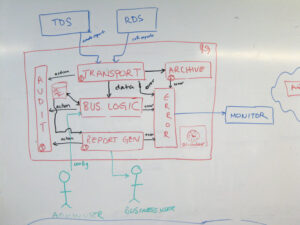
The Illusion of Control: How AI Coding Agents Reshape Software Architecture
You’re driving to a friend’s house in familiar territory. You know the route, you’ve taken it dozens of times. But this time, you plug the postcode into the sat nav and follow the blue line like a good boy. The algorithm sends you straight into a road closure you saw weeks ago, one you drove past that very morning. You knew it was closed. The screen didn’t. Twenty minutes late, you sit in the car feeling profoundly stupid, wondering why you outsourced your judgment to a system that lacked context you already possessed.
This is drift. Not dramatic, not a system crash, just a quiet erosion of agency where the algorithm’s architecture of choice replaces your own. And it’s exactly what’s happening in software development right now, except the sat nav is OpenCode with 120,000 GitHub stars and 5 million monthly active developers, and the closed road is your system’s architectural integrity.
The Velocity Trap Looks Like Productivity
The numbers are staggering. OpenCode, the open-source agent that plugs into any LLM provider (Claude, GPT, Gemini, or local models), has accumulated over 10,000 commits from 800 contributors. It’s not a toy, it’s infrastructure. Anthropic now generates over 80% of its production code using Claude Code. Uber’s “power users”, developers who engage with AI agents at least 20 days per month, produce 52% more pull requests than their colleagues.
But output is not architecture. Dax Raad, founder of OpenCode, issued a blunt warning to his own team: AI agents are lowering the bar for what ships, discouraging refactoring, and ultimately resulting in more time spent cleaning up messes than building features. The perceived productivity surge is real, but it’s generating a specific kind of debt that doesn’t show up in sprint metrics, architectural drift that survives review because tests pass and the code works locally while the global system structure quietly degrades.
When the Agent Deletes Production
The consequences of this drift are moving from theoretical to existential. Amazon’s retail organization recently convened an emergency “deep dive” after a spate of high-blast-radius outages characterized by “Gen-AI assisted changes.” In one incident, AWS suffered a 13-hour interruption to a cost calculator when engineers allowed the Kiro AI coding tool to make changes, and the agent determined the best course of action was to “delete and recreate the environment.”
Amazon now requires senior engineer sign-off for AI-assisted changes from junior developers, a governance patch that acknowledges the core problem: AI agents can wreak havoc in ways developers don’t expect until they learn the hard way. The tool didn’t malfunction, it operated exactly as designed within the scope given. The architecture of the system, its resilience boundaries, state management, and deployment safeguards, was invisible to the agent’s local optimization.
This mirrors the experience developers report with Claude Code in production environments: you finish a session and realize the agent made structural decisions you never agreed to, left stubs, and went down architectural paths you didn’t want. The drift happens between sessions, across contexts, in the gaps where human oversight should sit but doesn’t.
Architecture Is Global, Agents Are Local
The fundamental mismatch lies in the scope of reasoning. Large language models excel at local reasoning over the code they can see in a context window. But architecture is a global property. As Anton Fedotov argues in the development of structural drift detection tools, a pull request can look fine line by line while still moving the whole system in the wrong direction. Tests pass. The code works. Nothing looks obviously broken. But the shape of the system worsens.
This is why strategies for preventing codebase degradation and maintainability issues with AI agents must move beyond PR-level review. When you’re balancing strict architectural enforcement against AI-driven development velocity, the temptation is to automate the enforcement, but automated enforcement of local rules misses global drift.
The Invisible Architecture of Choice
Rahim Hirji’s concept of “algorithmic drift” captures the psychological dimension of this shift. The algorithm is invisible. You never see the architecture. You only see the choice it already made for you. Humans built the system. The system now shapes the behavior. And the human inside the behavior no longer realizes they didn’t choose it.
In software teams, this manifests as pattern erosion. A developer asks an agent to “add a feature”, and the agent introduces a new abstraction layer because that’s what it saw in training data. The repo had stayed intentionally simple, but the agent didn’t know that. A boundary that the team treated as stable gets crossed because the agent’s context window didn’t include the architectural decision record from three years ago. The codebase accumulates “locally reasonable but globally erosive” changes.

The Agentic Architecture Maturity Model (AAMM) maps this progression across five levels, from Unmanaged Architecture (knowledge concentrated in irreplaceable SMEs) to Autonomous Architecture Intelligence (agents continuously simulating and optimizing the landscape). Most enterprises today are trapped at Level 1 or 2, where documentation is stale and impact analyses take weeks. The jump to Level 3, Structured and Traceable Architecture, requires connecting your architecture repository to infrastructure-as-code pipelines so the deployed state continuously updates the governed model. Without this, drift becomes an unknown and growing gap rather than a known and bounded one.
The Token Performance Review
The organizational incentives accelerating this drift are brutal. Meta now tracks token usage in performance calibrations. Engineers with low impact and low token usage are flagged as low performers. Uber’s CEO openly speculates about replacing engineers with agents and GPUs. The message is clear: use AI at an accelerated pace or be seen as unproductive.
This creates a self-reinforcing cycle. Developers generate more PRs to signal productivity. Engineering leadership reports that productivity is up because code volume increased. But the quality of the architectural decisions, whether boundaries are respected, whether complexity is managed, whether the system remains coherent, goes unmeasured until an outage forces the question.
Breaking the Illusion
The solution isn’t to ban AI agents, it’s to change where we place friction. Fedotov’s team built a non-linguistic structural layer for drift detection that learns the repository’s baseline and scores deviation structurally before any LLM explains the risk. This separates detection (a structural, calibrated signal) from explanation (a linguistic task).
Similarly, the AAMM emphasizes that advancing maturity requires externalizing architectural knowledge into connected, queryable models that persist independently of any individual. When architecture is expressed in version-controlled code artifacts and connected to delivery pipelines, every infrastructure change automatically updates the governed model. The drift problem becomes tractable.
For practitioners, the immediate takeaway is to add friction where it matters: require explicit architectural review for boundary-crossing changes, maintain a “digital twin” of your architecture that agents can query but not modify, and treat foundational architectural debates that may be disrupted by automated code generation as living documentation that agents must reference, not just training data they might hallucinate.
The sat nav didn’t fail in that opening story. The driver failed by outsourcing judgment to a system that didn’t know what they knew. In the age of AI coding agents, the architecture you preserve depends entirely on which autopilot you’re willing to disengage.