
Auto-scaling is the opiate of modern infrastructure. It feels good, traffic spikes hit, instances multiply, pagers stay silent. But beneath that warm blanket of elasticity, something insidious happens: we stop caring about efficiency. Why optimize a query when you can just spin up three more pods? Why fix that memory leak when the Horizontal Pod Autoscaler (HPA) will spawn fresh instances to pick up the slack?
This isn’t a theoretical concern. In cloud-native circles, there’s growing anxiety that auto-scaling has become less of a performance strategy and more of an architectural pacifier, something that moves problems from the development queue to the operations budget without actually solving them.
The Jevons Paradox in the Cloud
In 1865, economist William Stanley Jevons observed that improvements in coal engine efficiency didn’t reduce coal consumption, they increased it. Cheaper, more efficient engines made coal attractive for new applications, expanding total demand. As he noted, “It is wholly a confusion of ideas to suppose that the economical use of fuels is equivalent to a diminished consumption.”
We’re replaying this paradox with compute. Auto-scaling makes inefficiency economically viable. When spinning up a new Azure VM costs pennies and requires zero human intervention, the incentive to write tight code evaporates. Your service sits at 20% CPU waiting on I/O during peak hours? Just add more instances. The efficiency gains of cloud automation haven’t led to leaner applications, they’ve led to bloated ones that simply expand to fill their containers.
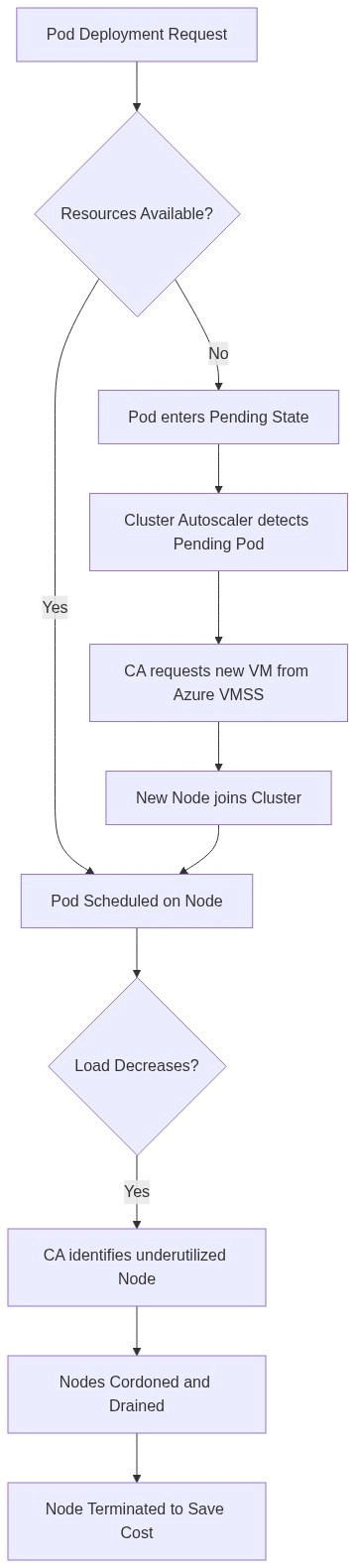
When “Scale Out” Becomes “Give Up”
The Kubernetes ecosystem exemplifies this tension. Modern platforms like Azure Kubernetes Service (AKS) offer sophisticated auto-scaling mechanisms: HPA for pod replication, VPA for resource right-sizing, Cluster Autoscaler for node provisioning, and KEDA for event-driven scaling down to zero. These are powerful tools when used strategically. But they’re also enablers.
Developer forums reveal a common pattern: teams encountering performance issues immediately reach for scale-out solutions rather than profiling their code. The logic is seductive, why spend days hunting through garbage collection logs when you can add a replicas: 10 to your deployment and call it resilience? This approach treats symptoms while the disease metastasizes. Silent database anti-patterns that undermine scaling efforts, like unindexed audit tables or N+1 queries, don’t disappear just because you’ve horizontally partitioned your application. They just cost more to run.
The prevailing sentiment among senior infrastructure engineers is that auto-scaling buys time but doesn’t buy solutions. It shifts the burden from development velocity to operational expenditure, often disguising the true cost of technical debt until the monthly cloud bill triggers an emergency budget review.
The Cost Accountability Gap
The critical failure mode isn’t technological, it’s organizational. When infrastructure teams own the scaling logic but don’t own the cloud bill, you create a moral hazard. Developers write inefficient code because “the platform will handle it”, while platform teams scale infinitely because “the application requires it.”
The fix is brutally simple: attribute every compute cycle to the team consuming it. When developers see their microservice burning $50K/month because of a missing database index, optimization suddenly becomes a priority. Without this feedback loop, auto-scaling becomes a subsidy for bad architecture.
This dynamic plays out starkly in public case studies of infrastructure scaling failures, where companies discover too late that throwing money at capacity can’t fix fundamental bottlenecks. When your application architecture can’t handle viral traffic patterns, auto-scaling just means you’ll fail more expensively.
The Senior Engineer’s Dilemma
There’s a mindset gap between junior and senior engineers on scaling. Juniors see auto-scaling as a safety net, a way to ensure availability without understanding the mechanics underneath. Seniors see it as a last resort, a temporary measure that allows them to move problems from “ops emergency” to “dev backlog” while they finish their coffee.
But this only works if teams actually revisit that backlog. The danger is architectural atrophy: systems that grow increasingly complex and expensive to run because nobody remembers why they needed 40 replicas in the first place. Common microservices mistakes encountered during scale-up often stem from premature decomposition followed by aggressive auto-scaling to compensate for chatty service meshes and inefficient inter-service communication.
The Automation Trap
We see similar patterns in AI infrastructure, where trade-offs between automated memory fit and manual tuning reveal a fundamental truth: automation excels at known parameters but obscures optimization opportunities. When your auto-scaler is configured to trigger at 70% CPU utilization, you’ve implicitly decided that 30% waste is acceptable. You’ve automated the scaling decision but not the efficiency question.
Event-driven scaling with KEDA can scale pods to zero, which seems efficient until you realize your application takes 30 seconds to cold-start because nobody optimized the initialization path. The efficiency gain of “zero scale” is lost to the latency of “bloated startup.”

Knowing When to Optimize vs. When to Scale
This isn’t a manifesto against auto-scaling. When traffic patterns are genuinely unpredictable, seasonal retail spikes, viral content moments, batch processing queues, elasticity is essential. The mistake is using auto-scaling to paper over predictable, fixable inefficiencies.
The decision framework is straightforward:
- • Scale for variance: Traffic you can’t predict or control
- • Optimize for waste: CPU cycles, memory leaks, and blocking I/O you can predict and measure
If your service sits at 20% CPU utilization during peak hours while waiting on database queries, that’s not a scaling problem, it’s an optimization problem. Adding instances just means you’ll have more copies of an inefficient process running simultaneously.
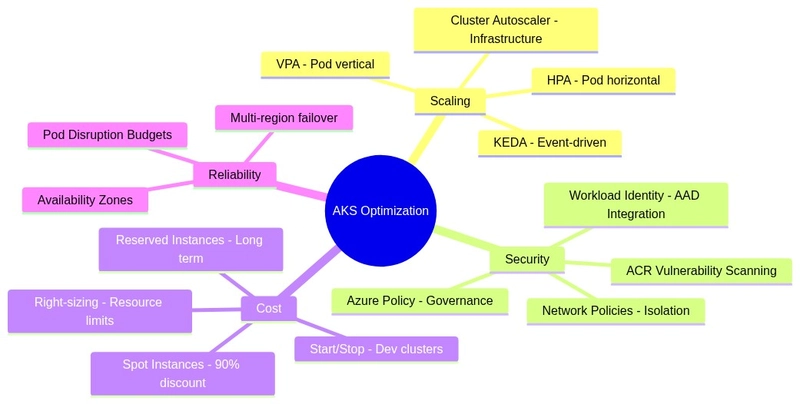
The Path Forward
Auto-scaling should be a performance shield, protecting users from traffic spikes, not an architectural band-aid covering rotting code. The teams that master this distinction treat scaling events as diagnostic data. Every time the Cluster Autoscaler provisions a new node, they ask: “Why did we need that?”
In practice, this means:
- Cost attribution by service: Make waste visible to the creators
- Optimization sprints: Dedicated time to reduce resource consumption, not just handle more traffic
- Scaling policies as technical debt indicators: If you’re scaling horizontally faster than you’re growing users, you have a efficiency crisis, not a popularity surge
The cloud didn’t eliminate the need for efficient code, it just made the consequences of inefficiency someone else’s problem until the bill arrives. Smart teams solve problems before they scale them.



