You’re building a system that needs to mine data, analyze it with LLMs, make decisions, and repeat. The architecture diagram looks clean. The reality is a tangled mess of hanging workflows, blown-up Redis RAM, and unanswered requests that leave your entire pipeline frozen in a state of existential dread.
This is the world of task orchestration in microservices, and it’s where frameworks like Temporal, Hatchet, and Prefect enter the chat. Each promises to solve the same fundamental problem: how do you reliably execute complex, long-running workflows across distributed services without losing your mind (or your data)?
The answer, as always, is “it depends.” But the reasons it depends are where things get interesting.
The Problem That Won’t Die: Event-Driven Communication Without Guarantees
Let’s start with the pain point that’s driving most architects to these tools in the first place. A team building a system to mine data, analyze it with LLMs, make decisions, and repeat. They landed on Redis streams for service communication and Hatchet for heavy task execution. The result? A nightmare of unanswered requests, blown-up RAM, and workflows hanging forever.
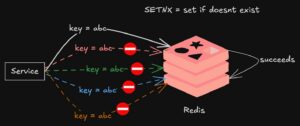
The core tension is this: event-driven communication is great for broadcasting “something happened” to anyone who cares. It’s terrible for saying “Service X, please do this specific thing and report back.” Redis streams, Kafka, and similar pub-sub systems are designed for fire-and-forget event broadcasting, not request-reply patterns. When you need a guarantee that a specific service will process a message and respond, you’re no longer doing event-driven architecture, you’re doing async RPC with extra steps.
This is the fundamental architectural confusion that drives teams toward dedicated orchestration frameworks. Let’s break down how Temporal, Hatchet, and Prefect handle this reality, and where each one shines or falls apart.
The Three Contenders: A Quick Orientation
Before we dive into the bloodbath, let’s establish what each tool actually is.
Temporal is the heavyweight champion of durable execution. It’s been around the longest, has the most battle-tested infrastructure, and is backed by a company that takes enterprise contracts seriously. Temporal lets you write workflows as normal code that automatically survive crashes, restarts, and network failures. It’s the gold standard for mission-critical, long-running workflows where failure is not an option.
Hatchet is the newer kid on the block, an MIT-licensed, open-source orchestration engine that’s been processing over 130 million tasks daily on its cloud platform. It positions itself as the pragmatic middle ground: durable execution without the overhead of Temporal’s heavy infrastructure, with native support for AI agents, parallel workloads, and event-driven triggers. Workers run on your infrastructure while the orchestration engine is available as a managed service or self-hosted.
Prefect is the Python-native workflow orchestration framework that’s been the darling of the data engineering world. It’s designed for building resilient data pipelines with a focus on developer experience and observability. Prefect shines when your workflows are Python-heavy and data-centric, but it’s less opinionated about the infrastructure layer than Temporal or Hatchet.
The Architecture Trap: Event-Driven Isn’t Async RPC
Teams conflating event-driven architecture with async request-reply. The OP’s team used Redis streams for service communication and Hatchet for heavy tasks. The result was a system where unanswered requests left workflows hanging forever, and Redis RAM management became a full-time job.
The fundamental insight here is that event-driven communication and task orchestration solve different problems. Events say “something happened.” Orchestration says “do this, and tell me when you’re done.” When you try to force events to do the work of orchestration, you end up with:
- Memory bloat from unconsumed stream messages
- No delivery guarantees for request-reply patterns
- Hanging workflows when a service fails to respond
- No built-in timeout or retry mechanisms at the communication layer
“There’s no way to enforce the recipient will reply. this really has given us headaches cuz it’s enough to have one unanswered request and our entire workflow ends up hanging forever.”
The Orchestration Trinity: Where Each Tool Lives
Temporal: The Enterprise Heavyweight
Temporal is the most mature and battle-tested of the three. It’s built around the concept of durable execution, your workflow code is replayed from an event log, meaning it can survive process crashes, server failures, and even full data center outages. Temporal’s architecture is fundamentally different from traditional task queues: instead of sending messages between services, it records the execution history of your workflow and replays it on worker restarts.
This makes Temporal the undisputed king for mission-critical, long-running workflows where failure is not an option. Financial services, healthcare, and enterprise SaaS companies run Temporal in production for workflows that span days or weeks.
But Temporal comes with baggage. The infrastructure requirements are non-trivial, you need to run Temporal Server, Cassandra or PostgreSQL for persistence, and Elasticsearch for visibility. The learning curve is steep, and the operational overhead can be significant for smaller teams. Temporal’s workflow code must be deterministic (no random numbers, no direct API calls, no time-based logic without special APIs), which introduces a cognitive overhead that many developers find frustrating.
Hatchet: The Pragmatic Middle Ground
Hatchet enters this landscape as the “just works” option for teams that need durability without the Temporal tax. The numbers from their website tell an impressive story: 130 million tasks run daily on Hatchet Cloud, with an average start latency of 25ms per task, and over 1,000 active projects running on the platform.
What makes Hatchet interesting is its architectural philosophy. Unlike Temporal, which requires you to write deterministic workflow code, Hatchet lets you define tasks as simple functions and compose them into workflows. The orchestration engine handles durability, retries, and state management transparently.

The architecture is refreshingly straightforward: workers run on your infrastructure, the orchestration engine runs as a managed service or self-hosted, and they communicate over a persistent connection. This means you get the reliability of a centralized orchestrator without the operational nightmare of managing Cassandra clusters.
Hatchet’s numbers are worth paying attention to: 25ms average start latency per task and 130 million tasks run daily on their cloud platform. For teams processing LLM inference workloads or running AI agent pipelines, that latency matters. When you’re chaining together dozens of LLM calls, each one taking seconds to respond, you don’t want your orchestration layer adding hundreds of milliseconds of overhead.
The Redis Streams Trap: Why Event-Driven Communication Fails for Request-Reply
The team’s setup was:
- Services communicate via Redis streams
- Heavy tasks execute within Hatchet
- Light work happens on Redis stream consumers
The problems they encountered are instructive:
Memory management nightmare. Redis keeps all messages in RAM. When you’re processing high-throughput data pipelines, the stream grows unbounded unless you actively trim it. But trimming defeats the purpose of having the stream for replay or multiple consumer groups. The team found themselves in a constant battle between RAM usage and data retention.
No delivery guarantees. Redis streams don’t enforce that a consumer will process a message. If a consumer crashes or the processing logic fails, the message sits in the stream indefinitely. The team’s workflows would hang forever waiting for responses that never came.
No built-in timeout or retry mechanisms. When a service fails to respond, there’s no automatic retry, no escalation, no dead-letter queue. The workflow simply waits forever.
This is the exact scenario where a dedicated orchestration framework becomes not just useful but necessary. The question is which one.
Temporal: The Gold Standard, With a Gold Standard’s Price
Temporal’s approach to this problem is elegant but demanding. Your workflow code is written as a series of steps, and Temporal’s server records every state transition. If a worker crashes mid-workflow, a different worker picks up the execution log and replays it from the last checkpoint. This means your workflow is durable by default, it survives process crashes, server failures, and even full data center outages.
The trade-off is significant. Temporal requires you to write deterministic workflow code. You can’t make direct HTTP calls from within a workflow, you have to use Temporal’s Activity abstraction. You can’t use random numbers or time-based logic without Temporal’s SDK wrappers. This cognitive overhead is real, and it’s the primary reason teams look for alternatives.
Temporal’s infrastructure requirements are also substantial. You need:
– Temporal Server (clustered for production)
– A persistence backend (Cassandra, PostgreSQL, or MySQL)
– Elasticsearch for advanced visibility features
– Multiple worker deployments
For a team of 5-10 engineers, this is a significant operational burden. Temporal is the right choice when you’re building systems where failure costs millions of dollars. It’s overkill when you’re trying to process LLM inference pipelines with reasonable reliability.
Hatchet: The Pragmatic Middle Ground
Hatchet enters this landscape as the “just works” option for teams that need durability without the Temporal tax. The numbers from their website tell an impressive story: 130 million tasks run daily on Hatchet Cloud, with an average start latency of 25ms per task, and over 1,000 active projects running on the platform.
What makes Hatchet interesting is its architectural philosophy. Unlike Temporal, which requires you to write deterministic workflow code, Hatchet lets you define tasks as simple functions and compose them into workflows. The orchestration engine handles durability, retries, and state management transparently.
The architecture is refreshingly straightforward: workers run on your infrastructure, the orchestration engine runs as a managed service or self-hosted, and they communicate over a persistent connection. This means you get the reliability of a centralized orchestrator without the operational nightmare of managing Cassandra clusters.
Hatchet’s numbers are worth paying attention to: 25ms average start latency per task and 130 million tasks run daily on their cloud platform. For teams processing LLM inference workloads or running AI agent pipelines, that latency matters. When you’re chaining together dozens of LLM calls, each one taking seconds to respond, you don’t want your orchestration layer adding hundreds of milliseconds of overhead.
Prefect: The Data Pipeline Specialist
Prefect has carved out a strong niche in the data engineering world. It’s Python-native, which makes it the natural choice for teams already invested in the Python data ecosystem (Pandas, NumPy, PyTorch, etc.). Prefect’s strength is in building resilient data pipelines with clear dependency graphs, automatic retries, and rich observability.
Where Prefect struggles is in the microservices context. It’s designed for data pipelines, not distributed service orchestration. If your workflows involve multiple services written in different languages, or if you need tight integration with event-driven communication patterns, Prefect’s Python-centric model becomes a limitation. It’s excellent for ETL pipelines and data processing workflows, but less suited for orchestrating heterogeneous microservices.
The Hatchet Advantage: Durable Execution Without the Determinism Tax
The team eventually started leaning toward using Hatchet for inter-service communication, but they had reservations. Their concerns are worth examining because they highlight the real trade-offs:
“I like the separation that light work happens on the Redis stream consumers, and they only delegate the work to Hatchet tasks when it’s heavy.” This is a valid concern about overhead. Not every message needs the full orchestration treatment. Sometimes you just need to update a cache or log an event. The question is whether the overhead of routing everything through an orchestration engine is worth the reliability gains.
“It’s much more convenient to open the Hatchet UI and see only ‘real’ heavy tasks.” This is a legitimate UX concern. When you put everything through the orchestration engine, the dashboard becomes cluttered with trivial tasks. Hatchet’s response to this is its concurrency and priority features, which let you separate critical workflows from background noise.
“There’s no separation of ‘public’ API vs ‘private’ API for a service.” This is a real architectural concern. In a microservices environment, you want to control which services can invoke which workflows. Hatchet’s approach is to let you define workflows and tasks, but any service with access to the orchestration engine can trigger any workflow. This lack of API boundary enforcement is a genuine limitation.
The LLM Pipeline Problem: Where Orchestration Gets Real
The use case that’s driving most of the current interest in these frameworks is LLM processing pipelines. The pattern is almost universal:
- Ingest data from multiple sources
- Process with LLM calls (each taking 5-30 seconds)
- Make decisions based on results
- Repeat with new data
This pattern exposes the weaknesses of both traditional task queues and event-driven architectures. LLM calls are expensive (both in time and money), so you want retries and timeouts. They’re also non-deterministic, the same input can produce different outputs, which breaks Temporal’s replay model. And they’re long-running, which means you need durable execution that can survive worker restarts.
Hatchet’s approach to this is particularly well-suited. Its durability features allow agents to automatically checkpoint their current state and pick up where they left off when faced with unexpected errors. The observability features and distributed-first approach are built for debugging long-running agents at scale.
The Hatchet Architecture: Workers on Your Infrastructure, Orchestration as a Service
One of Hatchet’s most compelling features is its architectural separation. Workers run on your infrastructure, Kubernetes, Docker, ECS, Cloud Run, or any container platform, while the orchestration engine is available as a managed service or can be self-hosted. This means you get the reliability of a centralized orchestrator without the operational burden of managing the orchestration infrastructure yourself.
The worker model is straightforward: you deploy long-running processes that connect to the Hatchet engine and pull tasks. Workers can be autoscaled based on queue depth, and Hatchet’s slot-based concurrency control ensures workers don’t take on more work than they can handle. This is a significant improvement over traditional queue-based systems where you’re constantly tuning consumer counts and prefetch settings.
For teams running LLM pipelines, Hatchet’s durability features are particularly valuable. When an LLM call fails after 30 seconds of processing, you don’t want to lose that work. Hatchet’s checkpointing means the agent can pick up where it left off, retry the failed call, and continue. This is a game-changer for AI agent workflows where each step might involve expensive API calls.
Prefect: The Data Engineer’s Darling
Prefect has earned its reputation in the data engineering world for good reason. It provides a clean Python-native API for defining workflows, automatic retries, rich observability, and a beautiful UI. For teams building ETL pipelines, data processing workflows, and ML training pipelines, Prefect is often the natural choice.
But Prefect’s Python-centricity is both its strength and its limitation. In a microservices environment where services might be written in Go, TypeScript, or Ruby, Prefect’s Python-only SDK becomes a constraint. You can still use it as a centralized orchestrator, but you lose the ability to define workflows in the same language as your services.
Prefect also lacks some of the advanced durability features that Temporal and Hatchet offer. While Prefect has retries and state management, it doesn’t have the same level of checkpointing and replay support for long-running workflows. For LLM pipelines that might run for 30 minutes or more, this is a significant limitation.
The Monitoring and Observability Showdown
One area where all three frameworks have invested heavily is observability. The ability to see what your workflows are doing, debug failures, and replay failed tasks is critical for production systems.
Hatchet’s approach to observability is particularly well-integrated. The platform provides a real-time web UI with alerting, monitoring, and logging built in. Every task and state transition is stored in a durable event log, making it available for automatic retries, manual replays, or debugging. The built-in OpenTelemetry collector provides a complete set of traces and spans for every task and workflow execution, and you can forward these to your preferred observability stack.
Temporal’s observability story is also strong, but it requires more setup. You need Elasticsearch for the advanced visibility features, and the Web UI is functional but not as polished as Hatchet’s. Prefect has a beautiful UI and excellent observability for data pipelines, but it’s less suited for the kind of distributed tracing you need in a microservices environment.
The Decision Framework: When to Choose What
After digging through the research and real-world experiences, here’s my framework for choosing between these three:
Choose Temporal when:
– Your workflows are mission-critical and failure is not an option
– You have the operational capacity to manage Temporal Server and its dependencies
– Your workflows are long-running (hours to days) and need to survive process crashes
– You’re building financial systems, healthcare platforms, or other regulated environments
– You have a team that can handle the cognitive overhead of deterministic workflow code
Choose Hatchet when:
– You need durable execution without the Temporal infrastructure tax
– You’re building AI agent pipelines or LLM processing workflows
– You want a managed orchestration engine with workers on your infrastructure
– You need sub-50ms task start latency
– You value simplicity and developer experience over enterprise features
– You want to avoid the Airflow orchestration pain points and integration challenges that plague older systems
Choose Prefect when:
– Your workflows are primarily Python-based data pipelines
– You need rich observability and a beautiful UI out of the box
– You’re building ETL/ELT workflows, ML training pipelines, or data processing systems
– You don’t need cross-language support or tight event-driven integration
The Verdict: It’s About the Shape of Your Work
The choice between Temporal, Hatchet, and Prefect ultimately comes down to the shape of your workflows and the operational capacity of your team.
If you’re building a system where a single failed workflow could cost millions of dollars, Temporal is the right choice. The infrastructure overhead is justified by the guarantees it provides.
If you’re building AI agent pipelines, LLM processing systems, or any workload where durability matters but you don’t want to manage a Temporal cluster, Hatchet is the sweet spot. The 25ms latency, the built-in observability, and the ability to run workers on your infrastructure while using a managed orchestration engine make it the pragmatic choice for most teams.
If you’re building data pipelines in Python and don’t need cross-language support or event-driven integration, Prefect is still a solid choice. Just be aware of its limitations when you start scaling beyond pure data engineering use cases.
“What do people usually do?”, has a nuanced answer. The teams I’ve seen succeed with task orchestration in microservices follow a pattern:
- Use the right tool for the communication pattern. Event-driven communication (Redis streams, Kafka) is for broadcasting events. Request-reply patterns need queues or direct orchestration. Don’t try to force one pattern to do the other’s job.
- Separate orchestration from communication. Your orchestration framework should handle workflow execution, retries, and state management. Your communication layer should handle message passing. Don’t try to make your orchestration framework do both.
- Match the framework to your workflow shape. Long-running, mission-critical workflows need Temporal. AI agent pipelines and parallel workloads need Hatchet. Python data pipelines need Prefect. Trying to use one tool for everything is a recipe for pain.
- Consider the operational cost. Temporal’s infrastructure requirements are real. Hatchet’s managed service eliminates most of that burden. Prefect sits somewhere in between. The total cost of ownership includes not just the software but the team’s time to manage it.
The agent handoffs as billing events in multi-agent workflows pattern is particularly relevant here. When you’re orchestrating AI agents, every handoff between agents is a potential failure point and a billing event. The orchestration framework you choose determines how gracefully those handoffs fail and how much you pay when they do.
The Future: Convergence or Divergence?
The task orchestration landscape is evolving rapidly. Temporal is adding more developer-friendly features. Hatchet is expanding its enterprise capabilities. Prefect is moving beyond pure data pipelines into broader workflow orchestration.
The trend I’m watching is the convergence toward durable execution as a platform primitive. Just as every major cloud provider now offers managed message queues and event buses, I expect durable execution to become a standard infrastructure service. The question is whether it will be provided by dedicated platforms like Temporal and Hatchet, or whether it will be absorbed into existing infrastructure (Kubernetes, serverless platforms, etc.).
For now, the choice between Temporal, Hatchet, and Prefect comes down to a simple question: how much operational complexity are you willing to accept for how much reliability?
If the answer is “as much as it takes”, go with Temporal. If the answer is “as little as possible while still getting durability”, go with Hatchet. If the answer is “I just need my Python data pipelines to work”, go with Prefect.
And if you’re still trying to make Redis streams do request-reply, stop. You’re not doing event-driven architecture. You’re doing async RPC with extra steps and fewer guarantees. The build vs buy trade-offs in data orchestration are real, but sometimes the right answer is to use a tool that was designed for the job you’re actually trying to do.
The Final Word
The task orchestration landscape is maturing, and the choices are getting clearer. Temporal is for the enterprise. Hatchet is for the pragmatic team that needs durability without the overhead. Prefect is for the data engineer who lives in Python.
The journey from Redis streams to Hatchet is a familiar one. The realization that event-driven communication isn’t the right tool for request-reply patterns is a rite of passage for many architects. The good news is that the tools exist to solve this problem. The bad news is that choosing the wrong one can be as painful as not using one at all.
If you’re building LLM pipelines, AI agents, or any system where durability matters but you don’t want to manage a Temporal cluster, give Hatchet a serious look. The 130 million daily tasks and 25ms latency numbers aren’t just marketing, they reflect a platform that’s been built for the specific challenges of modern microservices orchestration.
And if you’re still trying to make Redis streams do request-reply, stop. Your future self will thank you.