Running large language models locally on Apple Silicon has become a badge of honor for privacy-conscious developers. It feels rebellious: a $4,299 MacBook Pro cranking out tokens in a coffee shop with zero API keys and zero surveillance capitalism. But a rigorous teardown of the numbers reveals an uncomfortable truth that the local-AI evangelists rarely tweet about. When you account for hardware depreciation, electricity, and realistic token throughput, a maxed-out M5 Max costs roughly three times more per million tokens than routing the same workload through OpenRouter. And it generates those tokens two to seven times slower. The romantic narrative of “free” local inference collapses the moment you stop ignoring amortized accounting.
Why the Local-First Dream Hits an Accountant
The fantasy goes like this: buy once, infer forever. William Angel’s recent analysis of offline agentic coding on Apple Silicon punctured that balloon with a basic spreadsheet. An M5 Max MacBook Pro with 64GB of unified memory currently lists at $4,299. At roughly 50–100 watts under full inference load and U.S. residential electricity around $0.1730 per kWh, the juice to keep it mining tokens costs about $0.48 per day. That’s pocket change. The problem is that the hardware itself depreciates whether you generate zero tokens or a million.
Amortize that $4,299 over a realistic five-year lifespan and the machine costs $0.098 per hour just to exist. Over three years, the more likely horizon if you’re hammering the GPU daily, it jumps to $0.164 per hour. Angel’s math is unsparing: at 10 tokens per second, an M5 Max produces roughly 36,000 tokens per hour. Blend in electricity and the hardware line items, and the fully loaded cost lands between $1.61 and $4.79 per million tokens. At a more optimistic 40 tokens per second, it compresses to $0.40–$1.20 per million tokens.
Compare that to OpenRouter pricing for Gemma 4 31B at roughly $0.38–$0.50 per million tokens. The cloud is not just cheaper—it’s cheaper while delivering 60–70 tokens per second versus the 10–20 tokens per second you’ll actually see under local load. In other words, you paid a luxury-hardware tax to go slower. The cloud API doesn’t care about your depreciation schedule.
The Depreciation Trap: Where Your Money Really Goes
Electricity is a rounding error in this story. At $0.20 per kWh, running a MacBook at 100% inference utilization costs roughly $0.018 per hour. The hardware depreciation, meanwhile, dominates everything:
| Hardware Lifespan | Cost Per Year | Cost Per Hour |
|---|---|---|
| 3 years | $1,433 | $0.1636 |
| 5 years | $860 | $0.0982 |
| 10 years | $430 | $0.0491 |
Angel assumes five years is a reasonable middle ground for normal use. For a machine under constant GPU load, three years is more realistic. What these figures make brutally clear is that idle time is murderous. A cloud API bills you only for the tokens you consume. Your MacBook Pro bills you every hour it sits on your desk, generating nothing, depreciating into obsolescence. The notion that local inference is “free” is a bookkeeping fiction maintained by developers who expense hardware to an accounting department they don’t personally manage.
This isn’t unique to MacBooks. Enterprise analyses from Marka Development show that self-hosting generally costs 3–5x the raw GPU rental price once engineering labor, model update cycles, utilization waste, power, cooling, and hardware depreciation are folded in. If enterprise GPU clusters suffer this death-by-spreadsheet, a single laptop has no chance.
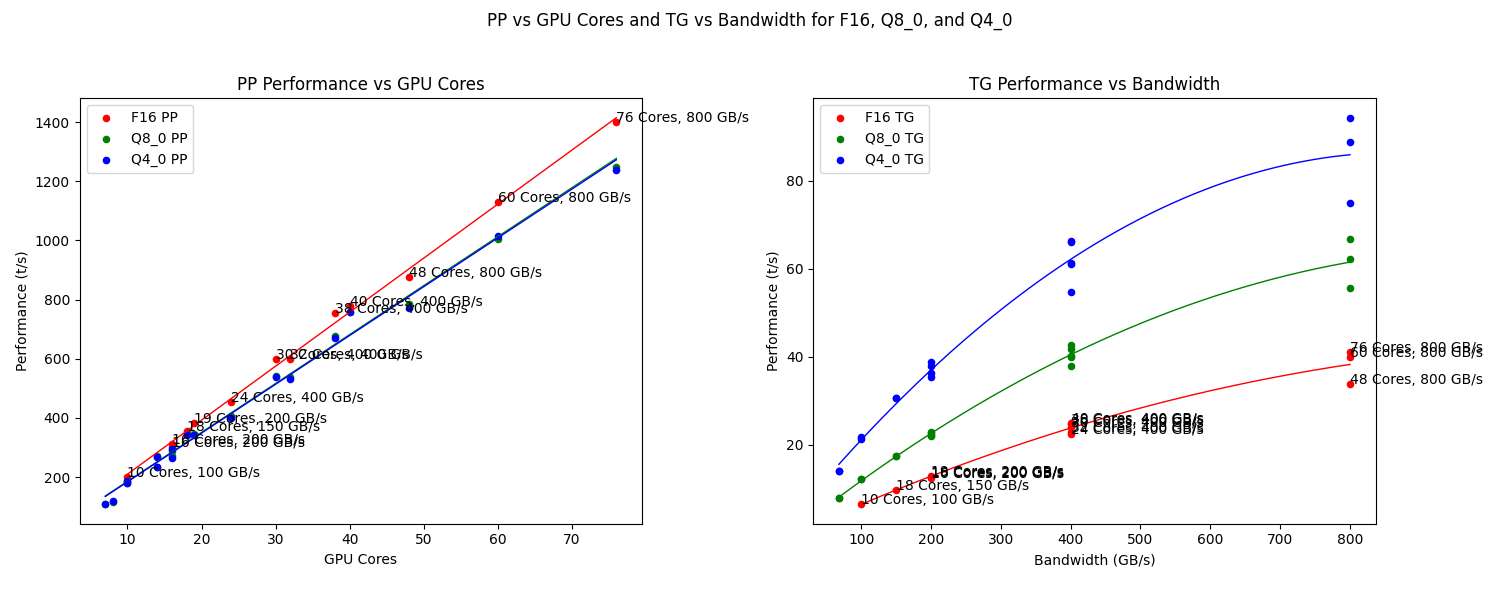
Token Velocity: Apple Silicon vs. Cloud APIs, The Numbers Are Brutal
Let’s talk about the actual experience. The llama.cpp community benchmark thread is the most comprehensive public dataset for Apple Silicon LLM performance, and it tells a story of modest generational gains and hard bandwidth ceilings.
On text generation for a 7B model, here is how flagship generations stack up:
| Chip | GPU Cores | Bandwidth | F16 TG (t/s) | Q4_0 TG (t/s) |
|---|---|---|---|---|
| M1 Max (32-core) | 32 | 400 GB/s | 23.03 | 61.19 |
| M2 Max (38-core) | 38 | 400 GB/s | 24.65 | 65.95 |
| M3 Max (40-core) | 40 | 400 GB/s | 25.09 | 66.31 |
| M4 Max (32-core) | 32 | 410 GB/s | 24.29 | 69.95 |
| M5 Max (40-core) | 40 | 614 GB/s | 37.58 | 102.93 |
Notice the pattern? From M1 Max to M4 Max, text-generation speed barely moved for full-precision models. The M5 Max finally breaks the pattern thanks to its Neural Accelerators and 614 GB/s bandwidth, but even then you’re looking at roughly 37 tokens per second for a 7B model at 16-bit precision. Drop to 4-bit quantization and you hit ~103 tokens per second, which is genuinely fast, until you consider that cloud providers routinely serve comparable models at 60–70 tokens per second, and that’s for 31B-parameter class models, not 7B toys.
For bigger models, the math gets worse. Community testing on M4 Pro configurations puts Gemma 3 27B around 8–9 tokens per second in GGUF and roughly 14–15 tokens per second in MLX. An M5 Max running Llama 3.3 70B at Q4_K_M generates roughly 28 tokens per second via MLX, dropping to ~20 through Ollama and ~18 through llama.cpp. That’s fast enough to read along with, but it’s nowhere near the snappiness of a well-provisioned API endpoint. The cloud doesn’t need to vent heat through your keyboard, either.
The Unified Memory Mirage
Apple Silicon’s unified memory architecture is simultaneously its greatest asset and its greatest sleight of hand. The marketing implies that 64GB of RAM means 64GB of GPU memory. The reality is messier. By default, only roughly 75% of total RAM is allocated to GPU use, and the operating system plus your IDE, browser, and six Docker containers are sharing that same pool. A 31B dense model at Q4 quantization eats roughly 18–20GB. A 70B model at Q4 demands ~40GB. On a 64GB machine, you’re already flirting with swap territory before you’ve opened Slack.
This is why the production AI on Apple Silicon conversation invariably comes back to memory tier, not core count. The base M4 Mac mini at $599 offers 16GB of unified memory. That’s enough for a 3B assistant or a quantized 7B model, but useless for serious agentic coding. The M4 Pro with 48GB is widely considered the sweet spot for local inference, yet even that configuration is merely adequate, not generous, for 24B to 35B models. You cannot upgrade later. The SKU you buy on day one is a permanent cage.
Software Stack Schizophrenia: The Performance Tax Nobody Talks About
Here’s where local deployment gets truly silly. The runtime you pick can swing throughput by 40–80% on the exact same hardware. According to AI Productivity’s M5 Max testing, Llama 3.1 8B at Q4_K_M clocks roughly 230 tokens per second under Apple’s native MLX framework, but drops to ~140 t/s in Ollama and ~120 t/s in raw llama.cpp. Ollama’s convenience and built-in model library cost you nearly half your potential speed.
This means your “cost per token” is actually a function of how well you tolerate command-line Python package management. The typical developer running ollama run llama3.3:70b is paying the full hardware depreciation while leaving 40% of the machine’s inference performance on the table. Meanwhile, cloud APIs offer a standardized endpoint with zero configuration variance. There’s no “oops, I forgot to compile with Metal4 support” tax in AWS.
Break-Even Math: The Volume You’ll Never Reach
Proponents of local inference love to cite break-even analysis. The logic seduces: pay $4,499 once, then generate tokens forever. AI Productivity calculates that an M5 Max 128GB fully loaded with Llama 3.3 70B at Q8 breaks even against GPT-4o output pricing at roughly 13 million tokens per month, assuming eight hours of continuous generation daily and treating labor as free. Most developers won’t sniff that volume.
Against budget-tier APIs like DeepSeek or GPT-4o mini, the break-even point recedes into the billions of tokens. Marka Development’s enterprise modeling confirms this: against frontier APIs, self-hosting only pencils out above 100–256 million tokens per month, and that’s with dedicated MLOps teams maximizing GPU utilization. For a laptop that throttles 5–10% after 30 minutes of sustained load, the volume argument is pure cope. If you’re generating fewer than 13 million output tokens monthly, you’re subsidizing Apple’s industrial design team with every inference request.
When Local Actually Wins (And It Isn’t About Money)
Privacy and compliance
If your prompt contains PHI, attorney-client material, or proprietary trading data, sending it to a third-party API is a governance nightmare. Self-hosted open models on Apple Silicon keep data inside the physical boundary. For regulated teams, this alone justifies the hardware premium.
Offline resilience
Cloud APIs require connectivity. If you’re working from a plane, a federal facility, or a country with erratic internet, local inference is the only game in town. Running LLMs locally on mobile and browser hardware is increasingly viable for exactly this reason.
Latency for small models
A 3B or 7B model running on an M4 Mini at 25+ tokens per second can feel more responsive than a round-trip to a cloud region. For private assistants, note search, and lightweight coding help, that’s a legitimate quality-of-life win—just don’t pretend it’s cheaper.
Where local doesn’t win? Raw capability. As one developer chronicled in a workflow analysis, local LLMs genuinely struggle against frontier models on demanding reasoning, multimodal tasks, and heavy agentic workflows. The gap is no longer chasmic, but it’s real. A 70B local model at Q4 is impressive—it is not Claude Sonnet 4.6. Hidden cost dynamics of AI tooling versus local inference reveal that chasing parity with frontier models on consumer silicon is a costly mirage.
The Hybrid Verdict: Stop Pretending One Side Is Always Right
The only intellectually honest architecture in 2026 is hybrid. Route sensitive, repetitive, or high-volume tasks to local models. Offload frontier reasoning, multimodal generation, and complex agentic planning to cloud APIs. Use offline AI on embedded hardware for edge deployments where autonomy matters, and use Apple Silicon for the privacy-critical middle layer.
If you’re a developer buying a Mac mini strictly to “save money on OpenRouter”, reconsider. A $599 M4 Mini with 32GB is a delightful hobby machine. A $4,299 M5 Max MacBook Pro purchased as a cloud replacement is financial theater. The cloud doesn’t depreciate. The cloud doesn’t need thermal paste. And at $0.38 per million tokens, the cloud isn’t the one draining your wallet—your “free” local setup is.