
The arms race for bigger, more powerful AI models has settled into a predictable rhythm: announce a new parameter record, showcase dazzling but narrow benchmarks, and watch as the community groans under the weight of the serving bill. It’s a broken model, where capability is directly shackled to cost. AIDC-AI’s Ovis2.6-80B-A3B proposes a different path. It’s not a bigger hammer, it’s a smarter toolbox. By upgrading its backbone to a Mixture-of-Experts architecture, it scales to 80 billion total parameters while activating only about 3 billion during inference. This isn’t just a technical footnote—it’s an economic blueprint for the future of multimodal AI. It moves the conversation from “can we build it?” to “can we afford to run it?”
The MoE Gambit: Trading Bulk for Specialization
The move from a dense transformer to a Mixture-of-Experts (MoE) backbone is the core architectural shift. Traditional 80B-parameter models require running the entire 80-billion-parameter network for every single token—a massive computational tax. MoE models like Ovis2.6 break that monolithic network into smaller, specialized “experts.” For any given input, a routing mechanism activates only a small subset of these experts, in this case, reportedly around 3 billion active parameters per inference, while the rest remain dormant.
This is where the “fraction of the serving cost” promise becomes tangible. The computational FLOPs and, critically, the memory bandwidth required are drastically reduced compared to a dense 80B model. Research like that presented in the EnergyLens paper confirms this fundamental advantage: energy consumption doesn’t scale linearly with parameter count but is governed by active compute and data movement. By activating only a fraction of its total parameters, Ovis2.6 directly targets these two key cost drivers. This represents a more mature, economically sustainable form of architectural specialization, proving that raw size is no longer the sole proxy for capability.
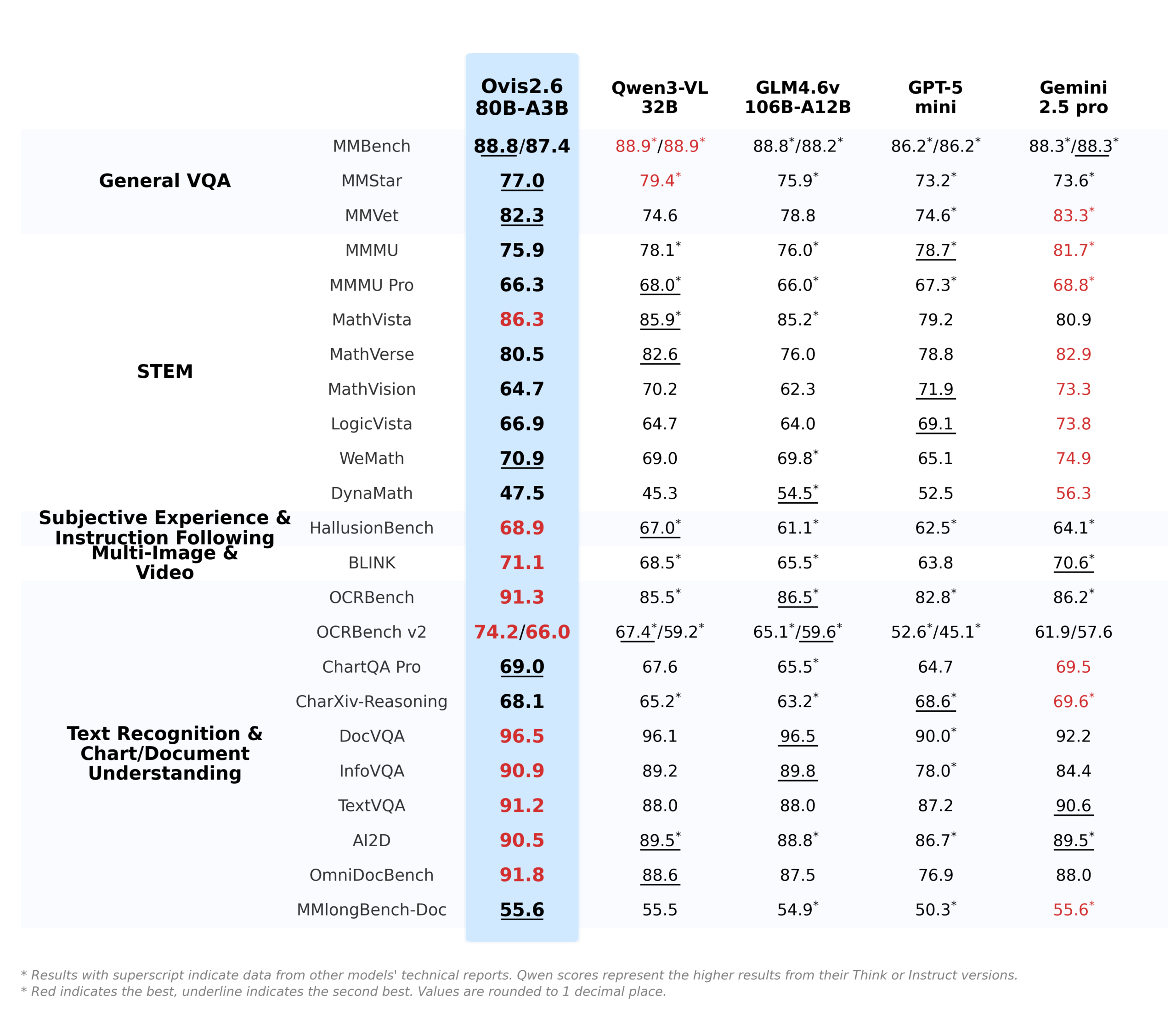
Beyond Efficiency: Capabilities That Demand Attention
Of course, efficiency without capability is a party trick. Ovis2.6 isn’t just a leaner model—it packs upgrades that make it a formidable tool for practical, complex tasks.
Expanded Context and Resolution
It supports a 64K token context and image resolutions up to 2880×2880. This is engineered for real-world document and diagram analysis, where answers are scattered across multi-page PDFs or dense, high-resolution charts.
Think with Image
This feature transforms visual data from a static input into an active workspace. The model can invoke tools (like cropping and rotation) during its Chain-of-Thought reasoning to re-examine image regions. Imagine asking it, “Is the signature in the bottom right corner of this scanned contract legible?” and the model zooming in mentally to check.
Reinforced OCR and Chart Understanding
The focus on “information-dense” tasks is explicit. It’s not just about describing a pie chart—it’s about extracting the data, understanding the relationships, and reasoning about the implications.
These features position it squarely against other vision-language models like Qwen-VL. While casual discussion often links AIDC-AI’s work to Qwen, Ovis2.6’s specific blend of MoE efficiency and high-resolution, tool-using reasoning charts its own course.
The Serving Cost Calculus: Where MoE Makes Its Money
The theoretical efficiency of MoE is one thing—the real-world cost is another. Serving a model like Ovis2.6-80B-A3B is a complex equation involving parallelism strategies, batch sizes, and hardware choices. The EnergyLens research provides crucial insights here, revealing that latency and energy optima frequently diverge. A configuration that gives you the fastest response might not be the cheapest to run.
Ovis2.6’s ~3B active parameter footprint changes this calculus radically. It reduces the pressure to use aggressive tensor parallelism (TP), which, while lowering latency, can introduce costly all-reduce communication overhead. Pipeline parallelism (PP), which can be more energy-efficient by distributing memory load and allowing for GPU idle states, becomes a more viable option. In short, the model gives system architects more economical knobs to turn, a critical advantage in the race to deploy affordable, large-scale multimodal AI.
A Reality Check: The Trade-Offs and Challenges
- Routing Overhead: The gating network that selects experts adds computational cost. If routing is inefficient, you lose the gains from sparse activation.
- Memory vs. Compute: While active parameters are low, the entire 80B parameter model must still be loaded into GPU memory (or sharded across devices). This doesn’t reduce the high upfront VRAM requirement, it just makes the compute per token cheaper. The barrier to entry remains high.
- Training Difficulty: Training stable, balanced MoE models is notoriously harder than training dense transformers, with challenges like expert imbalance and routing collapse.
- Integration: The provided code snippet requires specific dependencies like
flash-attn==2.8.3and careful handling of the thinking budget for streaming, indicating this isn’t a plug-and-play replacement for all existing inference pipelines.
Furthermore, while the 64K context is impressive, some observers point out that for a “reasoning model”, this could still be a constraint for extremely long, multi-step analytical tasks, though it’s ample for most document-centric workflows. The move to MoE reflects a nuanced understanding of these trade-offs, an evolution from earlier, simpler strategies that might have been considered a Flawed MoE Strategy.
The Competitive Landscape: Redefining Value
Ovis2.6-80B-A3B enters a crowded market. But its value proposition is distinct. It’s not competing on being the absolute best-at-everything model—it’s competing on being the most capable model you can realistically deploy at scale for visual reasoning tasks.
Its primary competition isn’t just other open-source MLLMs, but the economics of cloud API calls. When a proprietary model charges per token for processing high-resolution images and long documents, the bill can spiral. An efficiently served, open-weight model like Ovis2.6 offers a path to cap those costs, offering a powerful tool for enterprises that need to process thousands of documents or images daily without bankrupting themselves on API fees. This is part of the same architectural revolution moving intelligence out of black-box cloud services and into controllable, specialized deployments.
A Pragmatic Step Toward Scalable Multimodal Intelligence
Ovis2.6-80B-A3B is a signal of maturity in AI development. The field is moving past the brute-force phase and into an era of intelligent, cost-aware architecture. By leveraging MoE, AIDC-AI has built a model that delivers high-end multimodal capabilities, long-context, high-resolution image analysis, active reasoning, without the traditionally associated high-end inference bill.
It won’t be the right tool for every job. The specialization in document and chart understanding, combined with the hardware requirements for serving an 80B-parameter model (even a sparse one), targets a specific user. But for that user—think financial analysis, legal document review, scientific paper digestion, or business intelligence dashboards—Ovis2.6 provides a compelling proposition: top-tier visual reasoning that doesn’t require a top-tier cloud budget.
And in the current AI climate, that might be the most impressive feat of all.

