Every message queue you’ve ever used is lying to you. It promises “at-least-once delivery” in the documentation, but what that actually means is: you will see the same message multiple times, and it’s your problem to deal with it.
Networks are unreliable. Requests time out. Consumers crash mid-processing. Brokers fail over. These aren’t edge cases, they’re the baseline operating conditions of any distributed system. The question isn’t whether you’ll get duplicates, but whether your system will survive them.
The answer is idempotency. And there are exactly five real approaches to achieve it, each with trade-offs that will either make your production life boring or turn it into a series of 3 AM pages.
The Five Approaches: A Quick Taxonomy
Before we dive into the weeds, here’s the landscape. Every idempotency strategy falls into one of these buckets:
- Storing Processed Message IDs, Track which messages you’ve already handled
- Business-Level Idempotency Keys, Use domain-specific identifiers to detect duplicates
- Database Uniqueness Enforcement, Let the database reject duplicates for you
- Naturally Idempotent Operations, Design operations so repeating them is harmless
- Inbox/Outbox Pattern, Separate message receipt from processing with a local queue
Each of these approaches makes different trade-offs around complexity, storage overhead, performance impact, replay behavior, and how much business context the handler needs to know. Let’s break them down honestly.
Approach 1: Storing Processed Message IDs
This is the most straightforward approach: maintain a set of message IDs you’ve already processed. When a new message arrives, check if its ID exists in the set. If it does, skip it. If it doesn’t, process it and add the ID.
The appeal: It’s conceptually simple. You don’t need to understand the business logic to implement it. Every message has a unique ID (or you can hash the payload), and you just need a fast lookup.
The reality: This approach works beautifully until it doesn’t. The storage requirements grow linearly with message volume. A system processing 10 million messages a day needs to retain IDs for at least the message retention window of your queue. If your queue keeps messages for 7 days, that’s 70 million IDs in storage. For a system running for months, you’re looking at billions of entries.
The performance implications are equally brutal. Every message requires a lookup before processing. At scale, that lookup needs to be fast, Redis, DynamoDB, or a dedicated index. And you need a cleanup strategy for old IDs, which adds operational complexity.
Where it shines: Simple systems with low message volumes where the storage overhead is negligible.
Where it fails: High-throughput systems where the storage and lookup costs become significant, or where message IDs aren’t guaranteed to be unique across retries.
Approach 2: Business-Level Idempotency Keys
This is the pattern that powers payment systems, job queues, and API retries. Instead of relying on message IDs, you extract or generate a business-level identifier that represents the logical operation being performed.
For a payment system, that key might be an invoice number or a payment reference. For a document generation system, it might be a document request ID. The key insight is that the same business operation, retried, will carry the same idempotency key.
The implementation is straightforward: check if you’ve already processed a request with this key. If you have, return the previous result. If you haven’t, process it and store the result keyed by the idempotency key.
The appeal: It’s business-aware. A retry of the same payment authorization carries the same invoice number, so the system can safely return the same result without charging the customer twice.
The reality: The idempotency key pattern is a retry cache, not a guarantee. The hidden complexity emerges when you think about what happens during the window between “check if key exists” and “store the result.” Without proper locking or atomic operations, two concurrent requests with the same key can both pass the check and both execute the operation. This is the classic TOCTOU (time-of-check-to-time-of-use) problem.
The Medium article on the idempotency key pattern puts it bluntly: “Networks are unreliable, requests time out, things get sent twice, this is just physics in distributed systems. You cannot build a retry-free world. What you can build is a system where doing the same thing twice has the same effect as doing it once.”
For a deeper exploration of why duplicates are inevitable in event-driven systems, the core insight is that at-least-once delivery isn’t a bug, it’s the contract.
Approach 3: Database Uniqueness Enforcement
This approach offloads the idempotency problem to your database. You create a unique constraint on a column or set of columns that represents the idempotency key. When a duplicate message arrives, the insert fails, and you catch the constraint violation.
CREATE TABLE payment_attempts (
id SERIAL PRIMARY KEY,
idempotency_key VARCHAR(255) UNIQUE NOT NULL,
invoice_id VARCHAR(255) NOT NULL,
amount DECIMAL(10,2) NOT NULL,
status VARCHAR(50) NOT NULL,
created_at TIMESTAMP DEFAULT NOW()
);
-- On duplicate key, just return the existing row
INSERT INTO payment_attempts (idempotency_key, invoice_id, amount, status)
VALUES ('inv-2026-07-04-retry-3', 'INV-2026-001', 149.99, 'completed')
ON CONFLICT (idempotency_key) DO NOTHING
RETURNING *;
The appeal: The database handles the concurrency for you. No TOCTOU race conditions. No distributed locks. Just a constraint and a conflict handler.
The reality: This approach couples your idempotency logic to your database schema. If you need to change your idempotency key strategy, you’re looking at a migration. And if your database is the bottleneck, adding uniqueness checks to every write operation adds latency.
The approach works best when combined with a conditional insert pattern. As one engineer noted, “database insert is conditional based on some idempotency id not been seen before. Maybe a body check to return a different error if the actual request has changed.” This handles the common case where a retry carries the same payload, but also catches the edge case where a retry carries a different payload with the same key, which should probably be an error.
Approach 4: Naturally Idempotent Operations
This is the engineer’s dream: design your operations so that running them twice produces the same result as running them once. No tracking, no storage, no cleanup.
Classic examples:
– Setting a customer’s address: SET address = '123 Main St' is idempotent. Running it twice produces the same state.
– Adding an item to a set (not a list): SET add item X is idempotent. The second add is a no-op.
– Deleting a record: DELETE FROM orders WHERE id = 42 is idempotent. The second delete just affects zero rows.
As the Conduktor glossary notes, “updating a customer’s current address is naturally idempotent, writing the same address twice produces the same result.”
The appeal: Zero additional infrastructure. Zero storage overhead. Zero cleanup jobs. It’s the cheapest idempotency you’ll ever implement.
The reality: Most operations aren’t naturally idempotent. Charging a credit card isn’t idempotent. Sending an email isn’t idempotent. Generating a PDF isn’t idempotent. Creating a database record with an auto-incrementing ID isn’t idempotent.
The approach works well for simple state updates but falls apart for operations with side effects. As one engineer put it, “for simple state updates I’d try to make the operation idempotent, but for side effects like payments/emails/documents I’d usually want a business idempotency key or some inbox tracking too.”
Approach 4 (Bis): The Inbox/Outbox Pattern
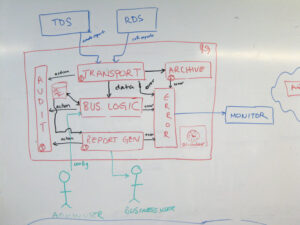
The inbox/outbox pattern is the most architecturally sophisticated approach, and it’s the one that’s been gaining serious traction in event-driven systems. The idea is simple: separate message receipt from message processing using a local database table.
Here’s how it works:
- Inbox table: When a message arrives, you first insert it into an inbox table. The insert is conditional on the message ID not already existing in the inbox.
- Processing: A separate process reads from the inbox table and processes each message.
- Outbox table: After processing, the result (or outgoing event) is written to an outbox table.
- Reliable publishing: A separate process reads from the outbox table and publishes events to downstream systems.
The NanoClaw documentation describes this pattern elegantly: “every message, a chat, a webhook, a scheduled job, one agent delegating to another, is a row in a SQLite queue, and every reply leaves through another one. There’s no separate scheduler, RPC layer, or job system to learn.”
The appeal: The inbox table provides exactly-once processing semantics within the scope of your database transaction. The outbox table ensures reliable event publishing. The pattern decouples message receipt from processing, allowing you to handle backpressure and retries independently.
The reality: The inbox/outbox pattern trades immediate consistency for better availability and scalability. As the Conduktor glossary notes, “the outbox pattern trades immediate consistency for better availability and scalability, making it more suitable for modern microservices architectures where services should remain independent.”
The complexity cost is real. You’re now maintaining two additional database tables, a background processing loop, and a reliable publishing mechanism. For simple systems, this is overkill. For complex systems with multiple downstream dependencies, it’s often the only sane choice.
The Trade-Off Matrix
Let’s be honest about what each approach costs you:
| Approach | Complexity | Storage Overhead | Performance Impact | Replay Behavior | Business Context Required |
|---|---|---|---|---|---|
| Stored Message IDs | Low | High (grows with volume) | Medium (lookup per message) | Full replay possible | None |
| Business Idempotency Keys | Medium | Medium (keyed by business ID) | Medium (lookup + storage) | Replay returns cached result | High |
| DB Uniqueness Enforcement | Low | Low (constraint only) | Low (DB handles it) | Replay fails gracefully | Medium |
| Naturally Idempotent Ops | None | None | None | Perfect replay | High (must design for it) |
| Inbox/Outbox Pattern | High | High (two tables + processing) | Medium (background processing) | Full replay with tracking | Low |
When Each Pattern Breaks
The real test of an idempotency strategy isn’t how it works in the happy path. It’s how it behaves when things go wrong.
Stored Message IDs: The Cleanup Problem
Your processed message ID store grows forever unless you implement cleanup. But cleanup introduces its own problems: what happens when a duplicate message arrives after you’ve cleaned up its ID? You process it again. This means your cleanup window must be at least as long as your message retention period. And if your queue has variable delivery delays (some messages arrive hours late), you need to keep IDs for the maximum possible delay.
Business Idempotency Keys: The TOCTOU Trap
The classic failure mode: two concurrent requests arrive with the same idempotency key. Both check the store. Neither finds the key. Both process the request. You’ve now charged the customer twice.
The fix requires atomic check-and-set operations. Redis has SETNX. Databases have unique constraints. Distributed locks add latency. The point is: the simple “check then write” pattern is broken by design.
Database Uniqueness: The Schema Coupling
Your idempotency strategy is now part of your database schema. Changing it requires migrations. If you need to support multiple idempotency key strategies across different message types, your schema gets messy. And if your database is sharded, uniqueness enforcement across shards becomes a distributed coordination problem.
Naturally Idempotent: The Side Effect Problem
The operation itself might be idempotent, but what about the side effects? Updating a customer’s address is idempotent. But what if the update triggers a downstream notification? Or a credit check? Or a fraud analysis? Those side effects might not be idempotent.
The Kafka exactly-once semantics documentation highlights this: “The system ensures that every record is processed exactly one time, avoiding both data loss and data duplication.” But that guarantee only covers the Kafka transaction itself, not the side effects your application performs after consuming the message.
Inbox/Outbox: The Complexity Tax
The inbox/outbox pattern is the most robust approach, but it comes with a significant complexity cost. You need:
– An inbox table with uniqueness constraints
– A background processor that reads from the inbox
– An outbox table for results
– A reliable publishing mechanism for the outbox
– Monitoring for stuck messages, processing delays, and outbox backlogs
For a system processing millions of messages daily, this complexity is justified. For a simple CRUD service processing a few hundred messages an hour, it’s architectural overkill.
Choosing Your Pattern: A Decision Framework
The right approach depends on your consumption pattern. Here’s a practical decision tree:
Is the operation naturally idempotent?
– Yes → Use it. No additional infrastructure needed.
– No → Keep reading.
Does the operation have side effects (payments, emails, API calls)?
– Yes → You need an idempotency key or inbox/outbox pattern.
– No → Database uniqueness enforcement is probably sufficient.
What’s your throughput?
– Low (< 100K messages/day) → Stored message IDs or DB uniqueness will work fine.
– High (> 1M messages/day) → Inbox/outbox pattern scales better.
Can you tolerate eventual consistency?
– Yes → Inbox/outbox pattern with background processing.
– No → Business idempotency keys with atomic check-and-set.
The Hidden Complexity of Distributed Idempotency
The most dangerous assumption engineers make is that idempotency is a solved problem once you’ve picked a pattern. It’s not. The hidden complexity of idempotency beyond simple key-based replay reveals itself in production:
- Time-of-check-to-time-of-use (TOCTOU) races: Two concurrent requests with the same key can both pass the check.
- Clock skew: If your idempotency keys include timestamps, clock drift between services can cause false positives or negatives.
- Partial failures: What happens when you’ve stored the idempotency key but the processing fails halfway through? Do you retry? Do you return the partial result?
- Key collisions: What happens when two different operations legitimately share the same idempotency key? This is more common than you’d think in systems with auto-generated keys.
The Payment System Nightmare
The most unforgiving domain for idempotency is payment processing. The problem of in-flight requests and timeout ambiguity in payment systems is a special kind of hell.
Consider this scenario: A customer clicks “Pay Now.” The request reaches your payment service. The service calls the payment gateway. The gateway processes the charge but the response times out. Your service doesn’t know if the charge went through. It retries. The gateway sees a duplicate charge request. Without idempotency, the customer gets charged twice.
The idempotency key pattern is the standard solution here. The payment gateway provides an idempotency key (often the invoice number or a client-generated UUID). If the same key arrives again, the gateway returns the previous result instead of processing a new charge.
But even this pattern has edge cases. What if the first request actually failed (network error before reaching the gateway) and the second request succeeds? The gateway sees the same key and returns the “previous result”, which was a failure. Your customer never gets charged. You’ve now lost revenue because your idempotency was too aggressive.
The fix is to only cache successful results, or to use a more sophisticated state machine that distinguishes between “never seen this key” and “seen this key and it failed.”
The Outbox Pattern: Not Just for Idempotency
The outbox pattern deserves special attention because it solves two problems at once: idempotent processing and reliable event publishing.
The pattern works like this:
- Your service receives a message.
- It starts a database transaction.
- Within the transaction, it inserts the message into the inbox table (with a uniqueness constraint on the message ID).
- It performs the business logic.
- It inserts the result (or outgoing event) into the outbox table.
- It commits the transaction.
- A separate process reads from the outbox table and publishes events to downstream systems (Kafka, RabbitMQ, webhooks, etc.).
The key insight: steps 2-6 happen within a single database transaction. If the transaction commits, both the inbox entry and the outbox entry are persisted atomically. If the transaction fails, neither is persisted. This gives you exactly-once processing semantics within the scope of your database.
The outbox pattern is particularly powerful for outbox patterns and projection-based read models as alternatives to real-time aggregation, where you need to maintain consistent read models without sacrificing write throughput.
The Consumption Pattern Matters
The Reddit discussion on this topic surfaced a crucial insight: the right approach depends on your consumption pattern. As one commenter noted, “I think it depends on what’s your consumption pattern.”
Batch consumers that process messages in bulk need different idempotency strategies than stream consumers that process one message at a time. Batch consumers can check for duplicates in bulk (e.g., SELECT * FROM processed_messages WHERE id IN (...)) and skip them before processing. Stream consumers need per-message checks.
Transactional consumers that can roll back their processing on failure have different needs than non-transactional consumers that can’t undo side effects. If you can roll back, you can afford to process a duplicate and undo it. If you can’t, you need to detect duplicates before processing.
Stateful consumers that maintain local state (e.g., in-memory caches, local databases) have different needs than stateless consumers that delegate all state to external systems. Stateful consumers can use local storage for idempotency tracking, reducing latency but adding complexity around state recovery after crashes.
The State Machine Approach
For complex business workflows, a state machine can handle idempotency naturally. If your process is modeled as a state machine with well-defined transitions, duplicate messages that trigger already-completed transitions can be safely ignored.
As one engineer noted, “If process is classic business bureaucracy, state machine modeled behind process should include realistic solution to this issue. Like not being able to change state on occurrence of same state transition.”
This approach works well for order processing, approval workflows, and document lifecycle management. The state machine itself becomes the idempotency mechanism: a transition from “pending” to “approved” can only happen once. A duplicate message attempting the same transition is a no-op.
The challenge is modeling your business process as a state machine in the first place. Many systems start with ad-hoc status fields and evolve into state machines only after the complexity becomes unmanageable.
Production Lessons
After years of building and debugging message-driven systems, here are the lessons that cost the most to learn:
1. Test with actual duplicates, not simulated ones.
Simulated duplicates (sending the same message twice from a test script) don’t capture the real failure modes. Real duplicates come with different timestamps, different correlation IDs, different trace contexts, and sometimes slightly different payloads. Your idempotency logic needs to handle all of these.
2. Monitor your idempotency hit rate.
If you’re seeing a 0% duplicate rate, either your system is perfectly reliable (unlikely) or your idempotency detection is broken. Track how many messages are being skipped as duplicates. A sudden drop in the duplicate rate might mean your idempotency store is failing silently.
3. Plan for idempotency store failures.
Your idempotency store (Redis, database, whatever) will fail. When it does, what happens? Do you fail open (process everything, risking duplicates) or fail closed (process nothing, risking backpressure)? The answer depends on your domain. Payment systems should probably fail closed. Logging systems can probably fail open.
4. Idempotency keys need to be idempotent themselves.
This sounds obvious, but it’s easy to get wrong. If your idempotency key includes a timestamp, a retry will have a different timestamp and thus a different key. Your idempotency is broken. The key must be derived from the business operation, not from the message metadata.
5. Cleanup is a first-class concern.
Every idempotency store needs a cleanup strategy. TTL-based expiration works for Redis. Scheduled deletion jobs work for databases. But cleanup introduces the risk of processing a duplicate after the original record has been cleaned up. Your cleanup window must be at least as long as your maximum message delivery delay.
The Bottom Line
There is no one-size-fits-all idempotency strategy. The right approach depends on your throughput, your business domain, your tolerance for complexity, and your willingness to handle edge cases.
For simple state updates, make the operation naturally idempotent and move on with your life.
For operations with side effects, use business idempotency keys with atomic check-and-set operations.
For high-throughput systems with complex processing, invest in the inbox/outbox pattern.
For everything else, database uniqueness enforcement is a solid middle ground.
The worst thing you can do is pretend duplicates won’t happen. How webhook systems handle delivery semantics and duplicate detection is a master class in why “at-least-once” delivery is the default for a reason, and why pretending otherwise leads to production incidents.
Your message queue is lying to you. Build accordingly.