Webhooks look like the easiest thing in the world. You send an HTTP POST to a URL. Job done. Your payment system notifies your inventory system. Your CI/CD pipeline pings Slack. Your CRM gets updated in real-time. What’s the big deal?
The big deal is that under the hood, every production-grade webhook system is a miniaturized pub/sub infrastructure with persistent queues, isolation boundaries, delivery semantics, and failure modes that will silently eat your data if you look away for five minutes.
Let’s peel back the layers.
The Polling Problem That Webhooks “Solved”
Before webhooks, there was polling. And polling was awful.
Imagine you’re building a payment gateway. A customer initiates a transaction. Your PaymentService calls Stripe’s API, and Stripe responds with a “we’ll process this asynchronously” token. Now what? You could poll Stripe’s API every few seconds, burning CPU cycles, bandwidth, and API quota on responses that are 99% worthless because the payment is still pending.
On the other side, Stripe’s API would get flooded with millions of status-check requests from every merchant on the planet. It’s a coordination disaster dressed up in HTTP.
The push-based approach flips the script: “Stripe, when you’re done, just call me.” Clean, efficient, obvious. But the infrastructure required to make that work at scale is anything but simple.
What Actually Happens When You Register a Webhook
When you give a service like Stripe or GitHub a callback URL, you’re not just handing them an endpoint. You’re entering into a complex contract with retry semantics, ordering guarantees, and authentication protocols that most developers never fully appreciate.
Here’s the reality of what happens on the provider side:
- Your request hits the Ingress layer, where the core product emits an internal event to a shared message bus (Kafka or equivalent).
- An Event Router matches your event type against a database of registered subscribers.
- A Delivery Queue fans out across multiple subscribers, one payment event can become ten delivery jobs.
- Dispatcher Workers pull jobs, sign payloads with your secret, POST to your URL, and handle the fallout.
Every step in this chain can fail. And the complexity of handling those failures is where webhooks stop being “simple HTTP” and start being a distributed systems problem.
The Retry Trap: Why Blind Retries DDoS You
The most common failure mode in webhook design is naive retry logic. A dispatcher fails to reach your endpoint. So it retries immediately. Then again. And again. Before you know it, your retry storm is amplifying the very failure you’re trying to recover from.
Production-grade systems separate the main queue from the retry queue, with carefully engineered backoff intervals:
- Retry #1 → after 1 minute
- Retry #2 → after 5 minutes
- Retry #3 → after 15 minutes
- Retry #4 → after 1 hour
- Max retries → 24 hours, then dead-letter queue
This isn’t just about being polite to the downstream service. It’s about preventing cascading failure in your own infrastructure. A poorly designed retry loop can take down both the sender and receiver simultaneously.
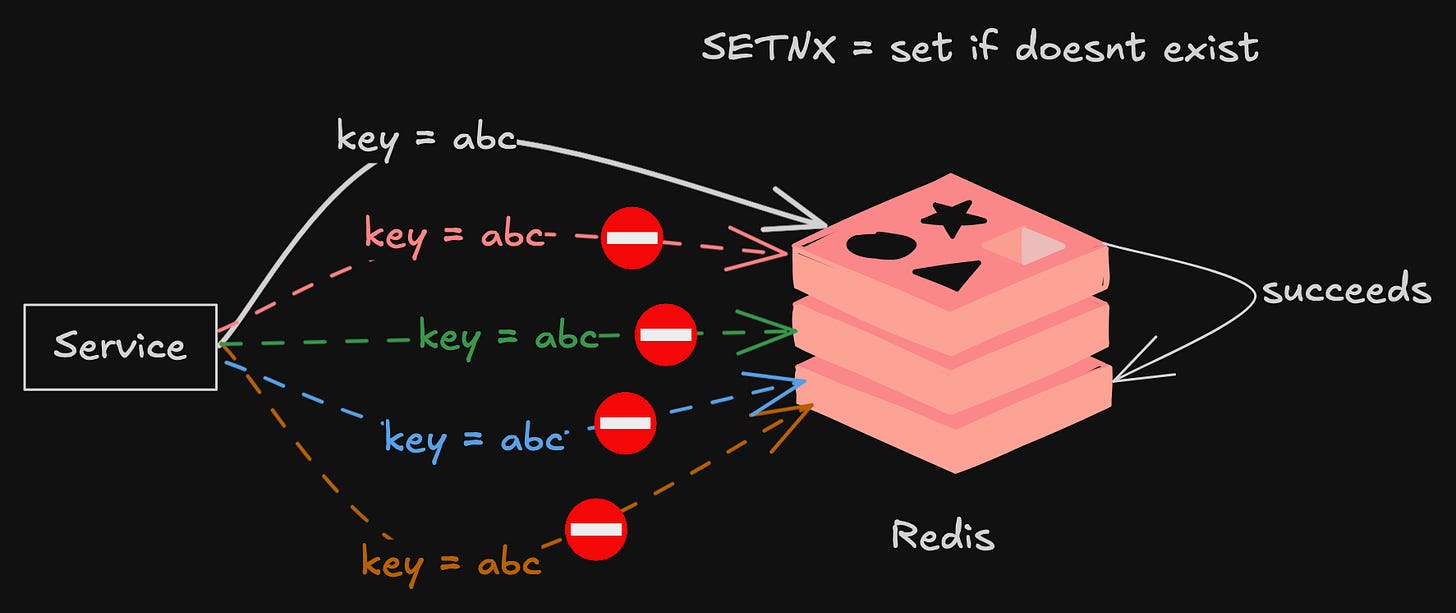
At-Least-Once Semantics Means Idempotency or Bust
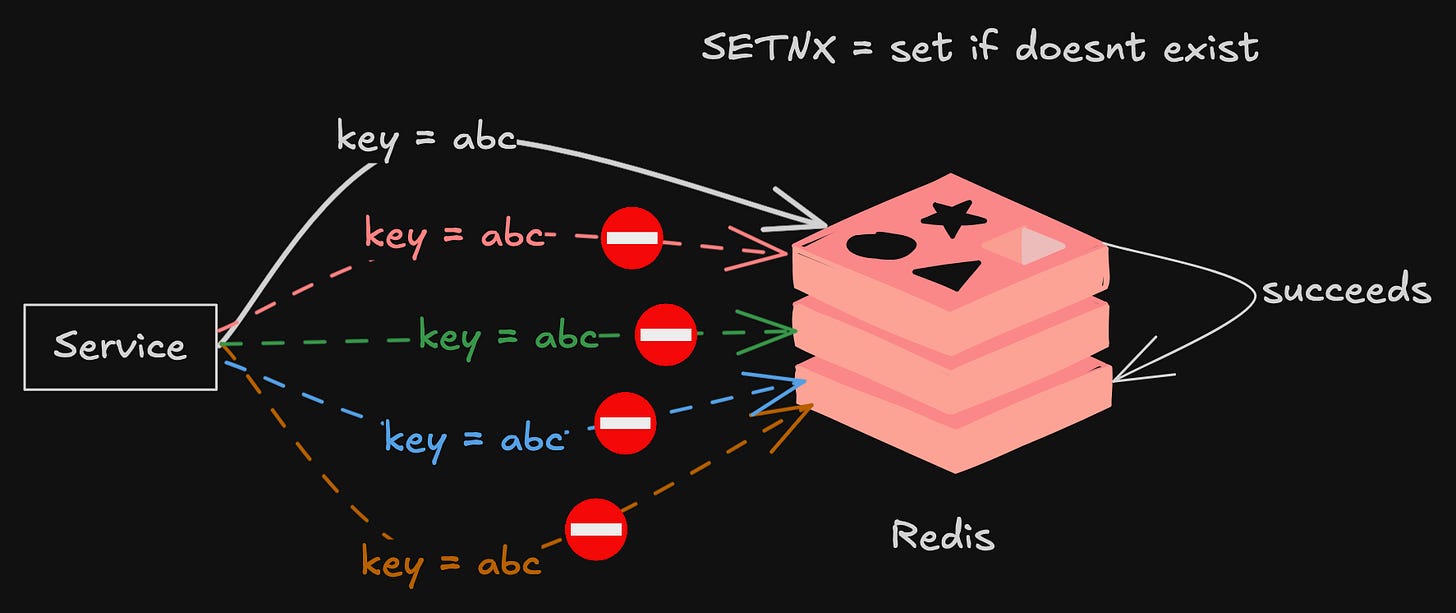
Here’s the uncomfortable truth about distributed webhook systems: they operate with at-least-once delivery semantics. That means the same event can be delivered to your endpoint multiple times. If your handler isn’t idempotent, you’re going to have a bad time.
The net._http_response table in Supabase’s pg_net extension stores response messages from the past 6 hours. If you’re seeing NULL values in every column except id, error_msg, and created, you’re experiencing a timeout bug that’s been silently dropping events. By default, Supabase webhooks execute the next 200 available queued requests. If requests come in too fast, you get a mass timeout.
This is the kind of failure that doesn’t scream. It whispers. Your monitoring dashboard turns green while your event pipeline silently hemorrhages data.
The fix requires building truly idempotent systems where duplicate deliveries produce the same result as a single delivery. This means deduplication keys, pessimistic locking, or idempotent operations at the data level.
The Blocked Consumer Problem: One Slow Endpoint Ruins Everything
You’ve designed your webhook system beautifully. Then one customer deploys a callback endpoint that takes 30 seconds to respond because their database is on fire. Now what?
If your dispatcher blocks waiting for that response, every other customer’s events queue up behind the slow one. Latency spikes across the board. Retries multiply. The whole system degrades.
The solution is multi-layered:
Tenant Sharding partitions the delivery queue by tenant or region. Each worker pool processes a subset of tenants, preventing one slow customer from affecting others. Your delivery queue might look like delivery_queue_m123, delivery_queue_m124, and so on.
Rate Limits per client cap delivery concurrency. Five in-flight requests max per tenant. No more.
Circuit Breakers pause deliveries for a cooldown period when a tenant’s endpoint fails N times in a row. The system stops hammering a dead endpoint and moves on to the next job.
This is the architecture that Stripe, GitHub, and Supabase actually run in production. A monolithic “just-send-HTTP” approach collapses under backpressure, retries, and latency spikes within minutes.
Security: The Signature Verification That Saves Your Bacon
Anyone can POST to your webhook endpoint if it’s exposed to the internet. Without authentication, you’re one DNS enumeration scan away from accepting fake payment notifications or fraudulent GitHub events.
Every serious webhook provider signs their payloads. The consumer verifies the signature before processing. This requires:
- A shared secret (or asymmetric key pair) established during webhook registration
- A cryptographic signature included in the HTTP headers
- Timestamp verification to prevent replay attacks
- Rigorous comparison that’s immune to timing attacks
The dispatcher worker code looks something like this:
def dispatch_event(event_id, callback_url, payload, secret):
signature = hmac.new(
secret.encode(),
payload.encode(),
hashlib.sha256
).hexdigest()
headers = {
"X-Webhook-Signature": signature,
"X-Webhook-Timestamp": str(int(time.time())),
"Content-Type": "application/json"
}
resp = http.post(callback_url, json=payload, headers=headers, timeout=5)
if resp.status_code == 200:
mark_delivered(event_id)
else:
enqueue_retry(event_id)
On the receiving end, you verify both the signature and the timestamp. Any deviation means drop the event and log the hell out of it.
The Observability Blind Spot
Webhooks are fundamentally fire-and-forget from the sender’s perspective, with retries. But from the consumer’s perspective, they’re invisible until they arrive. There’s no end-to-end tracing. No guarantees about ordering. No built-in mechanism to know if an event was lost.
This is where the documentation and observability challenges inherent in event-driven architectures become painfully real. You can’t debug “the order was never created” by looking at a single service’s logs. You need distributed tracing that spans the webhook provider’s infrastructure, your callback endpoint, and every downstream system.
Supabase’s debugging guide recommends inspecting the net._http_response table for failed requests:
select *
from net._http_response
where "status_code" >= 400 or "error_msg" is not null
order by created desc;
But this only tells you what Supabase saw. It doesn’t tell you what happened after your system received the payload and crashed processing it.
When Webhooks Are the Wrong Answer
Webhooks are not a universal solution. They’re a specific tool with specific trade-offs.
Polling makes sense when you need predictable latency, can’t expose a callback URL, or want tight control over request volume. The cost is wasted resources. The benefit is simplicity.
Server-Sent Events (SSE) make sense for one-to-many broadcast patterns where the client needs a continuous stream of updates. The connection stays open. The server pushes. No retry infrastructure needed.
Message queues (Kafka, RabbitMQ, SQS) make sense when you need guaranteed delivery, ordered processing, replayability, or fan-out to multiple consumers with independent consumption rates. The cost is operational complexity. The benefit is robustness.
If you’re building a system where event loss is unacceptable and delivery guarantees matter, webhooks are the wrong foundation. You need a proper queue. The hidden technical debt that accumulates in integration layers when you skimp on the transport layer will come due eventually, usually at 3 AM on a Saturday.
The Real Architecture Behind “Just an HTTP Call”
What Stripe, GitHub, and every other webhook provider has built is a distributed pub/sub system where the transport protocol happens to be HTTP. The architecture includes:
- Persistent queues at every stage of the pipeline
- Isolation boundaries between tenants
- Delivery semantics with exponential backoff
- Dead-letter queues for events that can’t be delivered
- Monitoring and alerting for queue depth and delivery latency
- Subscription management with dynamic filtering
This is not simple. This is a distributed systems engineering problem dressed up in a RESTful interface.
What This Means for Your Next Integration
If you’re building a system that consumes webhooks, design your callback endpoint as if it will receive every event twice, out of order, at 3 AM on a server that’s running out of memory.
- Make every handler idempotent. Use a deduplication table with the event ID as the primary key. Check before processing.
- Respond fast. Return 200 as soon as you’ve validated and queued the event internally. Don’t process the event in the webhook handler, process it asynchronously.
- Implement backpressure. If your processing pipeline can’t keep up, return 429 or 503. The sender will retry.
- Log everything. Record every incoming event, every response code, every retry. You will need this data.
- Verify signatures. Always. Without exception.
If you’re building a system that sends webhooks the challenges of coordinating system behavior across distributed services become your problem to solve. You need rate limiting, tenant isolation, circuit breakers, retry queues, monitoring, and a dead-letter strategy.
The Bottom Line
Webhooks are a contract. One system promises to notify another when something happens. Fulfilling that promise requires infrastructure that’s invisible to the caller but essential to the system’s reliability.
The next time someone says “let’s just use webhooks”, ask them how they’re handling backpressure. Ask about idempotency. Ask about signature verification. Ask what happens when the callback endpoint goes down for an hour.
The answers will tell you whether they’ve built a webhook system or a webhook trap.



