
The 1.8M-Parameter Language Model That Questions Everything We Know About Scale
The AI industry is drunk on scale. While OpenAI, Anthropic, and Google race toward trillion-parameter models that require nuclear reactors to train, one developer quietly built a functional language model that fits in an email attachment. Strawberry, a 1.8-million-parameter model trained from scratch, delivers coherent text generation across diverse domains while consuming less memory than a smartphone photo. The kicker? It was trained on a single GPU, uses a custom architecture that generates attention weights on the fly, and its entire codebase could be reviewed over coffee.
This isn’t another “small models are efficient” puff piece. This is about what happens when you stop copying GPT architectures and start questioning every assumption about what makes language models work.
The Retention Mechanism: Attention Weights That Write Themselves
Most LLMs treat attention weights as sacred parameters to be learned, frozen, and worshipped. Strawberry’s core innovation, the “Retention Mechanism”, treats them as disposable calculations, generated in real-time based on input context. The model maintains three trainable linear layers (original, adjust, and transform) that dynamically produce QKV, SwiGLU, and output projection weights for each attention pass.
The update rule reads like something from a physics simulation rather than a neural network:
# update QKV, Swiglu and output projection weights
w_qkv = wT[0] * F.silu(wC[0]) + wC[0]
w_swiglu = wT[1] * F.silu(wC[1]) + wC[1]
w_out = wT[2] * F.silu(wC[2]) + wC[2]
# normalize and swap
wT, wC = wC, (w_qkv, w_swiglu, w_out)This approach decouples model depth from parameter count. You can stack attention layers without bloating the model because each layer’s weights are synthesized on demand. It’s a middle finger to the parameter-counting contest that defines modern AI marketing.
The architecture combines two attention mechanisms: Apple’s Attention-Free Transformer for global context and standard MHA for local patterns. The author dubs the MHA variant “The Expert Abundance”, hinting at future plans for a mixture-of-attention-experts approach where each expert handles different context windows. For a 1.8M-parameter model, that’s ambition bordering on hubris.
Data Curation as Architecture
Here’s where the story gets spicy. While the industry shovels petabytes of web-crawled slop into ever-larger models, Strawberry’s creator manually scraped and cleaned ~30 million characters of text. The dataset reads like a fever dream: Wikipedia articles, GTA and Red Dead Redemption fandoms, Cyberpunk 2077 scripts, YouTube transcripts, and code from personal repositories and the Hazel Game Engine.
This isn’t random hoarding, it’s strategic domain coverage. The model learns formal prose from Wikipedia, narrative structure from game dialogues, technical precision from code, and conversational patterns from transcripts. A custom tokenizer trained on this specific distribution compresses the 30M characters into 9M tokens, achieving a 3.3x compression ratio that reflects the dataset’s linguistic coherence.
The training configuration reveals the obsession with quality over quantity:
{
"vocab_size": 8192,
"block_size": 256,
"n_layer": 2,
"n_head": 6,
"n_embd": 96,
"batch_size": 16,
"max_iters": 10000
}Ten thousand steps on a batch size of 16×256 tokens means the model saw 40 million tokens total, barely a rounding error compared to the trillions used to train GPT-4. Yet it achieved a final training loss of 3.5 and validation loss of 3.8, putting it in the same ballpark as early GPT-2 variants.
This validates what small reasoning models outperforming larger counterparts have demonstrated: when data is curated for density and diversity, scale becomes secondary. Falcon H1R 7B embarrassed giants by focusing on reasoning patterns rather than raw memorization. Strawberry takes this philosophy to its logical extreme.
The Training Reality Check
Let’s talk constraints. The model was trained on a single GPU (likely a consumer card), with gradient accumulation steps of 1 and a learning rate that decayed from 0.002 to 0.0002 over 10,000 steps. No fancy distributed training, no thousand-dollar cloud bills, just a persistent developer iterating in their spare time.
The training chart for a zero-dropout run (shown below) reveals something fascinating: even without dropout, the model experiences loss spikes around steps 4,200, 13,000, and 23,000. These aren’t failures, they’re gradient explosions that the model recovers from, suggesting the dynamic weight generation creates instability but also adaptability.
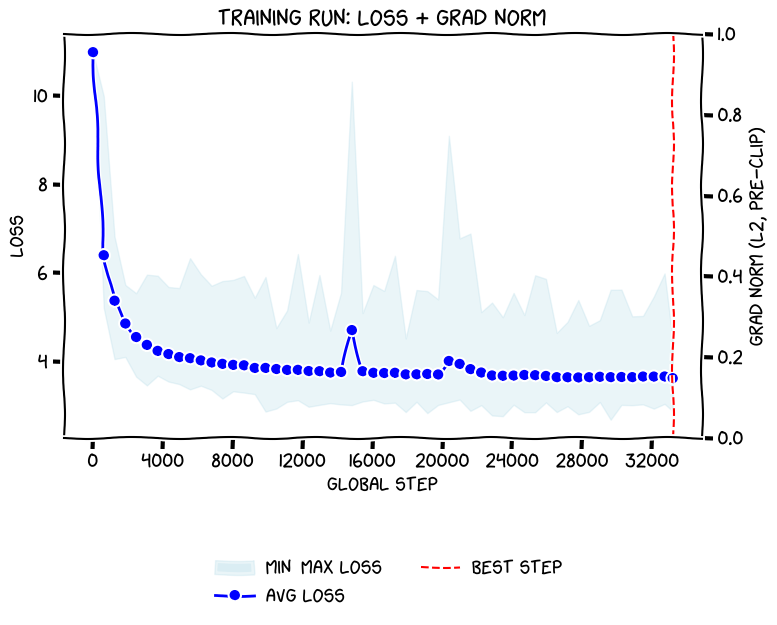
Giles Thomas’s experiments with dropout removal on larger models showed a 0.051 loss improvement, confirming what Strawberry’s creator discovered: when each token is seen only once during single-epoch training, dropout’s regularization effect becomes dead weight. The model’s 3.8 validation loss without any fancy stabilization tricks is a middle finger to conventional training wisdom.
Why 25MB Matters
The final model weighs 25MB on disk. That’s smaller than most JavaScript frameworks. It loads instantly, runs on CPUs without breaking a sweat, and could theoretically execute inside a browser’s memory sandbox. This isn’t just academic, it’s a blueprint for tiny multimodal foundation models with optimized performance that can run on devices where cloud connectivity is a liability.
Consider the implications. While Liquid AI promises billion-parameter models that “fit in your pocket”, Strawberry actually delivers sub-100MB performance that runs on a Raspberry Pi. The gap between marketing and reality in the tiny model space is vast, but projects like this bridge it with working code.
The Controversial Take: Scale Is a Lazy Shortcut
Here’s what makes this project genuinely subversive: it implies that much of the AI industry’s scaling obsession is a cargo cult. Instead of inventing better architectures, we’ve been compensating with brute force. The Retention Mechanism suggests that dynamic computation, generating weights on the fly, could be more efficient than static memorization.
This aligns with NVIDIA’s argument for small models in agentic AI. Their research indicates that agents need fast, cheap inference more than they need encyclopedic knowledge. A 25MB model that can execute a reasoning step in milliseconds is more valuable for tool use and multi-step planning than a 175B behemoth that costs dollars per query.
The data curation strategy also challenges the “more data is better” mantra. The raw, uncurated training data versus curated datasets debate shows that purity isn’t always optimal, sometimes chaotic, diverse data produces more robust models. Strawberry’s manually curated dataset sits at the opposite extreme: obsessively cleaned, domain-specific, and intentionally limited to four programming languages. Both approaches work because they reject the middle-ground slop that fuels most large models.
Practical Lessons for Developers
- Start with architecture, not parameters. The Retention Mechanism’s dynamic weight generation is the kind of innovation that matters more than adding layers. Ask yourself: what can I compute instead of memorize?
- Curate like your life depends on it. The 30M characters didn’t scrape themselves. Manual cleaning ensured no HTML artifacts, consistent formatting, and domain balance. This is efficiency-focused LLMs challenging the parameter-scaling norm taken to its logical conclusion.
- Embrace small-batch, high-step training. 16×256 tokens per batch is tiny by modern standards, but 10,000 steps provided sufficient coverage. This runs counter to the “batch size must be huge” wisdom and makes consumer-GPU training feasible.
- Validate with real tasks. The creator tested generation quality manually, focusing on coherence and domain relevance rather than chasing benchmark numbers. This is the same approach that lets small specialized models surpassing giant LLMs in specific tasks dominate their niches.
- Open-source your failures. The GitHub repo shows 45 commits, indicating messy iteration. The community’s response, 28 stars, 6 forks, proves that practical experiments resonate more than polished but theoretical papers.
The Future Belongs to the Obsessive
Strawberry won’t replace GPT-4. It can’t write production code or parse legal documents. But that’s not the point. It proves that a single developer with a clear architectural vision and maniacal data curation can build something that would have been state-of-the-art in 2019.
This is the same energy that drives open-source lightweight agents outperforming corporate behemoths. Three weeks after releasing mobile-use, its creators leapfrogged DeepMind and Microsoft on AndroidWorld, not with scale, but with surgical precision in task execution.
The AI industry’s narrative is shifting. The question is no longer “how big can we make it?” but “how small can we make it while keeping it useful?” Strawberry’s 1.8M parameters and 25MB footprint set a new baseline for what’s possible when you replace scale with smarts.
The code is public. The dataset is documented. The architecture is explained in detail. What matters now is whether the community will treat this as a curiosity or a blueprint. My money’s on the latter, because in a world where compute costs are measured in millions, the developer who can squeeze GPT-2 quality into a model that runs on a toaster isn’t just efficient. They’re dangerous.

