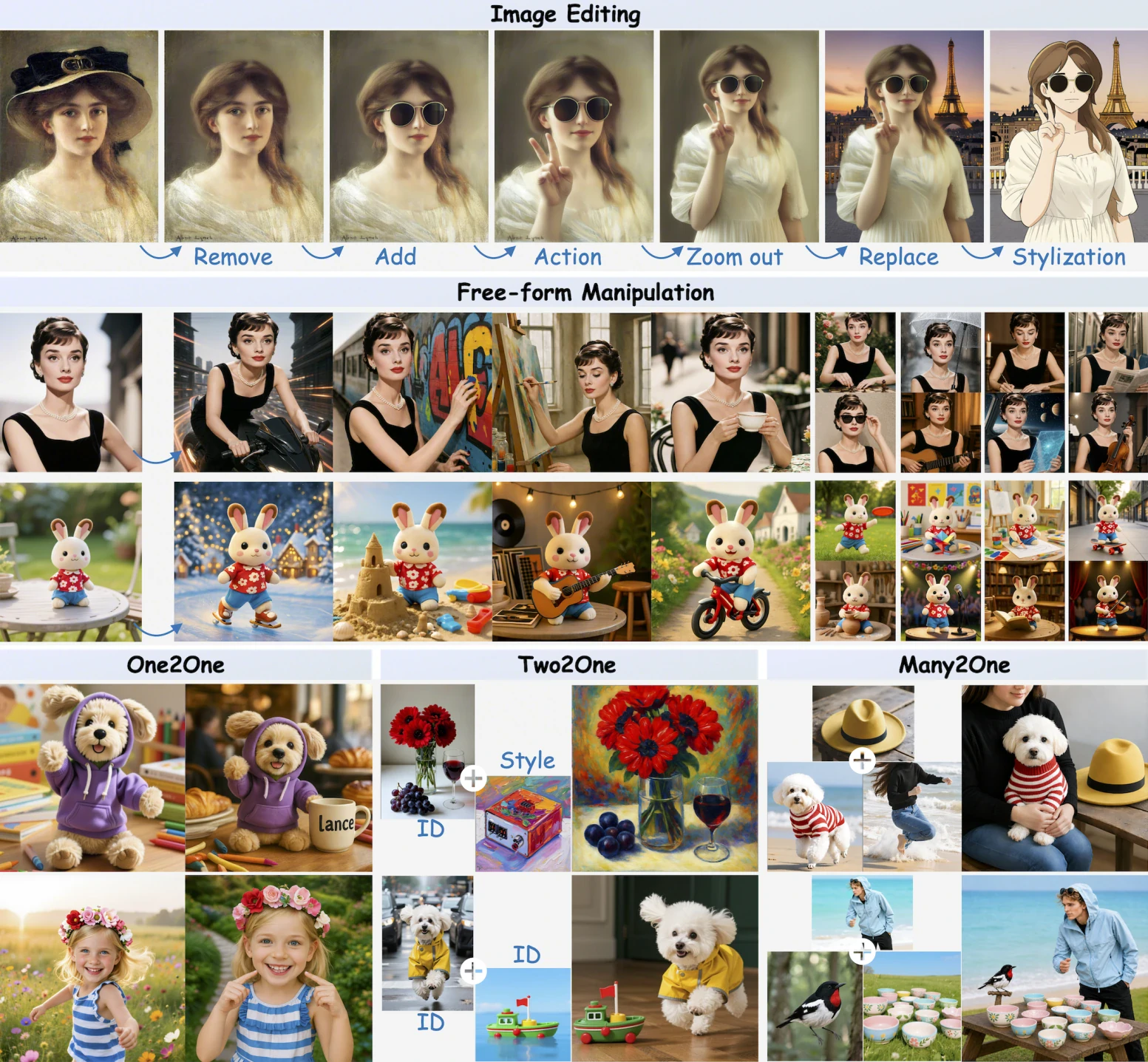
Video editing demos include background swaps, subject replacement, appearance restyling, and action edits. The multi-turn consistency editing case is particularly notable: Lance can chain sequential edits on the same subject without forgetting what the subject looks like, a task that trips up many larger diffusion pipelines.

Apache 2.0 and the Missing Interface
Technical benchmarks get the Retweets, but licensing gets the POs. Lance ships under Apache 2.0, which means commercial use, modification, and redistribution are all on the table without negotiating enterprise agreements. As noted in Startup Fortune’s coverage, that’s a genuine differentiator in a space crowded with research releases that are legally radioactive for product teams.
For startups building ad-creation tools, visual search, short-form video pipelines, or product mockup generators, Lance represents something rarer than a new SOTA: it’s a multimodal model you can actually ship. Small language models challenging the assumption that massive scale is needed for capability have already started shifting the narrative, Lance extends that logic into pixels and frames.
Of course, permissive licensing doesn’t erase responsibility. Content moderation, copyright risk, bias, and failure modes still sit squarely on the deployer’s shoulders.
If there’s one criticism echoing across early adopters, it’s that the included Gradio demo feels like an afterthought. The repository ships a lance_gradio_t2v_v2t.py script that covers basic text-to-video and video-to-text, but the deeper generation, editing, and multi-turn workflows are CLI-only. For a model capable of sophisticated image editing and intelligent video generation, the default UI barely scratches the surface. Serious builders won’t care, they’ll prefer the unified script anyway, but the gap between capability and accessibility is real.
The Builder’s Verdict
Lance is not a magic wand. It won’t turn your laptop into a Pixar studio, and it isn’t going to beat closed frontier models on every dimension. What it does prove is that multimodal AI, actual, functional, many-task multimodal AI, doesn’t require a 10,000-GPU cluster or a billion-parameter behemoth.
For technical leaders, the takeaways are concrete:
- Efficiency is becoming table stakes. If a 3B active model can tie 7B rivals on GenEval and win VBench, your model selection criteria should weigh density, not just scale.
- Unified frameworks reduce pipeline complexity. One model handling
t2i,t2v,image_edit,video_edit, and VQA means fewer integration points, fewer version mismatches, and less infrastructure sprawl. - Check your VRAM budget. At 40GB minimum and nearly 30GB of model weights, Lance is still a datacenter GPU proposition unless quantization matures.
- Watch the ecosystem. vLLM integration and community quantization efforts will determine whether Lance becomes a practical workhorse or a benchmark curiosity.
ByteDance Lance didn’t arrive with a trillion parameters and a keynote stage. It arrived with 128 GPUs, a very specific technical bet, and a project page full of evidence that the multimodal playbook is being rewritten. That might be more disruptive than any parameter record.